真實的數據很少是乾淨的。更常見的情況是,很多有意思的數據集都有很多的數據缺失。更複雜的是,不同的數據源可能有著不同指代缺失數據的方式,我們會將這些缺失數據標示為 null、 NaN 或 NA。
第一個種缺失值是 None,很多情況下它都作為 Python 代碼中缺失值的標誌。None 不能被任意的 NumPy 或Pandas 數組中使用,當使用聚合操作如sum()或min()的時候,如果碰到了None值,那就會產生錯誤:
import numpy as np
vals1 = np.array([1, None, 3, 4])
vals1

另外一個缺失的數據表現形式NaN(非數字的縮寫),NumPy 使用原始的浮點類型來存儲這個數組:這個數組支持使用編譯代碼來進行快速運算。你應該了解到 NaN 就像一個數據的病毒,它會傳染到任何接觸到的數據。不論運算是哪種類型,NaN 參與的算術運算的結果都會是另一個 NaN,請記住NaN是一個特殊的浮點數值,就像是任何數值乘上零都是零。
import numpy as np
vals1 = np.array([1, np.nan, 3, 4])
vals1

Pandas將None和NaN看成是可以互相轉換的缺失值或空值。與此同時,Pandas還提供了一些很有用的方法用來在數據集中發現、移除和替換空值。這些方法包括:
isnull():生成一個布爾遮蓋數組指示缺失值的位置notnull():isnull()相反方法dropna():返回一個過濾掉缺失值、空值的數據集fillna():返回一個數據集的副本,裡面的缺失值、空值使用另外的值來替代isnull() - Detecting null values 檢測空值
data = pd.Series([1, np.nan, 'hello', None])
data.isnull()

notnull() - Detecting null values 檢測空值
data = pd.Series([1, np.nan, 'hello', None])
data[data.notnull()]
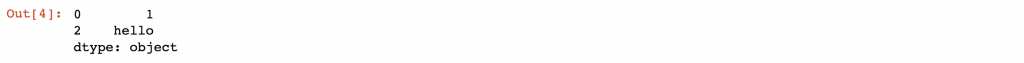
dropna() - Dropping null values 去除空值
data = pd.Series([1, np.nan, 'hello', None])
data.dropna()

isnull() - Filling null values 填充空值
data = pd.Series([1, np.nan, 'hello', None])
data.fillna(0) # fill NA entries with a single value
data.fillna(method='ffill') # 向前填充 forward-fill
data.fillna(method='bfill') # 向後填充 back-fill

今年沒組團,每一筆一字矢志不渝的獻身精神都是為歷史書寫下新頁,有空的話可以走走逛逛我們去年寫的文章。
Jerry 據說是個僅佔人口的 4% 人口的 INFP 理想主義者,總是從最壞的生活中尋找最好的一面,想方設法讓世界更好,內心的火焰和熱情可以光芒四射,畢業後把人生暫停了半年,緩下腳步的同時找了份跨領域工作。偶而散步、愛跟小動物玩耍。曾立過很多志,最近是希望當一個有夢想的人。
謝謝你的時間「訂閱,追蹤和留言」都是陪伴我走過 30 天鐵人賽的精神糧食。

