集成方法(Ensemble Method)除了Bagging之外,另一個方法為提升算法(Boosting),其概念為將多個弱分類器組成一個強分類器,與Bagging有相類似的部分,但更加強調訓練時的錯誤,並針對錯誤的部分加強學習。Boosting會將舊分類器中出錯的部分之權重提高,加強訓練後產生新的分類器,藉此提高模型的分類效果。
Boosting的方法有非常多種,例如;AdaBoost, Gradient Boosting和XGBoost等。
AdaBoost為Adaptive Boosting的縮寫,為1995年提出,概念為訓練過程中會給予分錯的部分較高的權重,透過權重的差異影響模型著重訓練的部分,而訓練出多個弱分類器後,則會加重分類錯誤率較小的分類器權重,降低分類錯誤率大的分類器權重,以確保模型可以輸出較為正確的數值。
梯度提升算法(Gradient Boosting)和AdaBoost不太相同,Gradient Boosting結合了Boosting和Gradient Descent,概念為在訓練過程中計算模型估計出來的結果和真實結果之間的誤差,透過訓練的方式,降低誤差的數值。
而現在較被廣泛使用的為XGBoost (eXtreme Gradient Boosting),為專門用來處理大型數據集所設計的,運算的速度較快,模型保有Gradient Boosting的迭代方法,每一次產生的樹具有關聯性,期望後面產生的樹可以改善前面的樹的缺點,且加入了正規化以避免模型產生過度擬和的情況。
xgboost套件中的xgboostlibrary(xgboost)
model_xgb <- xgboost(data = data.matrix(training[,1:12]),
label = training$Activity,
eta = 0.1,
max_depth = 15,
nround=20,
eval_metric="mlogloss",
objective = "multi:softprob", ## 多類別使用
num_ㄒㄧㄢclass = 13) ### 總共分為13類
pred_xgb_prob <- predict(model_xgb, data.matrix(testing[,-13]),reshape = T)
pred_xgb <- data.frame(pred_xgb_prob) %>% mutate(max = max.col(., ties.method = "last")-1) ## 減一是因為activity的標號從0開始
pred_xgb <- as.factor(pred_xgb$max)
confusionMatrix(pred_xgb,reference = as.factor(testing$Activity))

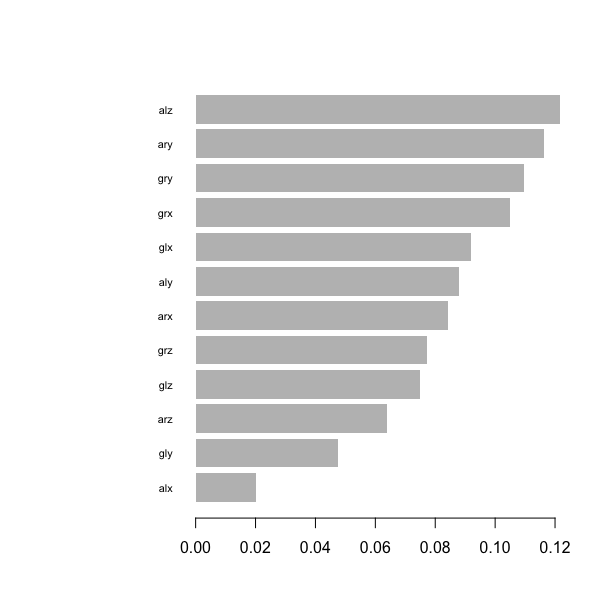
# 計算變數的重要性
import_matrix <- xgb.importance(model_xgb,feature_names = colnames(training)[1:12])
print(import_matrix )
# Feature Gain Cover Frequency
#1: alz 0.12155060 0.09729980 0.07059704
#2: ary 0.11640669 0.11449869 0.08316312
#3: gry 0.10958417 0.11358314 0.09455245
#4: grx 0.10487111 0.07680395 0.08375991
#5: glx 0.09187051 0.09319525 0.12329896
#6: aly 0.08796485 0.07710214 0.06172933
#7: arx 0.08423925 0.08441937 0.07735499
#8: grz 0.07711114 0.08346696 0.09001353
#9: glz 0.07504635 0.06553029 0.09784737
#10: arz 0.06380992 0.07074240 0.07061385
#11: gly 0.04743592 0.06258223 0.09053467
#12: alx 0.02010947 0.06077579 0.05653479
# 變數重要性視覺化呈現
xgb.plot.importance(import_matrix)
xgboost套件中XGBClassifierfrom xgboost import XGBClassifier
#模型
model_xgb = XGBClassifier(n_estimators=100, learning_rate= 0.3)
model_xgb.fit(X_train, Y_train)
#預測
pred_xgb = model_xgb.predict(X_test)
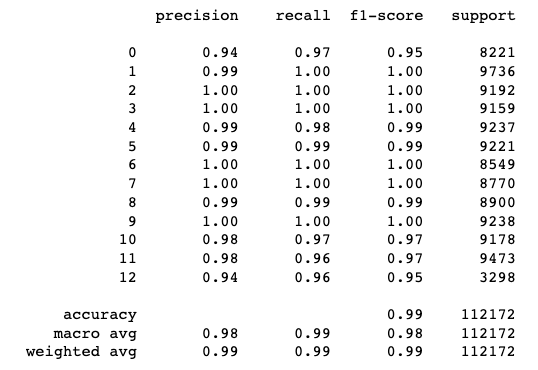
# 衡量
print(metrics.classification_report(pred_xgb, Y_test))


 iThome鐵人賽
iThome鐵人賽