決策樹可分為處理迴歸問題的迴歸樹(Regression Tree)、處理類別問題的分類樹(Classification tree)、可同時處理兩種類型問題的分類與迴歸樹(Classification And Regression Trees, CART)、Chi-Square Automatic Interaction Detector
(CHAID)。
決策樹模型的長相為一顆樹,有樹根(root node)及枝葉(leaf node),結點(node)的部分為一個特徵,整個樹包含了模型整體的決策流程,在每一個節點皆有一個判斷條件,引導模型做出預測。
為了找出最合適的決策樹模型,避免納入過多無用的特徵,以提高決策樹學習的效率,因此會使用熵(Entropy)、資料純度作為標準來建構出決策樹。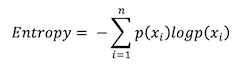
n:類別數,-log_2p(x_i ):資訊值,p(x_i ):選擇該類別的機率
當Entropy越大,代表所含有的資訊量越大,資料越雜亂,資料純度越低;當Entropy越小,代表所含有的資訊量越小,資料越一致,資料純度越高
衡量資料純度的方法有三種:
優點
缺點
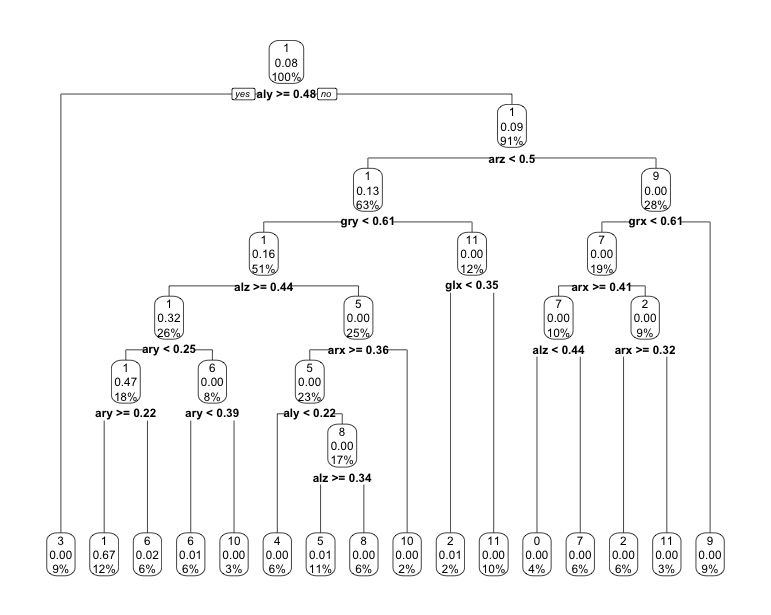
rpart套件中的rpartlibrary(rpart)
library(rpart.plot)
# 建立分類器
model_tree <- rpart(Activity~., data = training, method = 'class')
# 預測
pred_tree <- predict(model_tree, testing, type = 'class')
# 衡量
confusionMatrix(pred_tree,reference = as.factor(testing$Activity))
# 視覺化
rpart.plot(model_tree)
sklearn.tree套件中的DecisionTreeClassifier()from sklearn import tree
from sklearn import metrics
# 建立分類器
dtree = tree.DecisionTreeClassifier()
model_tree = dtree.fit(X_train, Y_train)
# 預測
pred_tree = model_tree.predict(X_test)
# 衡量
accuracy = metrics.accuracy_score(pred_tree,Y_test)
print(accuracy) # 0.9529
# 視覺化
class_names = new_dataset2['Activity'].unique().tolist()
class_names = list(map(str, class_names)
fig = plt.figure(figsize=(25,20))
_ = tree.plot_tree(model_tree,
feature_names=new_dataset2.columns[:12],
class_names= class_names,
filled=True)


 iThome鐵人賽
iThome鐵人賽