昨天稍微一起看了

目前Tempo有提供的storage backend有以下"gcs", "s3", "azure" or "local"
每個backend都有自己的配置(都一樣才怪)
也能配置"Memcached"與"Redis"來當Cache, 做加速查詢用.
下圖是WAL與block還有租戶的關係,
資料近來會先寫到WAL, 在根據租戶寫到不同租戶的資料夾內, 在寫到block內.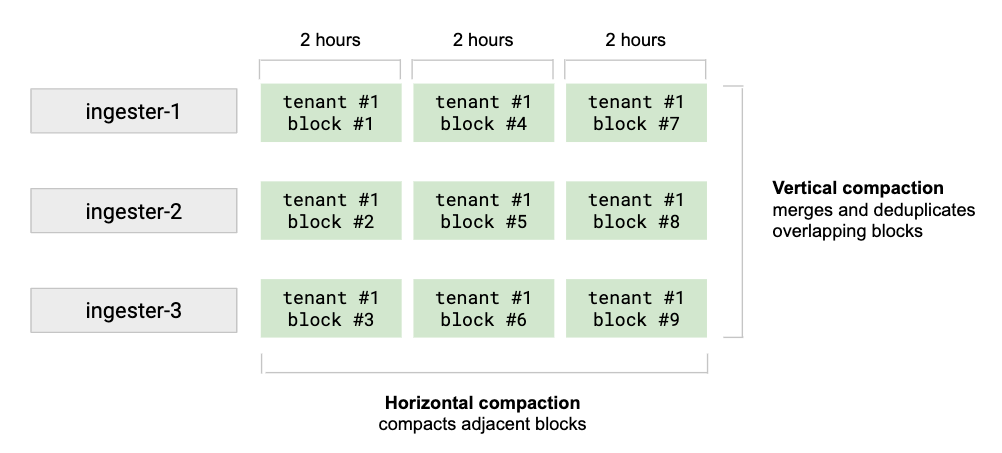
只是我這裡只有單一租戶, 所以只有一個single-tenant資料夾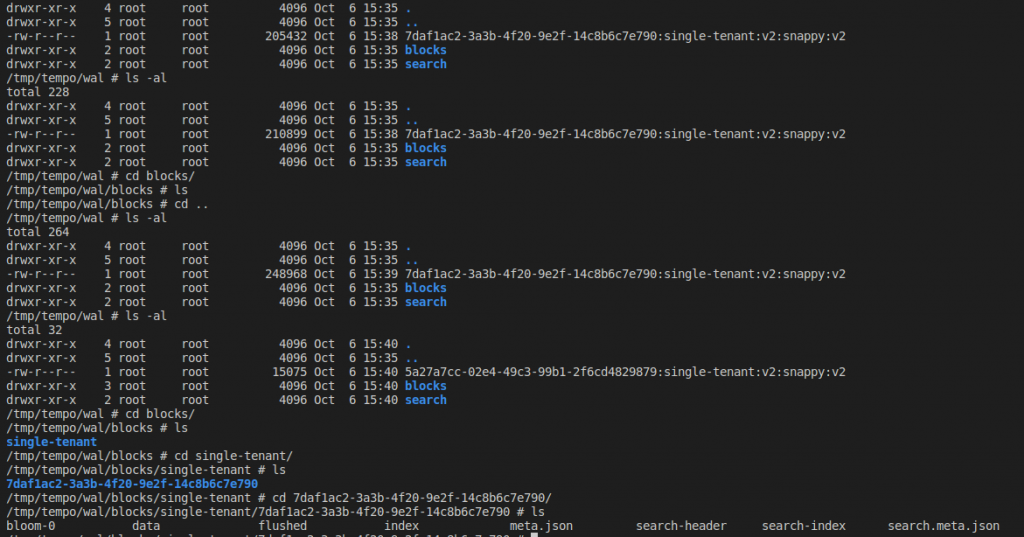
先講Local的配置, 在storage.backend選擇local
local的話, 會選擇使用tempo內建的tempodb, 跟Pormetheus的TSDB很類似的機制能參考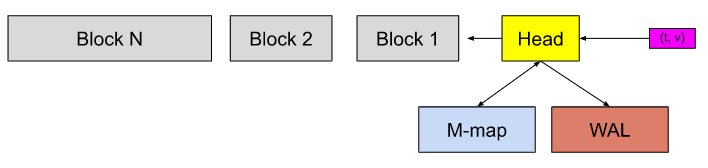
上圖來源
然後設定wal;
配置storage.wal.path wal(write ahead log)的路徑storage.wal.encoding, 是wal內容的壓縮方法, 預設是snappy壓縮方法, 其他可選擇的有none, gzip, lz4-64k, lz4-256k, lz4-1M, lz4, snappy, zstd, s2storage.wal.search_encoding設定搜尋到的資料的壓縮方法, 預設是nonestorage.wal.ingestion_time_range_slack在span被寫到WAL時, 也會根據這裡設定的duration, 去調整對應block的起始與結束時間; 預設時長是2分鐘, 看原始碼能看到這設定在trace資料, 從Head要被寫到位於應上的block時會被呼叫來檢查.
