本篇文章使用的圖片皆來自於 Dropbox 的文章 How image search works at Dropbox。
國慶連假後的上班日,Skylar 感到十分鬱卒。他只好打開 Dropbox,搜尋和野餐(picnic)相關的照片,想要藉由瀏覽過往出去玩的照片,以消除上班的憂鬱。
Skylar 覺得神奇的是,這些照片的檔名都沒有特別和野餐(picnic)有關,甚至其實都是一些英文和字母隨機組成的亂碼,Dropbox 是怎麼篩選出這些照片的呢?
今天讓我們一起來看看 Dropbox 的圖片搜尋演算法是如何設計的吧!
首先,先定義圖片搜尋的問題公式為 s = f(q, j),想要找搜尋關鍵字(query, q)和照片(image, j)相符合的關聯分數(relevance score, s)。在用戶輸入一個搜尋關鍵字(query, q)後,回傳所有關聯分數(relevance score, s)高於一個臨界值的照片(image, j)。
為了達成此目的,Spotify 使用兩個 ML 技術:圖片分類系統(image classification)和詞向量(word vectors)。
如同昨天的文章中,Airbnb 使用圖片分類系統將房東上傳的照片分類。Dropbox 也使用圖片分類系統將所有圖片分類,並輸出每個類別的可能分數。
類別分為以下三種:
而圖片分類系統的輸出如下圖所示,每一個類別會有一個分數,且可能不止一個類別會高達 0.9 以上。
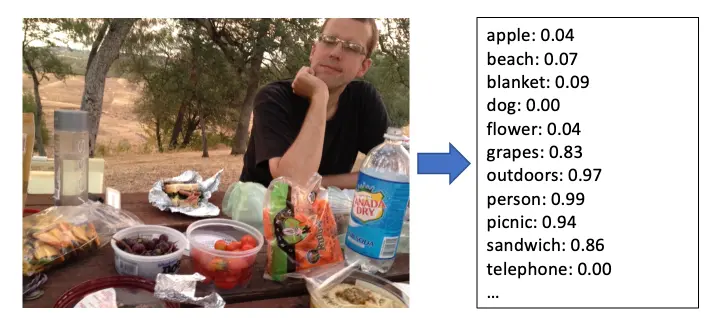
不過,圖片分類系統不可能窮盡所有類別,該怎麼處理類別的同義詞呢?例如,分類器裡面有「海邊」跟「蘋果」的類別,但是使用者可能輸入「海岸」,或是「青森蘋果」,此時 Dropbox 要如何知道要回傳哪些圖片呢?除了列出所有同義詞以外,是否還有其他更有效率的解法?
這就是詞向量(word vectors)使用的時機了!
首先,每個圖片分類系統輸出的類別可以轉成一個向量 j_c,而每個用戶輸入的搜尋關鍵字(query)也可以轉成一個向量,只要知道這兩個向量有多接近,即可知道此張照片和搜尋關鍵字的匹配程度。
Dropbox 利用 word2vec 將搜尋關鍵字(query)轉成向量,再經由以下步驟,把搜尋關鍵字(query)的向量轉成在類別空間中的向量。
word2vec 將搜尋關鍵字(query, q)轉成在 d 維度的向量:q_w = word2vec(q)。word2vec 將每個類別名稱(c)轉成在 d 維度的向量:c(i)_w = word2vec(c(i))。q_w 和每個類別 c(i)_w 的餘弦相似度(cosine similarity)m(i),m(i) 代表 q_w 和 c(i)_w 的相似程度,而 m(i) 是一個介於 -1 到 1 之間的浮點數。他們將所有小於 0 的 m(i) 都轉成 0,得到介於 0 到 1 之間的 m(i)。m(i) 串接起來得到 q_c = [m1, m2, ..., mC],此為 C 維的向量,代表此 q_w 和每個類別的相似程度。藉由以上幾個步驟,可以成功地抓取所有和 q_w 相似的類別,再將 q_c 和圖片向量 j_c 計算(s = q_cj_c),得到最終圖片的相關分數(s)。
將所有圖片依據相關分數(s)排序,以選出要呈現給用戶的所有圖片。
這樣說明可能有點令人頭昏眼花,讓我們來看一個實際的計算過程。
假設詞向量(word vectors)只有三維,而分類器有四個類別:蘋果(apple)、海灘(beach)、毯子(blanket)和狗(dog)。
步驟 1:假設使用者輸入的關鍵字為海岸(shore),藉由 word2vec 轉換後得到 qw = [0.35, -0.62, 0.70]。
步驟 2:這四個類別各自也經由 word2vec 轉換,得到自己的詞向量,組成矩陣 C,列舉如下:
c(1)_w = [-0.13, 0.68, 0.72]
c(2)_w = [0.38, -0.70, 0.60]
c(3)_w = [0.87, -0.22, -0.44]
c(4)_w = [-0.44, 0.41, 0.80]
步驟 3:經過向量、矩陣的計算,得到最後的 q_c = [0.04, 0.99, 0.13, 0.15]。換句話說,海岸(shore)和第二個類別「海灘(beach)」的相似程度最高,因此應該要回傳類別為「海灘(beach)」的圖片。

以上是整個 Dropbox 圖片搜尋演算法的架構。不過實際運用上,不可能每次都重新計算所有圖片和搜尋關鍵字(query)的相似分數,因為用戶可能有成千上萬張圖片,這樣非常沒有效率。
因此,Dropbox 設計另外一套解法,稱為 Nautilus 搜尋引擎。
Nautilus 的做法是設定兩組 indexes,forward index 和 inverted index。

因此,當 Skylar 輸入「野餐(picnic)」時,會經過以下幾個步驟:
q_w,再乘上所有類別向量組成的矩陣 C,得到 q_c。類別向量的矩陣 C 對每個使用者而言都是固定的,不用重新計算。q_c 類別,再從 inverted index 中篩選出這些類別的圖片。forward index 得到每個圖片的類別向量(category vector, jc),再將 q_c 和 j_c 相乘,得到關聯分數(s)。最後,根據關聯分數(s)以挑選出高於閾值的圖片,並依照關聯分數(s)排序圖片。經過以上的簡化,Dropbox 不需要每次都重新跑一次模型,能夠快速有效率地篩選出用戶查找的照片。
以上是 Dropbox 圖片搜尋演算法的介紹。其實都沒有用到特別困難的技術,不過經過精巧地設計之後,竟可以解決一個看似複雜的問題,不由得佩服他們的資料科學家。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:
How image search works at Dropbox: https://dropbox.tech/machine-learning/how-image-search-works-at-dropbox


 iThome鐵人賽
iThome鐵人賽