
這Gif檔是一隻鱷魚工程師在做性能測試的動畫
看它鍵盤敲敲打打, 螢幕上就能跑出數據跟圖表, 最後還有個綠燈的大勾勾.
它在操作的就是Grafana Labs底下的產品K6.
測試的結果呈現也確實能像動畫一樣,
給出Summary的報表以及Time-Series形式的數據呈現.

上圖是K6的Icon是不是也很像時序型的趨勢圖呢?
2016年8月, 最早由Load Impact公司於Github上發布了第一個版本的K6, 但當當時叫做Speedboat.
2020年2月, 改名成K6, 且推出了K6 Cloud這Sass服務Blog文章連結
每個月使用人數的增長
2021年6月, Grafana Labs收購了K6.Blog文章連結
| 鱷魚圖片 | 適用人員 | 描述 |
|---|---|---|
 |
開發人員與SDET | 方便我們透過K6提供的api以及CLI工具來使用開發; 且我們開發人員對Javascript也不太陌生, 能用Javascript來開發模擬真實場景的測試 |
 |
DevOps和SRE | 這兩個職位都是偏運維方面的. 我們能把上面SDET開發的script拿來進行自動化地壓力測試, 卻我們的基礎建設與應用服務都還是保持著高性能的表現. 在K6開發的script內, 設定SLO, 來測試服務的運行狀況是否達標. |
 |
QA | 更方便的寫測試案例與腳本, 跑起來也很快; 還能跟Postman, Swagger等整合, 對QA來說是很方便的 |
我們能透過k6/httplibrary來進行,
HTTP API的調用與取得結果
進行Cookie的存取
進行GraphQL的調用
透過k6/ws進行WebSocket的測試,
透過k6/net/grpc來進行gRPC的調用與測試.
透過k6能夠
提供斷言驗證狀態, 這裡是稱為Check驗證條件
check(res, {
'is status 200': (r) => r.status === 200,
});
也能設置Thresholds門閥值
像是設定http_req_duration, 在大量的請求下, p(95)該小於多少時長, p(99)該小於多少時長
請求失敗的比例小於多少
export let options = {
thresholds: {
http_req_failed: ['rate<0.01']
http_req_duration: ['p(95)<500', 'p(99)<1500']
}
};
透過k6/metrics
能自己定義Metric指標
import { Trend } from 'k6/metrics';
const myTrend = new Trend('waiting_time');
export default function () {
const r = http.get('https://httpbin.test.k6.io');
myTrend.add(r.timings.waiting);
console.log(myTrend.name); // waiting_time
}

K6能不只跟CI/CD tool整合, 也能跟很多儀表板, 或者IDE做整合.
開發團隊還在持續地與更多工具做整合.
不管你要做測試左移, 在本機(IDE, Husky...)還是CI前, 甚至CI時
或者測試右移(回歸測試, 可用性測試, 性能監控...)的
K6都能整合近產品的開發生命週期內.
應該大家常常在SRE相關書籍上看到SLO與SLI吧?
SLI 服務水準指標
一個量化指標, 用來衡量服務的使用情況
也能說針對服務的健康狀況或者性能做衡量
這指標通常是從客戶的觀點來定義與測量
也能從之前常提到的Metrics data來觀察分析跟定義.
比如說,
Latency : 請求延遲時間要小於300ms
SuccessRate : HTTP status為200的次數, 與總請求次數的比例
Throughput : HTTP請求的吞吐量
Error Rate
Freshness : 這講的通常是讀寫分離或cluster造成的資料不一致的延遲時長, 像是user送出訂單後, 要多久或刷新幾次頁面才能看到最新的結果
SLO 服務水準目標
當我們定義出SLI之後, 就能把它拿來跟時間做掛勾
期望一段時間內能達到怎樣的狀態, 或者目標(最常見是百分比)
從客戶的觀點來定義, 能思考SLO的時間範圍, 是要5mins, 還是24hr, 甚至更久.
像是
一天內, 95%的讀取請求都能在1秒內回應
一天內, 95%的新增與更新請求都能在3秒內回應
一天內, 99%的請求在5秒內回應的, 都沒有fail.
