
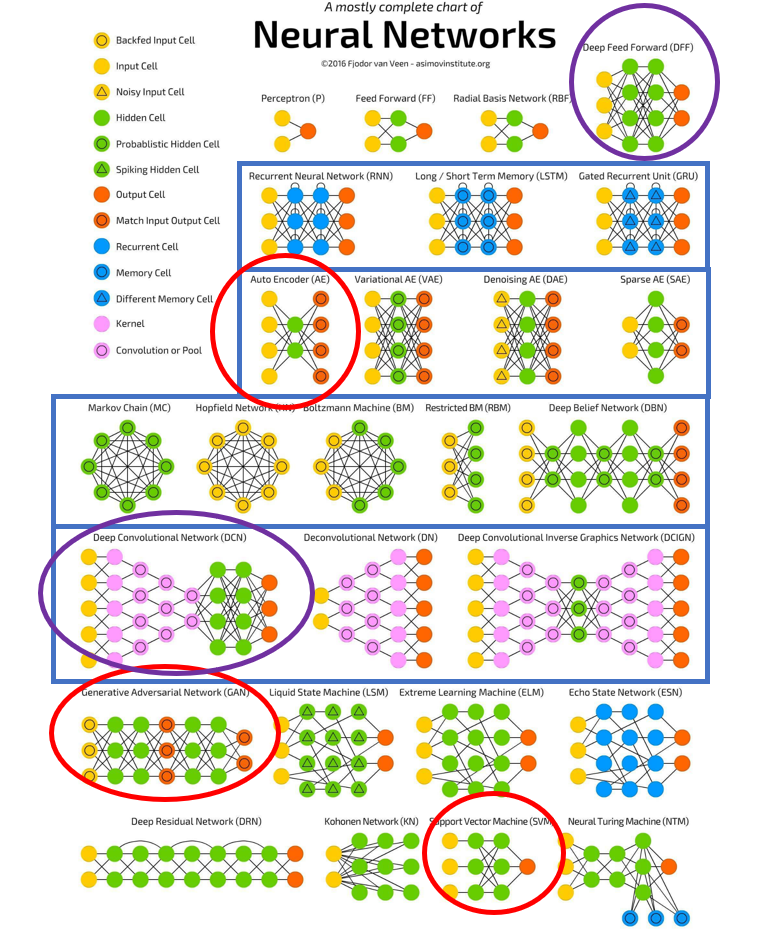
今天我們會繼續講 Asimov Institute 的 Fjodor van Veen 整理的這張神經網路表,昨天提到的神經網路是用紫色圈圈圈起來的 MLP 跟 CNN,今天要介紹的用紅色圈圈圈起來的SVM、Auto Encoder 跟 GAN。
這三個神經網路是在實作手寫數字辨識系統時,會提到或可以應用到的方法。
所以這篇也可以看成是實作手寫數字辨識系統這個主題時的延伸內容,以及後面兩個還在研究熟悉中,大家參考即可w
中文翻成支持向量機。有些人會利用 SVM 這種方法來分類手寫數字,是因為 SVM 這種方法就是在找一個決策邊界(decision boundary)或超平面(hyperplane,意思是指高維中的平面),來分類兩種資料。
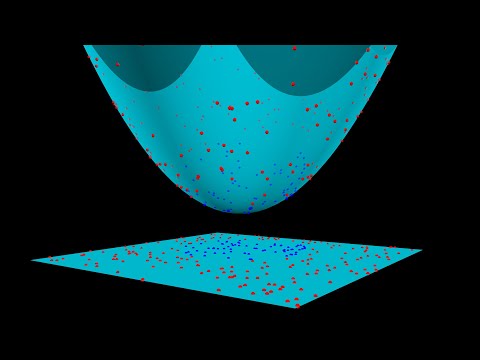
這邊不提 SVM 是怎麼做到線性和非線性分割的,僅先說明上面那段話+影片可能帶出的兩個小疑問:
(1) SVM 是一種神經網路(network)方法嗎?
SVM的始祖論文就告訴你答案了XD → Support-Vector Networks
線性 SVM 可以看成是一個單層的神經網路,它有損失函數(Hinge Loss)和目標函數(maximum margin)。但在處理非線性資料時,神經網路是用多個隱藏層達到非線性目的,而非線性 SVM 則是用 kernel trick,把低維度不能分類的資料送到高維度去做運算分割。
所以平常我們會說 SVM 是一個機器學習方法,但不會特別說它是不是一種神經網路。
(2) 我們可以從影片中看到,SVM的本質上是二元分類器(binary classifier),那它怎麼做到多元分類的呢?
主要是組合多個二元分類器來實現多元分類的目的~
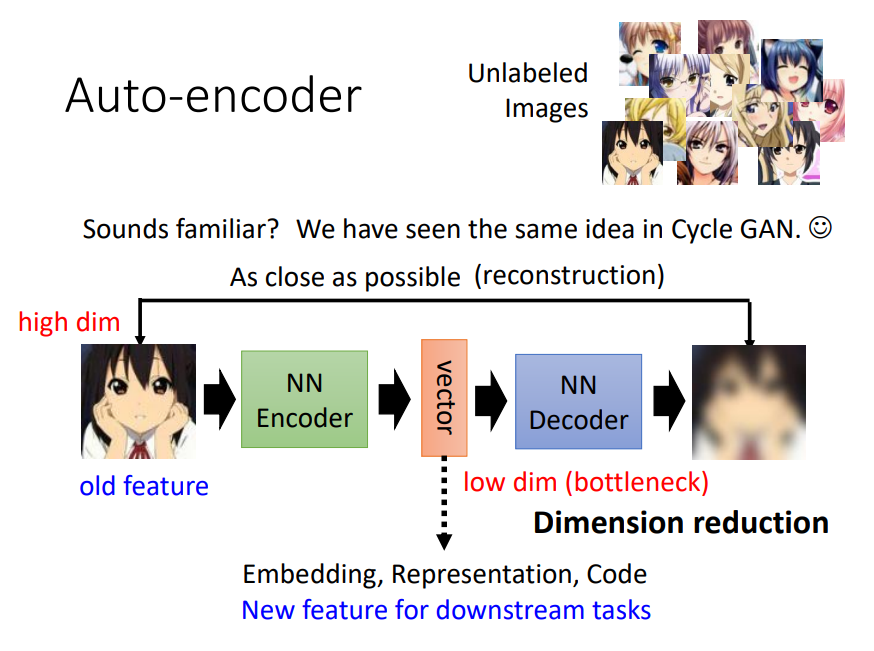
圖片來源:李宏毅老師的機器學習課程(2021)
中文翻成自編碼器。它是非監督式學習的。它的訓練過程就是把輸入壓縮,再還原輸出,然後希望輸出跟輸入差異越小越好(用 loss function 評估)。
下面舉例一些使用auto encoder 的情境:
它有變形小夥伴如 Variational AE(進階版AE)、Denoising AE (可以做到降躁)等。會在這篇介紹 Auto Encoder 主要是因為蠻多人會用 mnist 資料集來認識這系列模型,因為它可以看需求把它拿來用在手寫數字辨識或其他影像上,但此模型也常用在序列型(squencial) 資料如語音或文字語句上。
ps. Deepfake 換臉軟體有用到 Auto Encoder
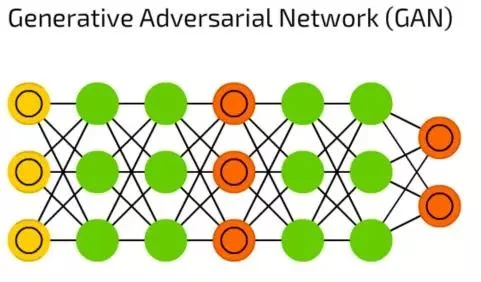
中文翻成生成對抗網路。
當你覺得手寫數字圖片不夠全面,可以用 GAN 來幫你生成圖片。
Auto Encoder 跟 GAN 都可以生成圖片,所以很多人會拿這兩種模型來比較!
明天會繼續簡單介紹表中的神經網路模型及對神經網路這個主題做個總結,大家明天見!
