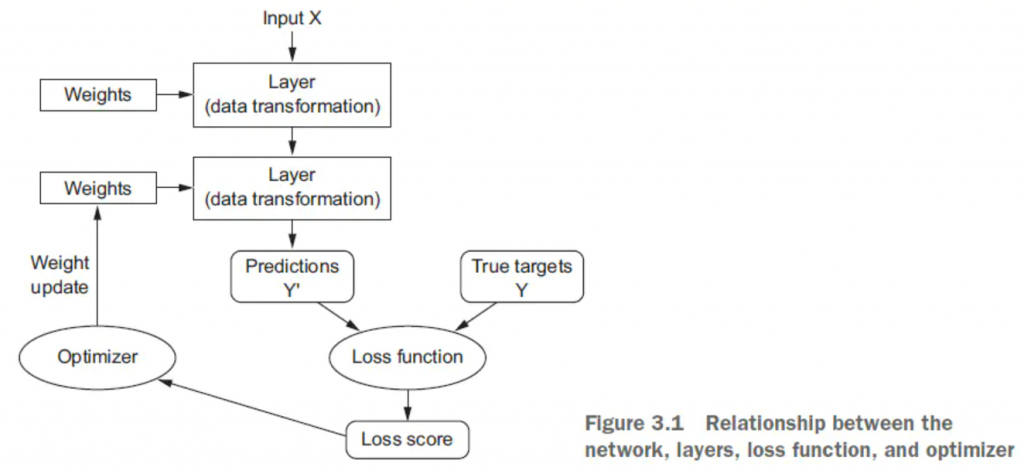
圖片來源:凤凰花开那一天所分享的Python深度学习(三)神经网络入门(原圖出處:Deep Learning 深度學習必讀:keras 大神帶你用 python 實作)
昨天我們介紹了損失函數(loss function),知道它是用來評估 model 好壞的指標,誤差越小越與我們期望的目標(object function)越近。
今天要介紹的是優化器(optimizer),它會根據損失函數值去更新神經網路(如上圖),在這邊你會聽到梯度下降演算法(Gradient Descent)這個調整權重找損失函數的最小值的方法,倒傳遞學習法(Back propagation)這種求解梯度的形式,以及學習速率(Learning Rate)這種去設定學習步伐大小的詞。
而由於這部分的內容從證明到應用應該可以另外再講 30 天(x),所以今天介紹的重點在簡單了解這些詞的概念,以及了解幾個使用 Keras 套件建一個神經網路模型時,常用的優化器選擇。
這是調整權重,找損失函數最小值的方法,公式如下:
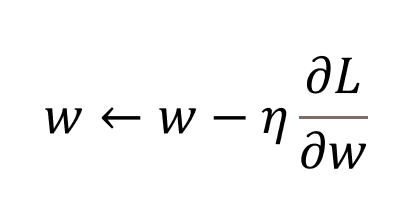
而為什麼是減不是加梯度調整?微分在幾何意義上就是在找切線斜率[註1],若現在斜率是正的,但我們的目標是斜率 0 (最低點,local min)時,我們就要減去它,反之亦然。
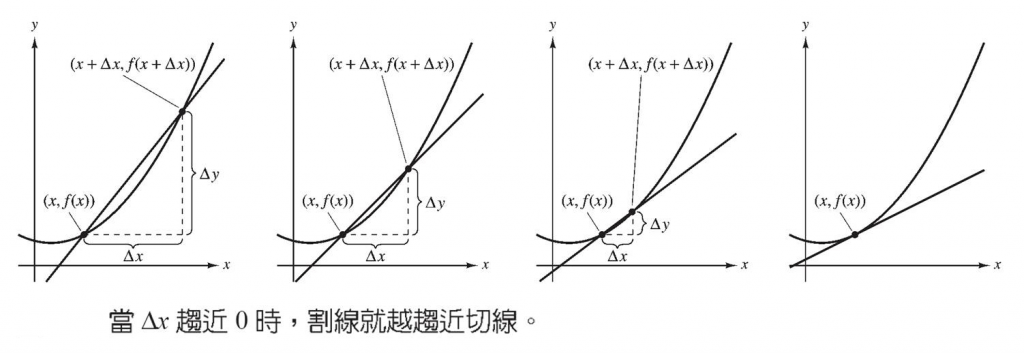
