我們現在要來了解前面疊的那個神經網路叫什麼,我還可以疊那些神經網路,或能不能把前面疊的那個神經網路變複雜等等。
大家可以看一下下面這張由 Asimov Institute 的 Fjodor van Veen 整理的神經網路表(魔法陣XD),他列了七列 27 個神經網路,這邊想簡單介紹一下紫色圈圈、紅色圈圈跟藍色框框所提到的神經網路~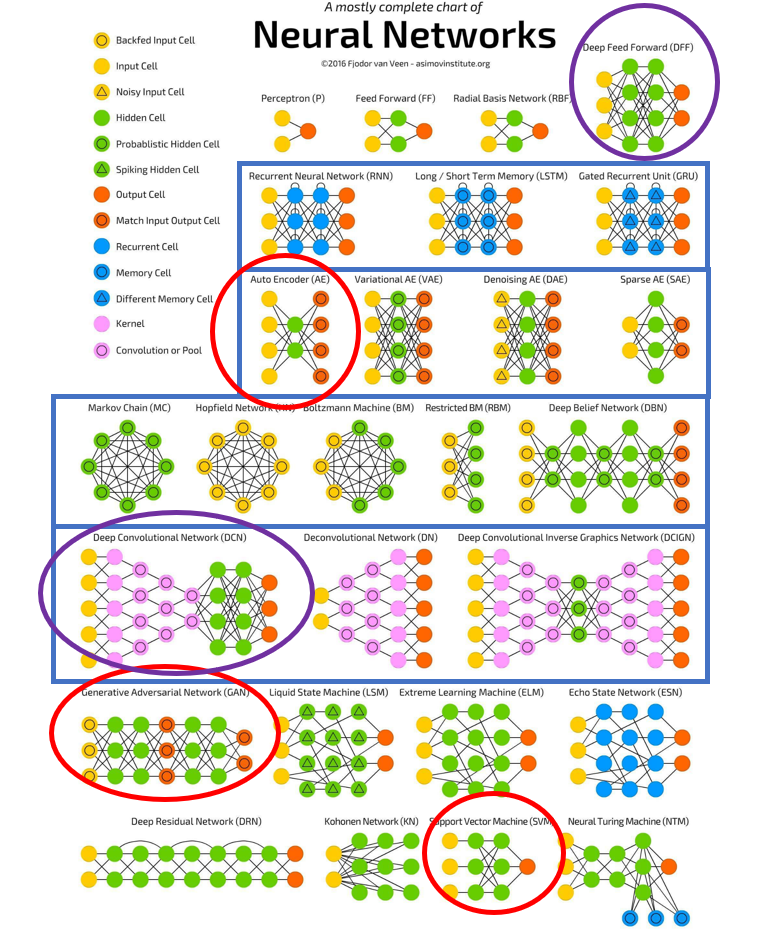
圖片來源:Asimov Institute 的 Fjodor van Veen 整理的神經網路表
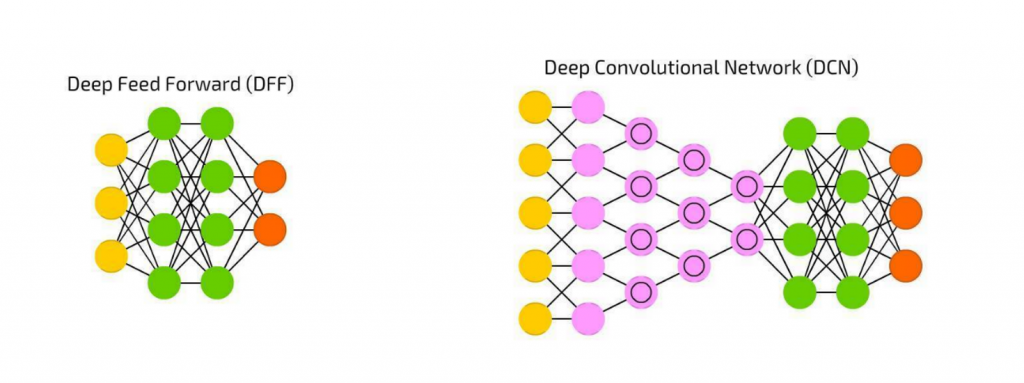
我們前面的手寫數字辨識系統使用的是一個叫前饋神經網路(DFF, Deep Feed Forward)的序列神經網路(Sequencial Neural Network),這個有輸入層、中間的隱藏層跟輸出層的神經網路也可以被稱為多層感知器(MLP, Multilayer perceptron),而最簡單的 MLP 只有一層隱藏層。上圖左則是含有兩層隱藏層結構的 MLP。
我們可以看到,MLP 層與層之間的神經元都是全連接(Fully Connected),也就是每一層的每個神經元都會跟下一層所有神經元連接(Dense Layer)。
這邊我把卷積神經網路(CNN, Convolutional Neural Network)與前饋神經網路放在一起,大家可以比較這兩者,會發現如果拿掉粉色的卷積層(Convolutional layer)或池化層(Pooling Layer)後,這兩個模型的結構就一樣了!