在系統peak hour期間, 不到1%的請求發生fail
也能從access log等的metrics data來分析
Requests: 123,456
Successful requests: 123,204
90th percentile latency: 497 ms
95th percentile latency: 870 ms
99th percentile latency: 1,024 ms
我們就能來評估SLI該定義哪些量化指標
Availability = (123,204 / 123,456) = 99.8 percent
Latency = at least 90 percent of the requests were served within 500 ms
Latency = about 98 percent of the requests were served within 1000 ms
然後加上時間跟目標
一週內, 90%的請求都低於500ms
99%的請求, 都是成功的
微軟有給一張關聯圖, 演示Metrics data -> SLI -> SLO的定義過程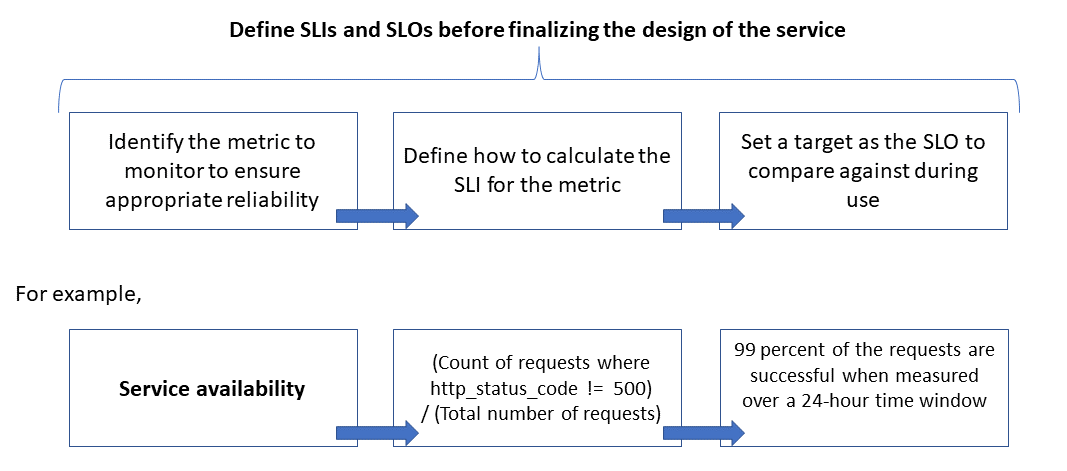
為什麼要談到這個?
是因為K6能夠提供Virual User(Vu) 以及Duration(測試時間長度)
能讓我們在程式內定義好SLI與SLO
搭配執行的Duration, 就能跟時間掛勾
又能透過VU知道很多User請求時的性能表現與模擬實際場景.
此外, 設計架構時,
也需要思考近來的是系統容量設計
常見的指標有TPS, QPS, 併發數
K6是個非常棒的Performance testing工具, 也能針對上面需要設計的指標來提供數據評估
進而做Load testing.
Azure SRE工程裡也提出類似的概念
Design for scale and performance.
Ensure that you capture scale requirements for every user scenario and workload, including seasonality and peaks.
Conduct performance modeling to identify system constraints and bottlenecks
Manage technical debt.
Do extensive tracing of performance metrics.
Consider using scripts to run tools such as K6.io, Karate, and JMeter on your development staging environment with a range of user loads—50 to 100 RPS, for example. This will provide information in the logs for detecting design and implementation issues.
Integrate the automated test scripts as part of your continuous deployment (CD) processes to detect build breaks.
參考自Azure Scalable cloud applications and site reliability engineering (SRE)
其實今日只想輕鬆聊:)
明天再來寫扣+K6
K6其實跟很多壓測工具老前輩(JMeter, Locust, Gatling...)等等的比較算是很新的產品.
但是K6這工具與團隊能在短時間內使用人數快速成長, 在市場能見度越來越高
很大原因是因為它們開源, 使用JS作為客戶端的語言, 便於學習使用, 且持續地進行很多整合.
K6在測試時比較著重在Metrics data的部份, 但也是可以透過Loki紀錄Log, Tempo紀錄Trace.
這樣在測試過程中或是事後分析, 方便把三者結合起來, 找到問題或者可以優化的部份.
Scalable cloud applications and site reliability engineering (SRE)
SRE Book Ch4-Service Level Objectives
IsItObservable.io - What is K6 & How to get started with k6
"開源" 眼睛為之一亮,
我也希望可以少一些顧問時間,多一些研發跟工程師時間~~~
不希望是占用下班時間兼任研發工作啊~~~~
XDDD 我也想, 能造福回開發者身上真的讚
真的