圖片來源:統雄-微積分神掌易筋經1
有效率把 Gradient Descent 解出來的方法,其實就是反著用 chain rule 修改 Gradient Descent,所以又可稱為反向傳播算法。
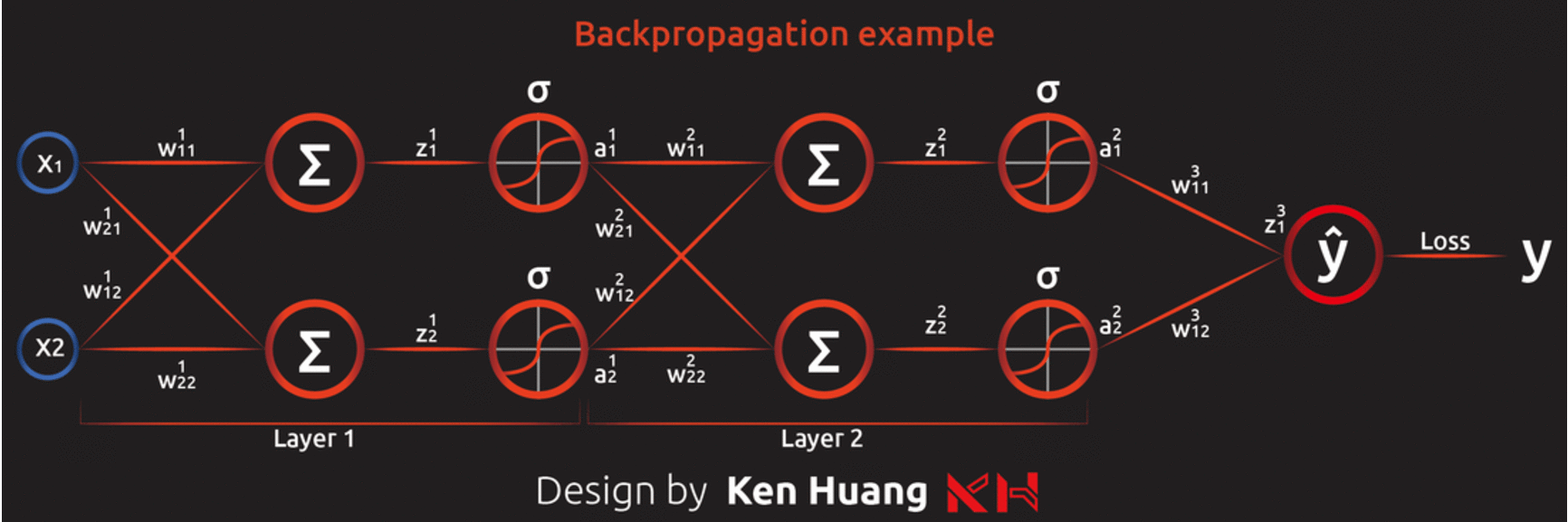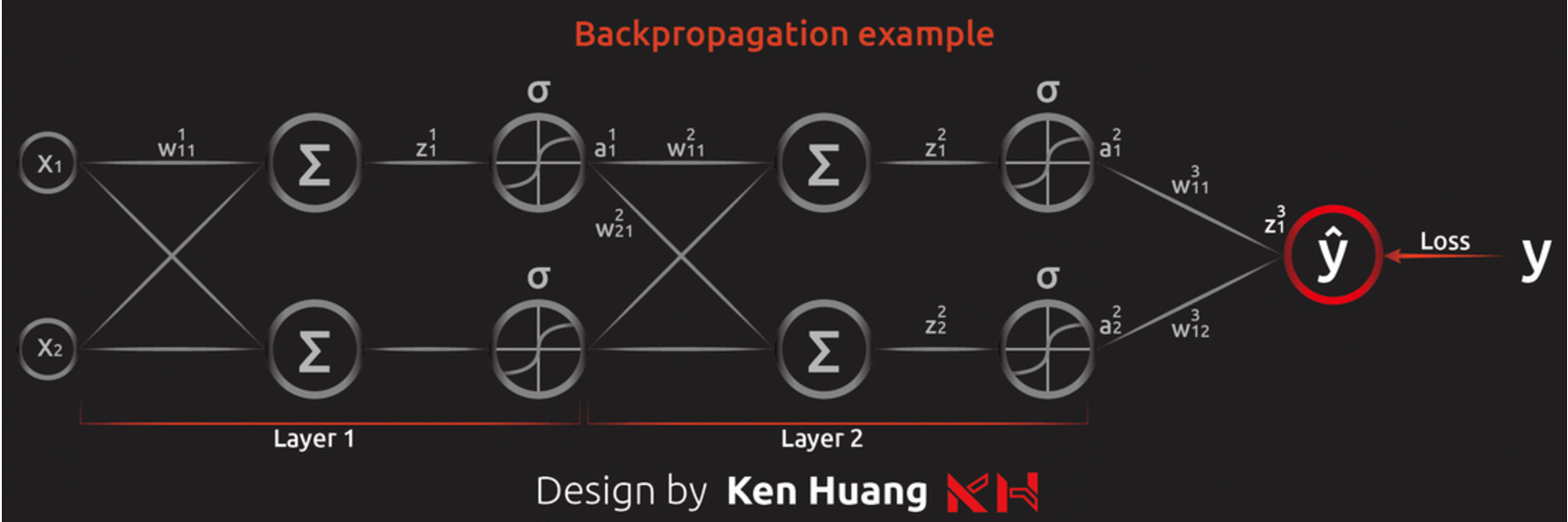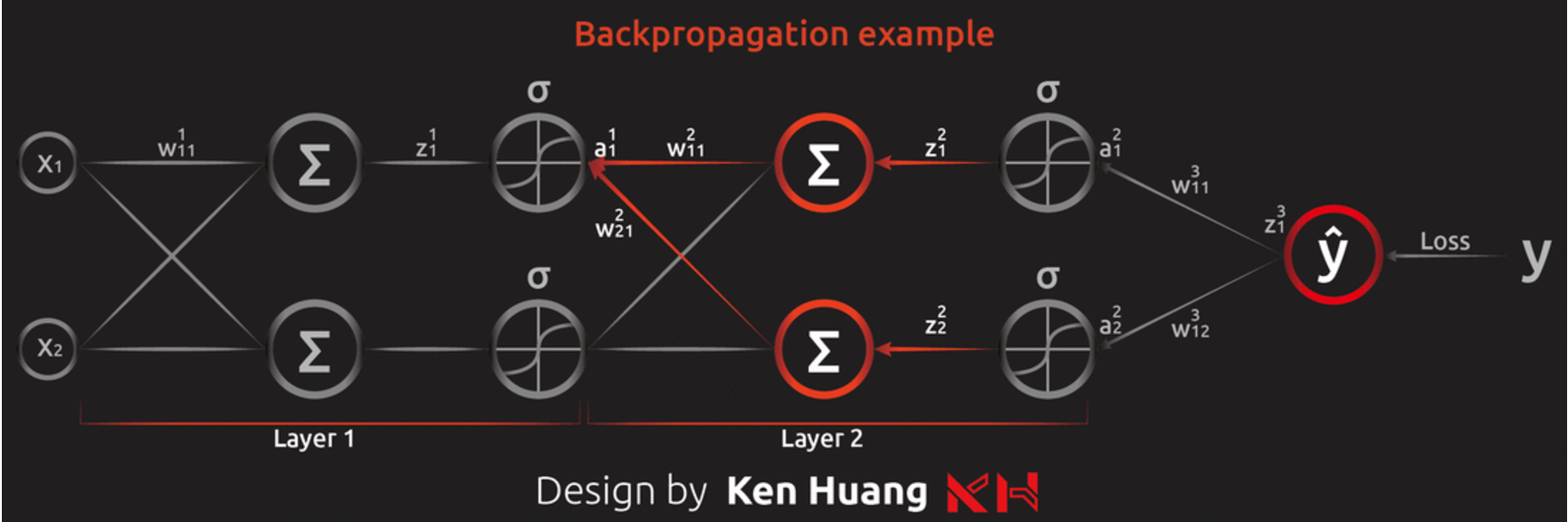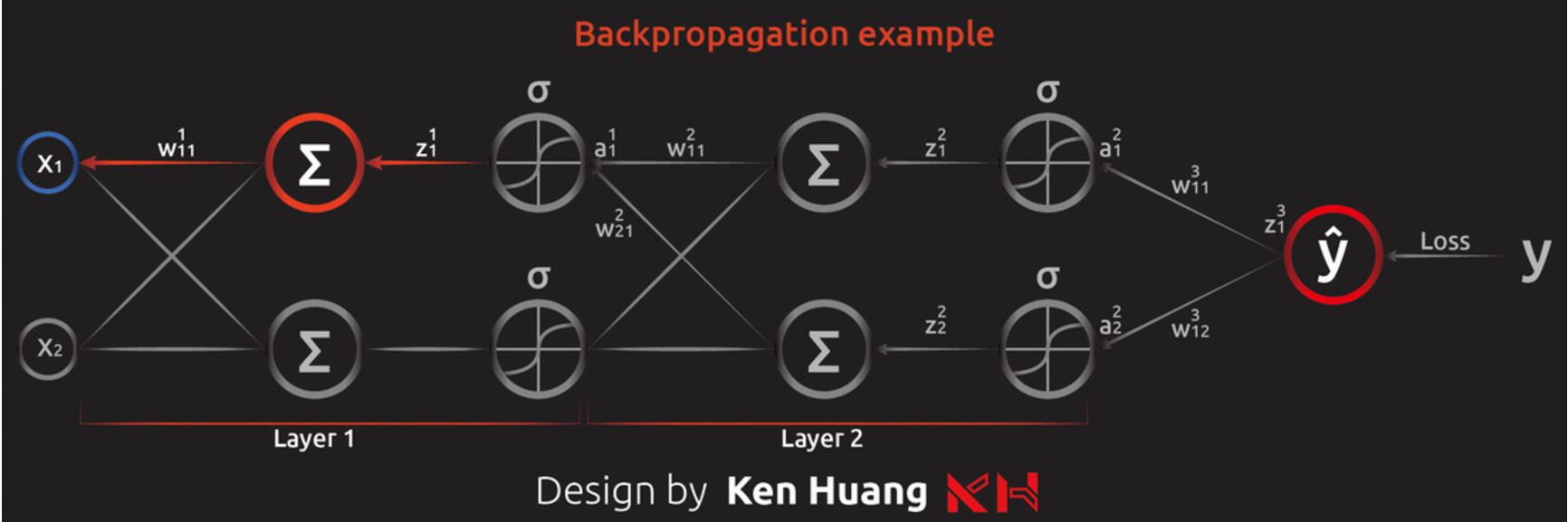
圖片來源:Ken Huang 的反向傳播算法( Backpropagation Algorithm )
