對社群網站而言,使用者積極的互動是非常重要的一環。因此,打造一個用戶能夠安心發文、建全的評論環境更是不可忽視的重要任務。社群網站往往會提供用戶檢舉貼文的選項,以幫助網站過濾危險或詐騙的訊息。不過,除了用戶主動地檢舉之外,是否能夠使用機器學習技術,以打造一個更安全的環境呢?
今天,讓我們一起來看看這間大公司 Pinterest,是如何使用你我皆熟悉的技術,建構更健康的評論系統吧!
首先,我們先來看看 Pinterest 網站是由哪些元素組合而成的。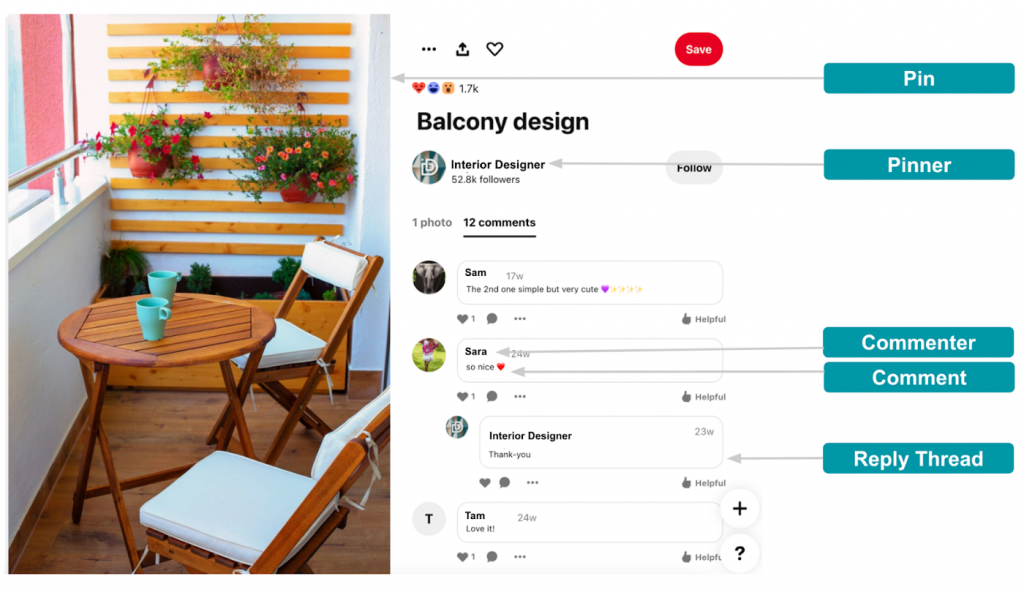
如上圖所示,可分為以下五個部分:
在如同上圖的討論情境下,Pinterest 希望評論環境能夠有以下幾個特徵:
為了達成此目的,Pinterest 使用一個機器學習模型,執行以下四個任務,以進行評論分類。
| 目標 | ML 任務 |
|---|---|
| 辨識不安全的評論 | 將評論分類為安全或不安全 |
| 辨識詐騙的評論 | 將評論分類為詐騙訊息或非詐騙訊息 |
| 辨識評論的情感 | 將評論為正向、中性或負向 |
| 辨識評論的品質 | 將評論為高品質或低品質 |
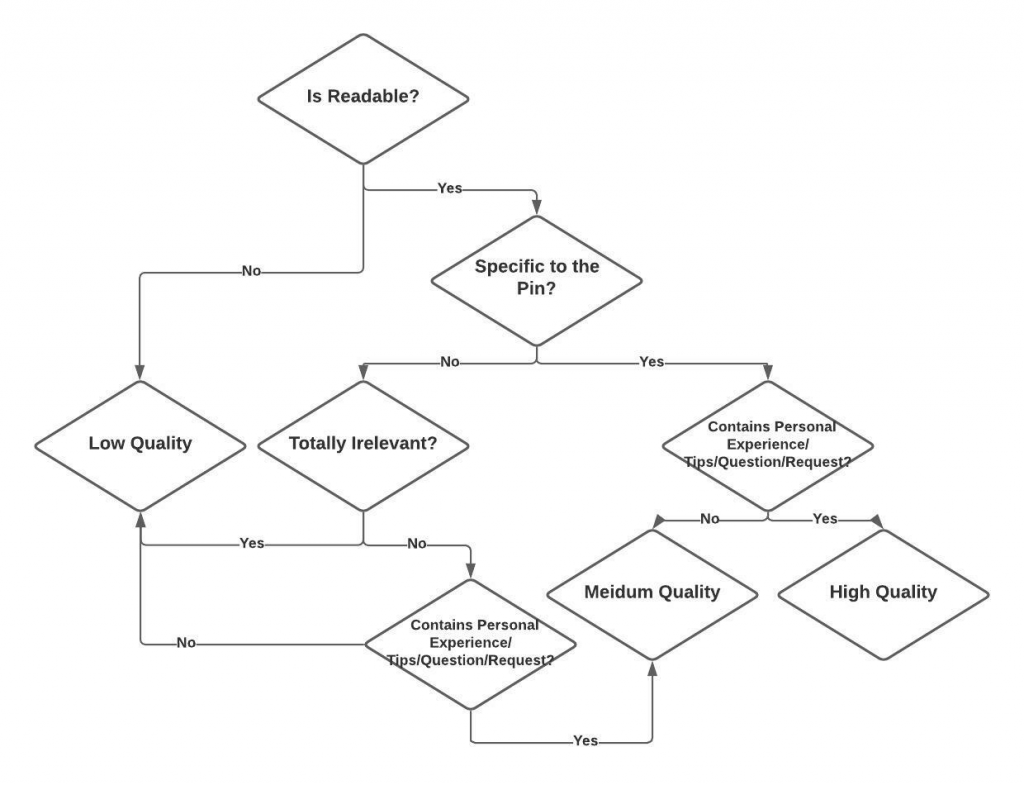
其中,不安全的評論定義為違反社群守則,而高品質的評論定義為有可讀性(沒有錯誤,且可以理解)、和 pin 的關聯性高,且是 nuanced 的評論(問題、撇步、建議、需求、描述發言者的個人經驗或和 pin 的互動)。
Pinterest 於 2021 年 3 月上線此功能,至 2021 年 12 月為止,用戶檢舉的評論數量下降 53%,可見此模型的有效性。
