前面文章告訴大家如何建置 YOLOv5 的環境在 Jetson Nano 上,並且使用官方提供的預訓練模型進行推論與測試。但畢竟官方提供的模型使用的是 coco dataset,未必適合大家使用在自己的專案上,所以這篇文章將帶大家從蒐集自己的資料開始。
我們將透過攝影機拍攝照片來蒐集自己的資料,請先構思想要透過物件辨識來辨識的目標。比方說筆者有一個紅蘿蔔布玩具,我希望透過物件辨識來辨識「紅蘿蔔」,與蘿蔔被拔掉後留下的「坑洞」這兩個目標。待會兒將會針對這些目標拍攝相關的照片,作為訓練與驗證的資料。
輸入以下指令從 github 上下載我們自行撰寫的圖像抓取工具:
git clone https://github.com/CIRCUSPi/Jetson-capture.git
cd Jetson-capture/
裡面只有一個名為 capture.py 的檔案,使用 OpenCV 模組開啟 webcam 即時預覽,並且可以快速的儲存成 jpg 檔,所有檔名將以 UUID 亂數產生避免重複。其程式碼如下:
import cv2
import uuid
import os
import time
cap = cv2.VideoCapture(0)
folder_name = 'images'
try:
os.mkdir(folder_name)
count = 0
except:
print('Folder already exists.')
list_ = os.listdir(folder_name)
count = len(list_)
while True:
_, frame = cap.read()
img = frame.copy()
text = "count: " + str(count)
cv2.putText(img, text, (10, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 255), 1, cv2.LINE_AA)
cv2.imshow('win', img)
keyin = cv2.waitKey(1) & 0xFF
if keyin == ord('q'):
break
elif keyin == ord('s'):
cv2.imwrite('{}/{}.jpg'.format(folder_name, uuid.uuid1()), frame)
count += 1
time.sleep(0.01)
cap.release()
cv2.destroyAllWindows()
上述程式使用 OpenCV 套件幫我們從攝影機擷取影像,並讀取鍵盤指令儲存拍攝畫面。現在讓我們執行這個程式,先確保網路攝影機連接在 Jetson Nano 上,接著開啟終端機並輸入下列指令並按下 Enter 鍵:
python3 capture.py
輸入完指令後會跑出顯示視窗,並新增一個名為 images 的資料夾,攝影機拍攝的畫面會顯示在視窗中。請將攝影機對準您要辨識的物品,只要按下鍵盤上的 s 按鍵,就會將看到的畫面儲存成照片,畫面左上角會提示目前拍攝的數量,照片則會統一存放在 images 資料夾。
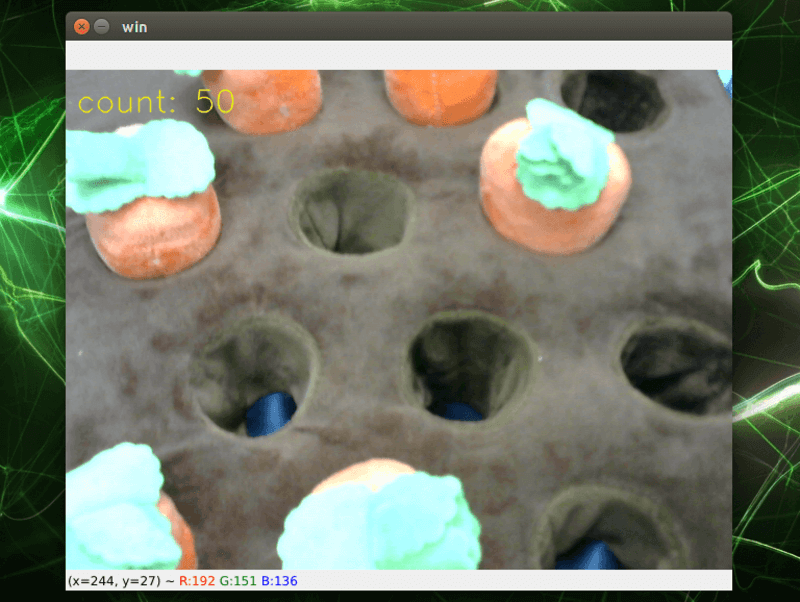
images 資料夾的路徑沒意外的話,會在輸入指令的路徑底下。那到底要多少照片才夠呢?對於訓練來說,當然是越多例子越好囉!如果一定要有個具體的數字,筆者建議是至少每個類別至少要有 250 ~ 300 多的標註數量,才能訓練出一個相對好的模型,供大家參考。這邊為了貪圖方便,筆者只拍攝了 50 張照片做示範。
為了方便快速的從攝影鏡頭拍攝照片,今天使用了一個小工具來完成。當然各位也可以用傳統的相機應用程式單獨拍照,或是我們前面介紹 Hello AI World 系列中也有個 Camera-Capture 工具可以使用,但是因為 YOLO 物件標註的格式和 VOC 不同,為求方便起見,今天僅做影像的擷取,明天將使用強大且方便的 Roboflow 輔助我們標記資料,並進一步建置自己的資料集。 Keep Going!