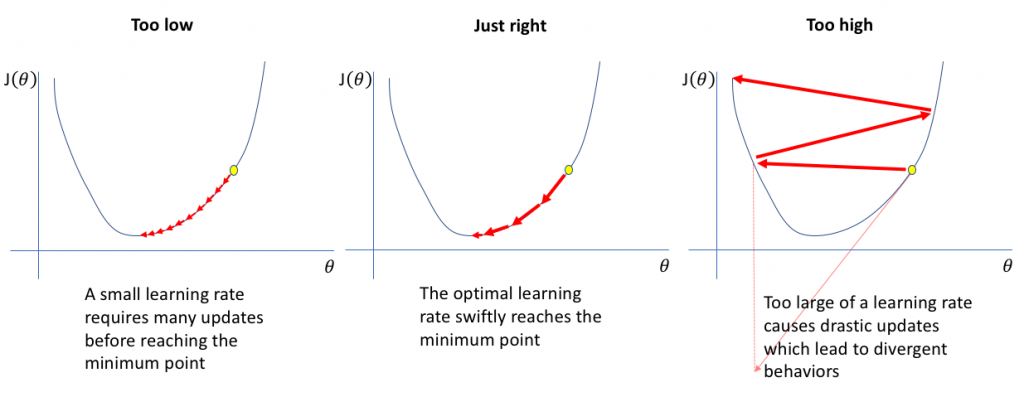
圖片來源:Statistics and Machine Learning in Python
如果我們現在想要收斂到區域最小值(local min),學習速率慢需要更新很多次權重才能找到,而學習速率快可能會跳過我們的目標,所以我們會根據情況找最適合的學習速率。
先放兩張選擇不同優化器來達到 local min 的實作情形圖。
圖片來源:An overview of gradient descent optimization algorithms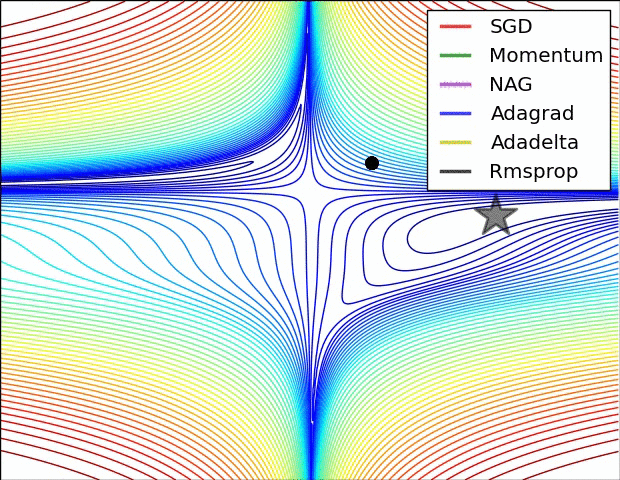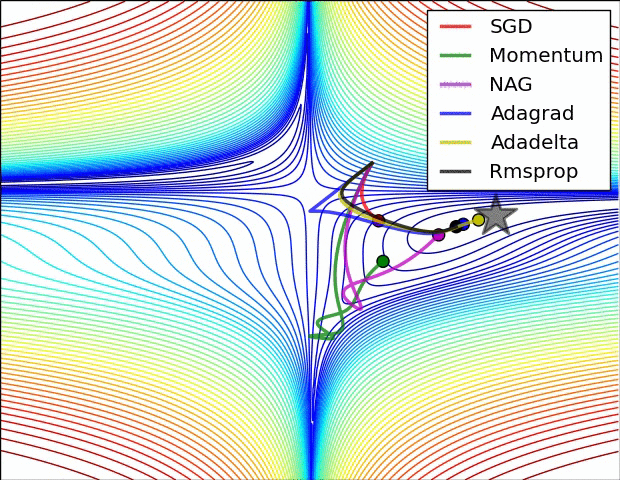