根據任務不同,評論的標記來源稍有不同,不過共通的是訓練模型時只有使用英文的評論。
標記來源可分為以下幾類:
Pinterest 使用一個 pre-trained 的 transformer 模型(multilingual DistilBERT),再 fine tune,以輸出四個不同任務的結果。
輸入的資料除了評論文字本身以外,為了得到更好的結果、考慮到不同的情境脈絡,也使用其他資料。所有輸入特徵列舉如下:
其中,發文者(pinner)和評論者(commenter)的特徵也包含經由 PinnerSage(詳見 Day 23 的介紹) 計算品味相似度。
以上五個特徵會一起輸入至 MLP(multi-layer perceptron)中,以便於特徵彼此交叉學習。
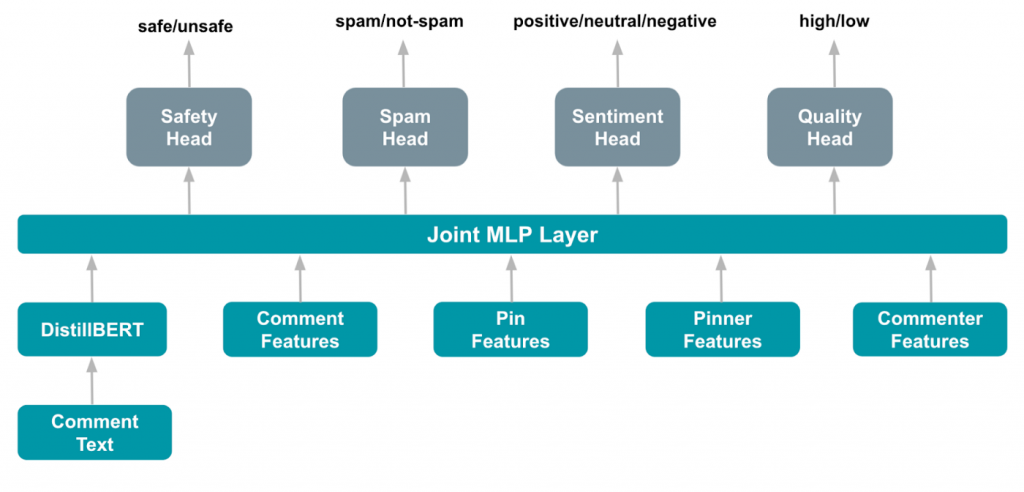
所有任務的 loss function 皆為 cross-entropy。
四個分類任務各自有輸出層,其中,二元分類任務(包含安全性、詐騙和品質)的 activation function 是 sigmoid,而情感分類器則是使用 softmax 的 activation function。
好的,以上就是 Pinterest 在辨識並過濾不好評論的機制,是否很驚訝竟然如此簡單呢?至少我滿吃驚地,在讀了這麼多科技公司的演算法後,我發覺他們其實都不一定會使用非常複雜且高深的模型,有時簡單的模型即可達到目的。而最重要的是,他們能夠有珍貴的資料訓練模型!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:

