大家早安!歷經了四天針對經典監督式機器學習模型的了解,我們也算是小~小~的踏進NLP世界裡了。如果把這比喻成FPS(第一人稱射擊遊戲)的話,大概就是開局撿完了頭盔、防彈背心、手槍、跟一些繃帶吧。我們可以慢慢開始上路找更好的資源了。出發!
今天要跟大家介紹我心中最優秀的結拜兄弟人選-支持向量機(Support Vector Machince, SVM)。名字看起來就已經很可靠了有沒有XDD 在正式介紹這位人才給大家之前,想請各位先看看下圖,你覺得用哪一條線來做分類的基準最好呢?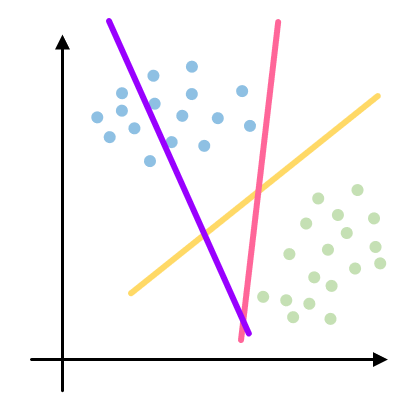
A)粉線(最接近垂直的那條)
B)黃線(往右邊倒的那條)
C)紫線(往左邊倒的那條)
D)粉線跟黃線都可以
如果有人選(C)的話,可能要......重新看一次題目!這條線是要把藍色跟綠色的點分開喔(如果你是色弱或色盲的話,就是把左上角跟右下角兩群資料分開)我想應該(A), (B), (D)都會有人選,所以就讓我來說明一下。如果是對我們昨天介紹過的Logistic Regression來說,因為他就是個壞蛋嘛,只要能分化人群的方法對他來說都是好方法,所以今天如果我們使用的是Logistic Regression的模型,那粉線跟黃線都可以是他的選擇。但是對SVM來說就不是這麼回事了,SVM事事喜歡未雨綢繆,如果達到目標有很多不同的方法,那他一定是選擇那個最能應對突發狀況的方法來做。大概就像我這種膽小鬼一樣,玩PUBG的時候就喜歡龜起來等別人互相殘殺。不要小看龜起來這件事,他其實是很有學問的。因為毒圈從四面八方縮進來,敵人也可能會從四面八方過來。假設我知道今天有兩群人在從兩個方向靠近我,絕對就是不能靠近任何一方,要選那個不管哪邊的敵人過來,逃跑空間都最大的地方龜起來。SVM也是這樣的存在,因為NLP領域實際上在處理的是不斷出現的新資料,即便我們用自己能拿到最大限度的資料訓練模型也確保它的結果達到一定程度,也沒有辦法預測未來會有什麼樣的新資料會需要我們分類。所以SVM在找分類的那條線的時候,目標是要找到跟兩群資料距離最大的線,這樣才可以避免新資料進來的時候一不小心就被分到錯的地方。如果這樣講對你來說來是太過抽象的話,可以看看下面這張圖: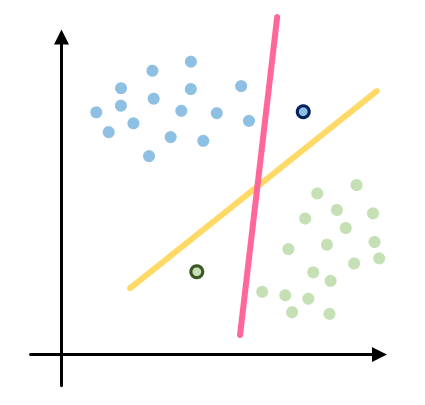
因為黃色的線跟兩群資料之間的距離都比較大,所以當有新資料加進來的時候,他比較不容易發生分類錯誤;相反的,因為粉紅色的在自己跟兩群資料之間預留的空間都不夠大,新資料進來的時候就發生了分類錯誤的情況。
從上面的圖我們感受到,即使是同樣能把訓練資料好好分類的兩條線,根據他們之間跟兩群資料的距離差異,判別新資料類別的時候會產生不一樣的結果。這是SVM跟Logistic Regression不一樣的地方,他應對新資料的能力比較好。我們在這裡當然沒有要推導SVM的公式,大家只要記得SVM在做的事情就是像下圖那樣透過線跟資料點之間的向量計算(這個距離較做margin)去找出距離最大的一條線就可以了。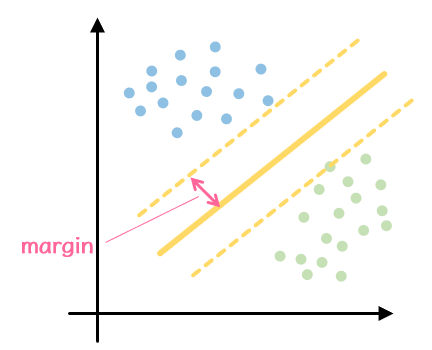
除此之外,前天在講解Logistic Regression的時候有提到他只能處理線性可分的資料,像下面這種資料出現的時候可能就無計可施,但是SVM可以!
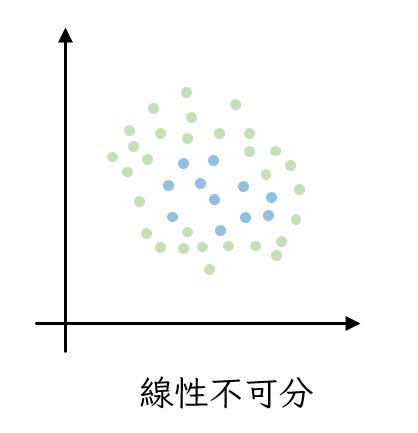
SVM 不只是一個事事未雨綢繆的傢伙,他看事情的角度也跟一般人不同。當SVM遇到在二維平面上線性不可分的資料,他會自行增加維度,就像這個影片裡面演示的一樣。當我們透過不同維度去看這些資料的時候就可以找到能把他們好好分群的平面。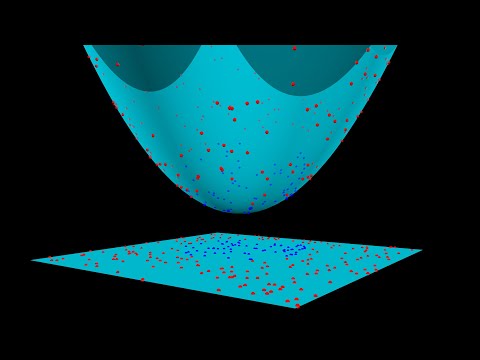
所以說SVM真的是不可多得的結拜兄弟人選,做事情面面俱到,看事情的角度也面面俱到,遇到問題找他幫忙跟訴苦絕對沒錯!不找這種人當朋友要找誰當呢?好啦說了這麼多,他其實還是有缺點的啦,因為計算方法比較複雜,所以樣本多的時候為了要從高維度裡面找出最好的平面,要花比較多時間,效率會很低。聰明人總是比較鑽牛角尖一點嘛~
今天就到這邊結束!明天會帶大家實做SVM也從跟昨天比較不一樣的角度切入文本情感分析。See you~


 iThome鐵人賽
iThome鐵人賽