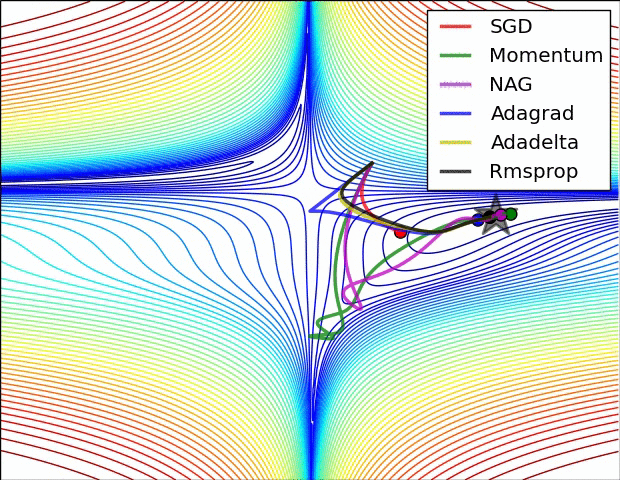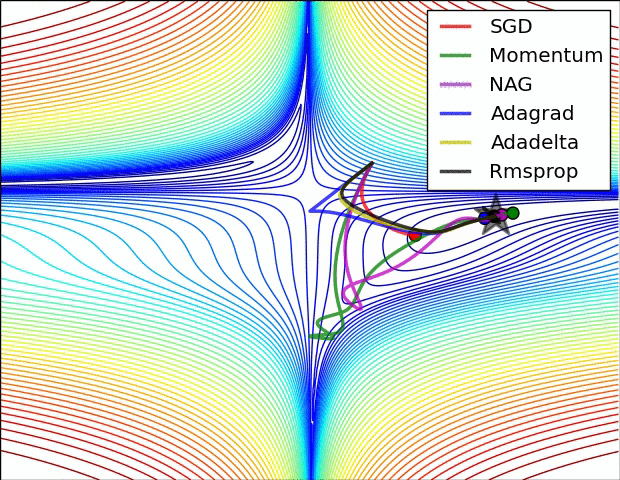
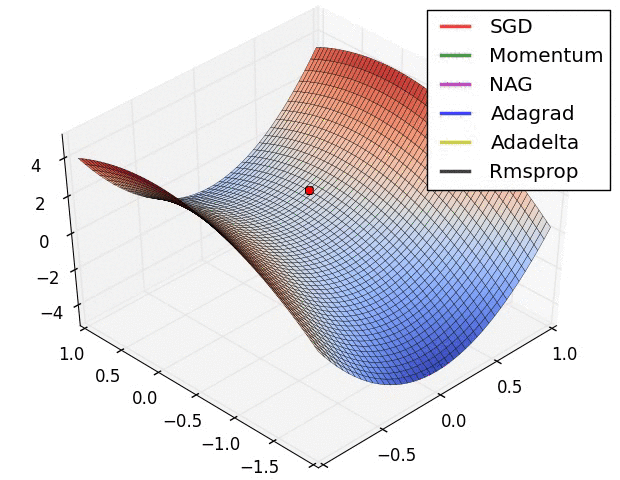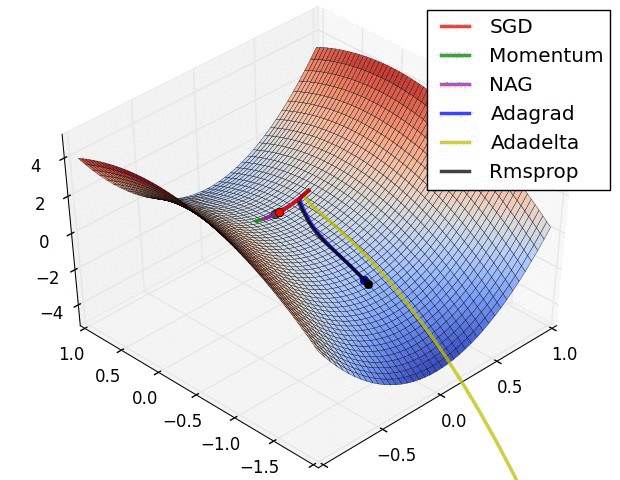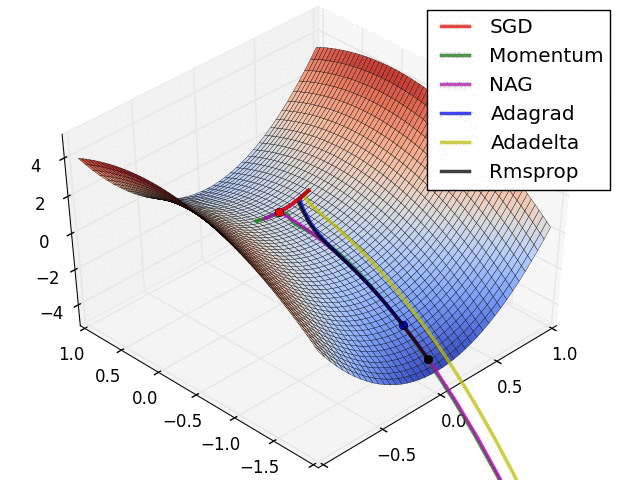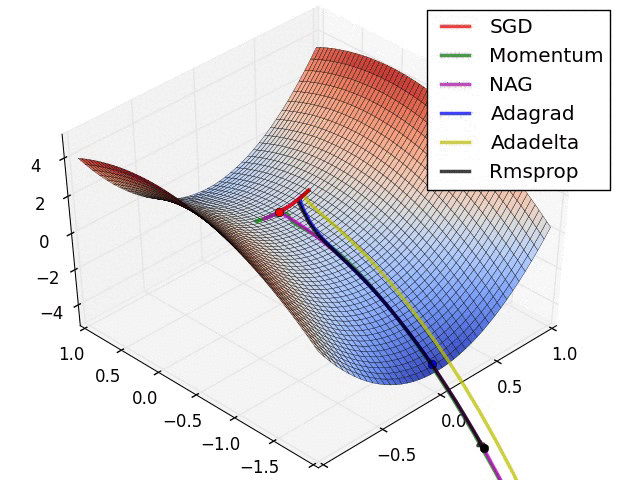
進入正題,使用 Keras 套件建一個神經網路模型時,我們常用的優化器有:
