昨天稍微一起看了
還剩下這麼多, 哭阿
沒關係, 一天看一點, 十年後會看完的(?
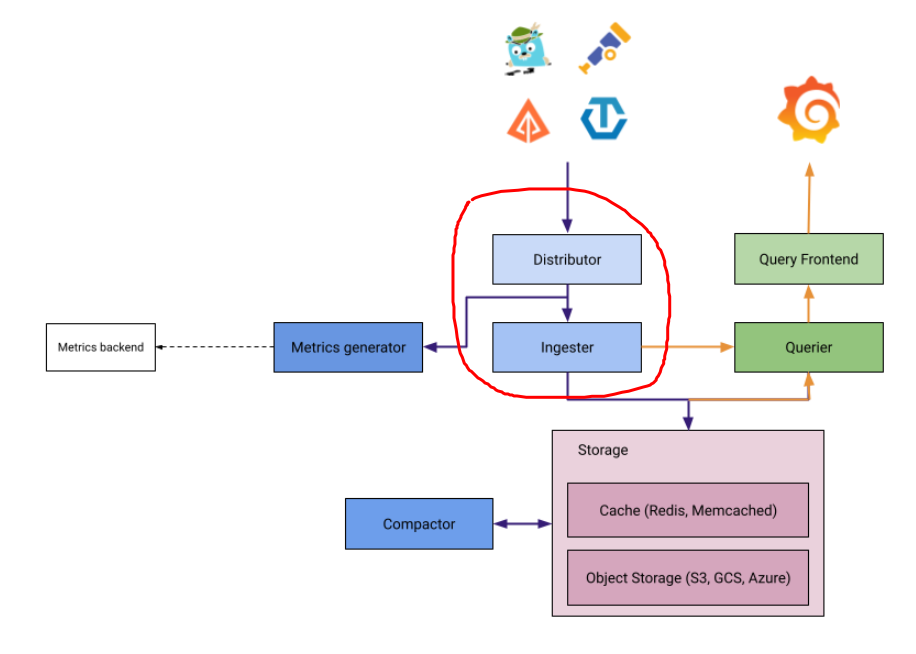
Distributor跟Ingester, 兩個組件是麻吉. 通常一起出來,
只是我們Demo, 沒特別把上圖的每個做成獨立服務去佈署.
其實正常每個組件間都透過gRPC/Http來溝通的.
Distributor用來接收Span, 並且轉發給適當的Ingester
而Ingester呢? 負責批量地把trace, 給推送到對應的Storage.
知道其功用後, 在來看配置設定的部份
第一段receivers, 用來配置哪種協議跟對應的port開啟來收trace data; 生產環境上, 應該只設定你需要的出來就好!
第二段log_received_spans, 用來debug記下span資料後, 跟ingester作對照用的; 因為兩個節點在生產環境下通常是獨立佈署的, 難免有些問題(可能網路或其他因素造成), 是建議別enable, 除非你鈔能力等級很高.
第三段extend_writes, 因為ingester可以是多個節點, 總是有可能有ingester節點會失效的. 就能搭配這設定停止往inative ingesters去做傳遞的動作; 需要搭配ingester的ingester.lifecycler.unregister_on_shutdown = true
第四段就搜尋用的search_tags_deny_list, 字面上清楚明白, 型態是YAML的list of string;
就長
search_tags_deny_list:
- 帥哥
- 美女
# Distributor config block
distributor:
receivers:
otlp:
protocols:
grpc:
http:
jaeger:
protocols:
thrift_http:
grpc:
thrift_binary:
thrift_compact:
zipkin:
opencensus:
kafka:
log_received_spans:
[enabled: <boolean> | default = false]
[include_all_attributes: <boolean> | default = false]
[filter_by_status_error: <boolean> | default = false]
[extend_writes: <bool>]
[search_tags_deny_list: <list of string> | default = ]
第一段lifecycler.ring.replication_factor, 這是定義每個span, 要抄寫給幾份backend做副本;
第二段trace_idle_period是設定一個trace, 多久沒收到span後, 就任定能刷新到WAL內, 預設是10s
第三段flush_check_period掃描所有租戶的, 是否有資料變成被堵塞住, 需要強制執行flush to WAL, 預設是10s.
第四段max_block_bytes, 這個以後講到存儲時才好了解, 就是一個block如果超過這設定時, 則將它一部分資料切掉存到下一個block, 這個區塊則留一些空間做指到下一個block; 預設1GB
第五段max_block_duration, 跟剛剛的相反, 剛剛是容量達上限, 這個是block被建立出來多久後, 不管大小, 也會進行切割創建新的block; 預設1hour.
第六段complete_block_timeout, trace資料被flush之後, 該block該保存多久在ingester內; 這裡預設是15m; 所以有時近期的trace能在這快速找到.
ingester:
lifecycler:
ring:
replication_factor: 3
[trace_idle_period: <duration>]
[flush_check_period: <duration>]
[max_block_bytes: <int>]
[max_block_duration: <duration>]
[ complete_block_timeout: <duration>]
依然學一套, 在Loki也通用
如果說Mimir也通用, 484就CP值特高了:)