source code
storage:
trace:
backend: local
wal:
path: /tmp/tempo/wal
encoding: snappy
search_encoding: none
ingestion_time_range_slack: 2m
再來是block的配置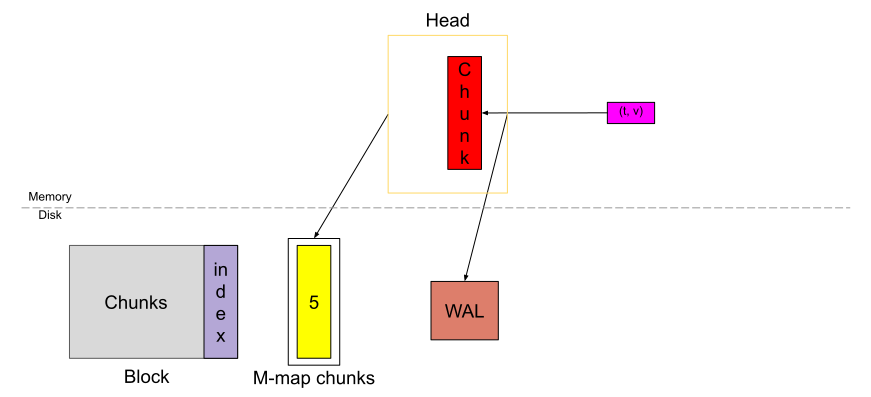
上圖來源
storage.block.bloom_filter_false_positive
這設定是用在Bloom Filter上的false positive配置; false positive假陽性, 表示資料可能有在Bloom filter中, 但就不一定真的在; 這係數就在調整這誤判的可能性; Bloom filter用來判斷一定不在絕對準, 但用在判斷物件一定在就有可能會誤判了
storage.block.bloom_filter_shard_size_bytes bloom filter的最大尺寸, bloom filter就是因為不需要太大的空間來存放, 因而知名, 所以預設100KiB, 也蠻夠用的了.
像這圖最底下有bloom-n, bloomName的原始碼
這會在寫入資料時產生, 原始碼
也能給Search時使用,原始碼, 因為很有可能資料還沒寫到被壓縮過後的block內, 還在head跟wal這
storage.block.index_downsample_bytesblock區塊內有index, 這裡用來配置index的大小.storage.block.version, 這裡選擇的是block的encoding類型, 有v2和vparquet, 預設是v2, 原始碼在此storage.block.encoding這邊就配置compression壓縮演算法,跟storage.wal.encoding支援一樣的演算法storage.block.search_encoding設定搜尋
block:
bloom_filter_false_positive: 0.01
bloom_filter_shard_size_bytes: 100KiB
index_downsample_bytes: 1MiB
version: v2
encoding: zstd
search_encoding: snappy
search_page_size_bytes
Compactor是用來壓縮硬碟上的多個blocks, 去掉重複和壓縮成一個更大的block, 有助於降低存儲的成本(去掉重複以及減少索引的大小)
提昇查詢速度, 因為要查詢的block數量因而變少了.
compactor:
ring:
kvstore:
compaction:
block_retention:
compacted_block_retention:
compaction_window:
chunk_size_bytes:
flush_size_bytes:
max_compaction_objects:
max_block_bytes:
retention_concurrency:
iterator_buffer_size:
max_time_per_tenant:
compaction_cycle:
Loki, Tempo的db部分很多都借鑑Prometheus的db設計, 參考那邊的文章比較多資訊.
這種的db設計都是為了避免寫入放大, 畢竟這裡的資料並不會被修改刪除,
會用一個tombstone標籤來標示某個資料已經過期了.

