K近鄰(K Nearest Neighbors),簡稱KNN,為一種監督式學習的分類演算法,其觀念為根據資料點彼此之間的距離來進行分類,距離哪一種類別最近則該資料點就會被分到哪類。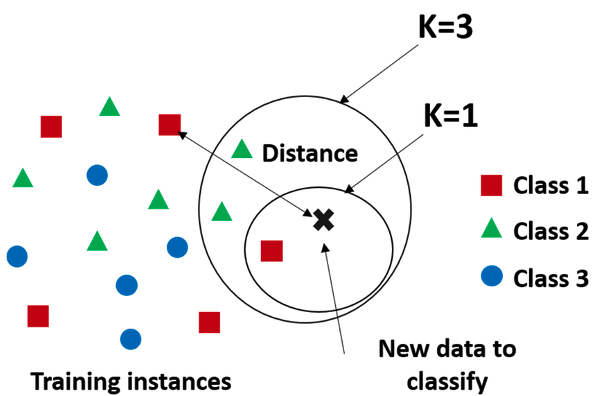
圖片來源:連結
根據例圖,KNN演算法的預測過程如下:
當輸入一筆資料x,則模型會在訓練資料集中尋找k個相近的資料點,並將x的類別預測為k個樣本中數量最多的那個類別。如圖中,若k=1時,x點距離最近的為class 1 (紅色方形),因此在在k=1時會被歸類為class 1;當k=3時,則可看到距離最近的三個資料點類別為一個class1和兩個class 2,因此k=3時,x則會被歸類為class 2 (綠色三角形)。
總結KNN的演算法步驟如下:
設定k值,亦即會在計算時找出距離x資料中最近的k筆資料,距離計算方式如下幾種:
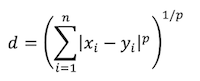
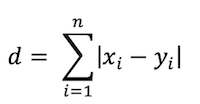
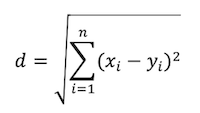
*註:為避免投票時出現等票的情形,因此在選擇k時,通常不會選擇偶數;若k值越大,可能會導致納入過多不相關的樣本點,但k值越小較容易受到噪音的影響,因此通常建議k值須小於樣本數的平方根較好。而k值的決定可以透過交叉驗證來找到合適的k值以及恰當的距離計算方式。
優點:
缺點:
由於資料集中13種不同的活動之資料量具有差異,其中以activity = 0的資料量過大,因此為了減少資料不平衡的問題,將activity=0的紀錄量減小(取每位受試者總長3072個時間點的序列)。
dataset2 <- read.csv('mhealth_raw_data.csv')
new_dataset2 <- dataset2[which(dataset2$Activity != 0),]
### 減少activity0的資料量,每位受試者挑選相同長度的時間段
for(people in 1:10){
index <- which(dataset2$Activity == 0 & dataset2$subject == paste0('subject',people))
sample_start <- sample(index[1:(length(index)-4000)],1) ## 避免有時間序列不夠長的問題
select_index <- c(sample_start:(sample_start+3071))
new_dataset2 <- rbind(new_dataset2,dataset2[select_index,])
}
import numpy as np
import pandas as pd
dataset2 = pd.read_csv('./mhealth_raw_data.csv')
choose_index = [i for i,val in enumerate(dataset2['Activity']) if val != 0]
new_dataset2 = dataset2.iloc[choose_index,:]
for people in range(1,11):
index = dataset2.index[(dataset2.Activity == 0) & (dataset2.subject == 'subject'+str(people))]
index = list(index[0:(len(index)-4000)]) ## 避免有時間序列不夠長的問題
sample_start = random.sample(index, 1)
select_index = range(sample_start[0],(sample_start[0]+3071))
new_dataset2 = pd.concat([new_dataset2, dataset2.iloc[select_index,:]])
library(caret)
set.seed(12345)
new_dataset2 <- new_dataset2[,-14]
training_idx <- sample(1:length(new_dataset2$Activity),length(new_dataset2$Activity)*0.7)
training <- new_dataset2[training_idx,]
training_norm <- preProcess(training[,c(1:12)], method=c("range"))
training[,c(1:12)] <- predict(training_norm, training[,c(1:12)])
testing <- new_dataset2[-training_idx,]
testing_norm <- preProcess(testing[,c(1:12)], method=c("range"))
testing[,c(1:12)] <- predict(testing_norm, testing[,c(1:12)])
}
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
X = new_dataset2.iloc[:,range(0,12)]
Y = new_dataset2['Activity']
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.3, random_state=12345)
X_train.shape, Y_train.shape # ((851021, 12), (851021,))
X_test.shape, Y_test.shape # ((364724, 12), (364724, 1))
scaler = MinMaxScaler().fit(X_train)
X_train = scaler.transform(X_train)
scaler = MinMaxScaler().fit(X_test)
X_test = scaler.transform(X_test)
先建立一個較為簡單的模型(K先設為定值)
class套件中的knnlibrary(class)
pred_knn <- knn(train = training[,1:12], test = testing[,1:12], cl = training$Activity, k = 10)
# 驗證結果
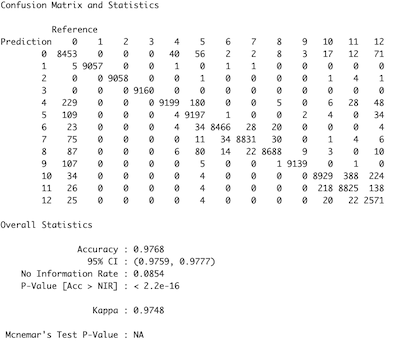
confusionMatrix(pred_knn,reference = as.factor(testing$Activity))
sklearn.neighbors套件中的KNeighborsClassifier# 建立模型
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train, Y_train)
knn_pred = knn.predict(X_test)
# 驗證結果
from sklearn.metrics import accuracy_score, recall_score, confusion_matrix
accuracy_score(Y_test, knn_pred) # 0.975
confusion_matrix(Y_test, knn_pred)
train_control <- trainControl(method="repeatedcv",repeats = 3)
model <- train(Activity ~., data = training,
method = "knn",
trControl = train_control,tuneLength = 20)
print(model)
from sklearn.model_selection import cross_val_score
k_range = range(2,15)
k_scores = []
for k in range(2,15):
knn_model = KNeighborsClassifier(n_neighbors = k)
accuracy = cross_val_score(knn_model, X_train, Y_train, cv=10, scoring="accuracy")
print("K="+ str(k) +" Accuracy= "+ str(accuracy.mean()))
k_scores.append(accuracy.mean())
print("Best K: " ,k_scores.index(max(k_scores))+2)
# 可知表現較好的時候,K=3,因此建立模型時可使用K=3作為最終模型
## Visualization
import matplotlib.pyplot as plt
plt.plot(k_value_range,k_value_scores, marker = 'o')
plt.title('Best K:')
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.show()




 iThome鐵人賽
iThome鐵人賽