SGD(Stochastic gradient descent): 隨機梯度下降法,基本上就是 gradient descent。跟 GD 差別在,SGD是隨機取樣一個樣本或 mini-batch ,計算它的 Loss 就去更新權重參數,而 GD 是一次計算出所有資料的 Loss 才去更新一次權重參數。
Momentum:模擬物理動量的概念找到最低點。
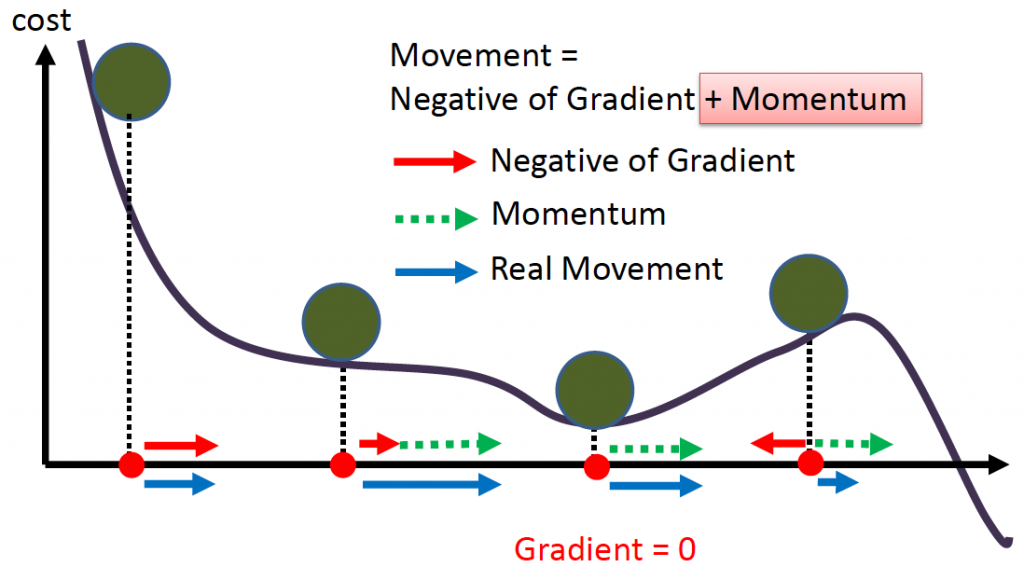
圖片來源:李宏毅老師機器學習課程
Adagrad :學習速率不是固定值,而是動態調整的(Adaptive)。RMSprop: 從 Adagrad 延伸出的,訓練 RNN 使用是一個不錯的選擇。Adam: 本質上是 RMSprop 跟 Momentum 的結合,是目前最常使用。如果想要調整各優化器裡面的細節,可以看 keras官方文件。
用 Keras 疊一個神經網路需要先知道的幾個名詞 第3天(/6 days) 完成,大家明天見!
[註1] 這個描述不大精準,詳細請查導數、導函數意義
[註2] 推薦延伸閱讀的文章:
1.機器/深度學習-基礎數學(三):梯度最佳解相關算法(gradient descent optimization algorithms) -> 裡面很多 gif 圖實例
2.[機器學習ML NOTE]SGD, Momentum, AdaGrad, Adam Optimizer -> 有相關程式碼,用 colab 展示如下(未調整程式碼,僅將現行的tensorflow2.0版本改成適合其程式碼的1.0版本)

