
今天講講當你在訓練模型時會設定到的參數-訓練週期(epoch) 與 批次(batch) -他們的意義跟相關問題。這篇內容主要分成以下四點:
epoch:訓練資料集裡所有資料一次叫一個 epoch,中文翻訓練週期。batch:把資料分成一組或一堆分批放到模型訓練,中文翻批次。
batch size:一組資料的大小,keras 中若未設定,預設是batch_size=32
假設我現在手上有 1000 筆資料,現在我想要分成 10 筆資料為一組(一個batch,batch size=10),計算它們的 loss 來更新模型參數,那這樣我跑完所有資料一輪(一個epoch) 需要 100 次(iteration)。
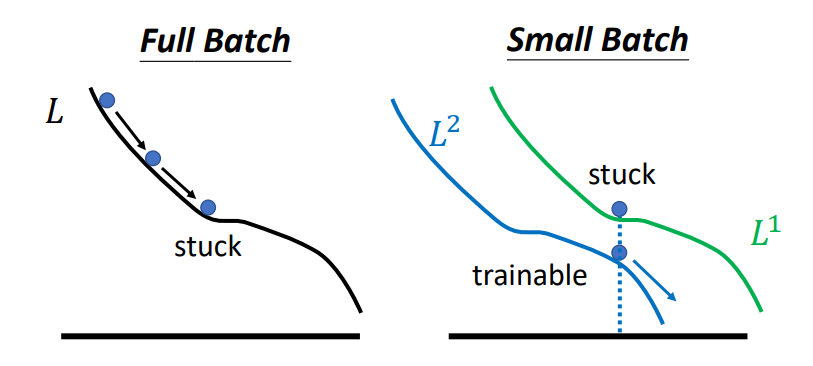
我們設定 batch 的目的是想算出一部份資料的 loss/gradient 就去更新模型參數,不用每次都拿全部資料來算 loss/gradient,因為資料集小這樣做ok,但如果資料集大有上百萬千萬筆資料時,這樣做可能會因「梯度競爭」[註1]互相干擾抵銷修正的方向,而遇到走不下去的點被卡住。
在 Keras 實作上,我們可以額外設定 shuffle=True,讓模型每跑完一個 epoch 後就重新去分不同 batch (shuffle after each batch)。
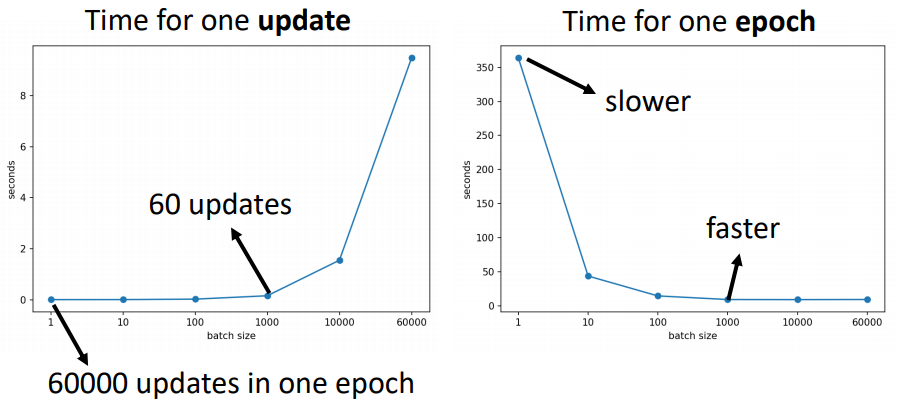
會,不過要看你看的角度。如果從上圖[註2]左邊一次參數更新需要的時間來看,batch size 越小,參數更新時間就越短。但batch size 越小,它在一個 epoch 中要更新的次數越多,所以對一個 epoch 來說(上圖右),batch size 越小,花的時間就越久。
會,通常小 batch 的效果會有比較好的準確率,因為當 batch size 越大,越有可能遇到走不下去的點[註2]。
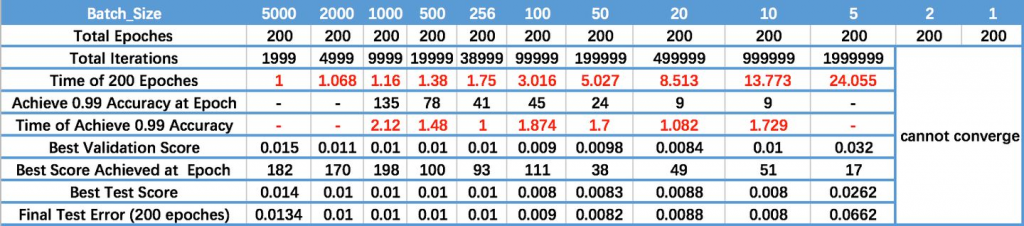
然而小 batch size 也有缺點,這邊有一張別人用不同 batch size 跑手寫數字辨識資料集 MNIST 的結果(圖片來源),我們可以看到 batch size 太小,它在 200 epochs內不收斂。
在訓練時我們會遇到「要訓練幾次 epoch呢?」或「batch size 要設多少比較好?」等問題,這些都是好問題但沒有標準答案,因為這跟我們正在處理的資料大小、學習速率[註3]有關。不過通常我們會將 batch size 會設成 2 的次方(電腦處理本質0/1?),以及 batch size 常見的設定範圍會介在 10~1000 間。
用 Keras 疊一個神經網路需要先知道的幾個名詞 第4天(/6 days) 完成。
[註1] 梯度競爭(gradient competition)一詞來自 Effect of batch size on training dynamics 一文,作者用比較視覺化的「梯度競爭假設」假設說明為什麼batch size 比較大會有比較低的正確率,覺得這個用法很形象所以用在這邊說明。
[註2] 李宏毅老師的機器學習課程(2021)
[註3] batch size 跟 learing rate 是有關係的,一般來說 batch size 越大,learning rate 也要相對變大,跟 gradient 有關,大家有興趣可以查查~