所以讓我們來細看一下卷積神經網路(CNN, Convolutional Neural Network),CNN 是由卷積層、池化層和全連接層組成,通常會疊很多層,所以也可以被稱為深度卷積網路(DCN, Deep Convolutional Network)。由於網路上卷積神經網路的介紹非常多,所以我這邊簡單說明為什麼我們常拿 CNN 來分類影像辨識。
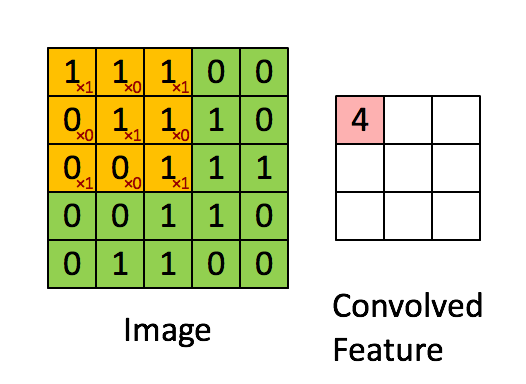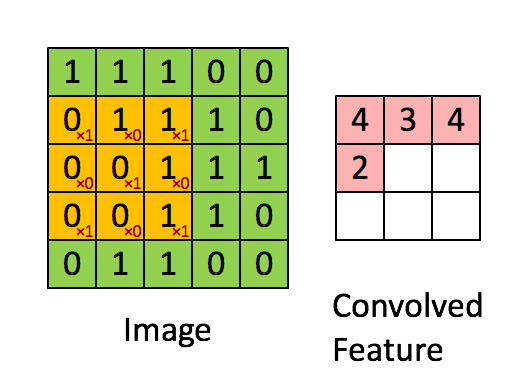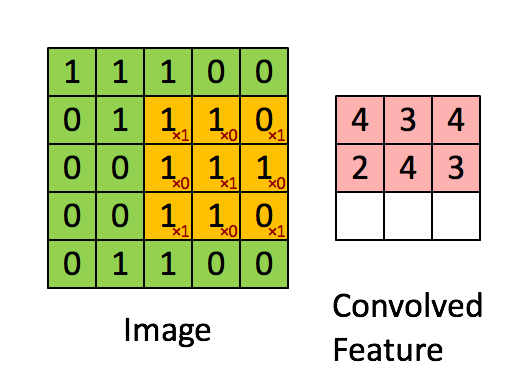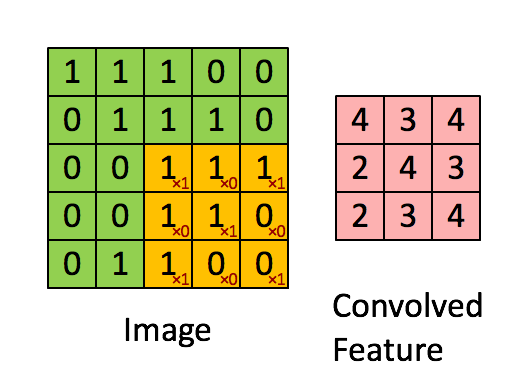
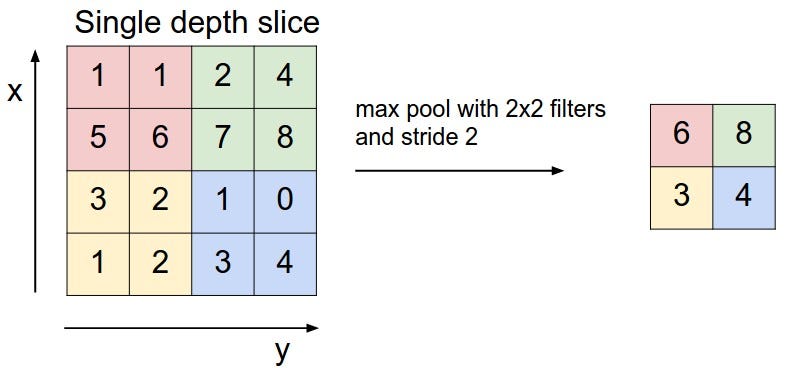
這邊簡單列了幾個用 CNN 模型來做影像辨識的優勢:
今天先簡單做個小結,我們可以把手寫數字辨識系統的神經網路變成 CNN 架構?可以的!其他我們明天繼續說~

