隨機森林(Random forest, RF)為結合多顆分類與迴歸樹(CART)組合而成的模型,因此是結合多個機器學習模型來建構出的一個較強的模型,而此種方法又屬於集成方法(Ensemble Method)的一種。
由於在訓練模型中僅會放入一個訓練數據集,為了在隨機森林中產生多顆具有差異性的樹,因此會採用引導聚集算法(Bagging, Bootstrap aggregating)方式來協助完成。
引導聚集算法(Bagging, Bootstrap aggregating),又稱裝袋算法,步驟為給定一個固定大小為n的資料集X,從中用隨機且取後放回的方式選取m個大小為k的資料集X_i,當作新的訓練子資料集,因此建立出m個子資料集便可得到m個模型,雖然子資料集的資料會有部分重複,但整體仍是不相同的,因此所建立出來的CART樹仍具有差異。因此會透過投票的方式綜合多個模型結果,並將投票結果作為bagging的結果。
randomForest套件中的randomForestlibrary(randomForest)
#模型 (ntree和mtry可tuning)
model_rf <- randomForest(as.factor(Activity) ~ ., data = training,
ntree =500 , mtry = 3)
#預測
pred_rf <- predict(model_rf,testing,'class')
# 衡量
confusionMatrix(pred_rf,reference = as.factor(testing$Activity))

sklearn.ensemble套件中的RandomForestClassifierfrom sklearn.ensemble import RandomForestClassifier
# 模型
model_rf = RandomForestClassifier(n_estimators=100, random_state=0)
model_rf.fit(X_train, Y_train)
# 預測
pred_rf = model_rf.predict(X_test)
# 衡量
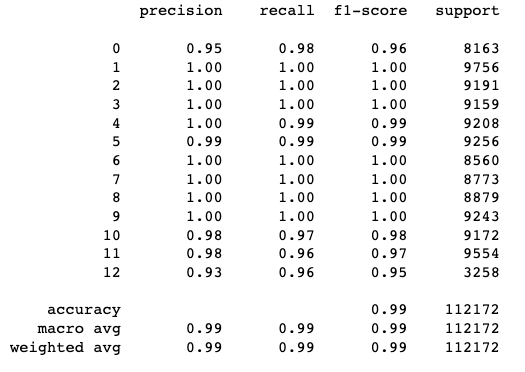
print(metrics.classification_report(pred_rf, Y_test))


 iThome鐵人賽
iThome鐵人賽