在國慶連假時,Skylar 使用 Airbnb 預定出遊的住宿地點。而在入住後,他發覺和當初在網站上看到的照片並無二致,圖片品質很好且很精確,也會依照不同房型分類照片。他好奇難道所有照片都是屋主一一輸入分類的嗎?還是使用機器學習使模型自動標註呢?
一間如此大型的訂房網站如 Airbnb,在遇到需要訓練分類模型時,究竟是重新設計一套架構,還是也會搜集文獻,模仿前人所做呢?
今天,讓我們一起來看看 Airbnb 的圖片分類模型吧!
Airbnb 為了要幫助用戶找到最有資訊量的照片,確保照片傳遞的資訊是準確的,或是能夠建議屋主如何提升照片的吸引力,需要一個能夠將照片依照不同房間類型分類的模型。
他們希望此模型可以先初步將照片類型分成臥室、浴室、客廳、廚房、泳池和風景,如果之後產品部門有需要增減類別的話,也可以隨時調整。
在回顧文獻後,發現 ImageNet 的分類問題中也有房間分類的題目。不過由於 Airbnb 有一些自定義類別,不能直接套用。因此他們修改了以下兩點:
經過幾個不同模型之後,他們最終選擇 ResNet50 作為架構,在最後面多加兩層全連接層(fully connected layer),還有一個 Softmax 的 activation 層。
在重新訓練模型時,他們希望能夠得到至少 95% 的 precision,和 80% 以上的 recall。
而訓練的方法有兩種:
遇到的兩個困難:
第一個困難是 Airbnb 有數百萬張照片需要被標記,不可能全部都仰賴人工註記,因此決定採取兩種來源:

因此,為了過濾出更精準的照片,Airbnb 必須額外設定一些篩選條件。例如,為了得到最乾淨的廚房照片,他們使用以下 query:
AND LOWER(caption) like '%kitchen%'
AND LENGTH(caption) <= 22
AND LOWER(caption) NOT LIKE '%bed%'
AND LOWER(caption) NOT LIKE '%bath%'
AND LOWER(caption) NOT LIKE '%pool%'
AND LOWER(caption) NOT LIKE '%living%'
AND LOWER(caption) NOT LIKE '%view%'
AND LOWER(caption) NOT LIKE '%door%'
AND LOWER(caption) NOT LIKE '%table%'
AND LOWER(caption) NOT LIKE '%deck%'
AND LOWER(caption) NOT LIKE '%cabinet%'
AND LOWER(caption) NOT LIKE '%entrance%'
雖然如此一來會損失很多照片資料,但是為了得到最乾淨的結果,這個步驟是必要的。
最終上線的辨識模型是數個二元分類模型,而非一個多類別的分類模型。雖然這不是最理想的作法,不過由於這些模型是線下使用,所以即便結果稍慢,也尚可接受。
最後,Airbnb 使用 golden set 以評價模型。他們發現臥室和浴室是表現最好的,其他的房間,如客廳比較不盡如人意。原因可能是因為臥室的擺設通常較固定,而客廳的陳設較多元,且客廳的照片中都偶爾會涵蓋到餐廳或廚房。另外,一個全部重新訓練的模型(紅線)表現會比只訓練最後兩層(藍線)的表現還要好。
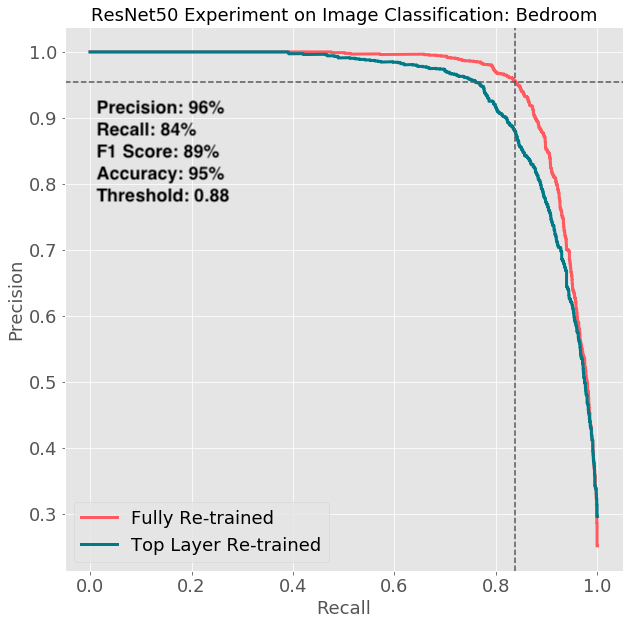
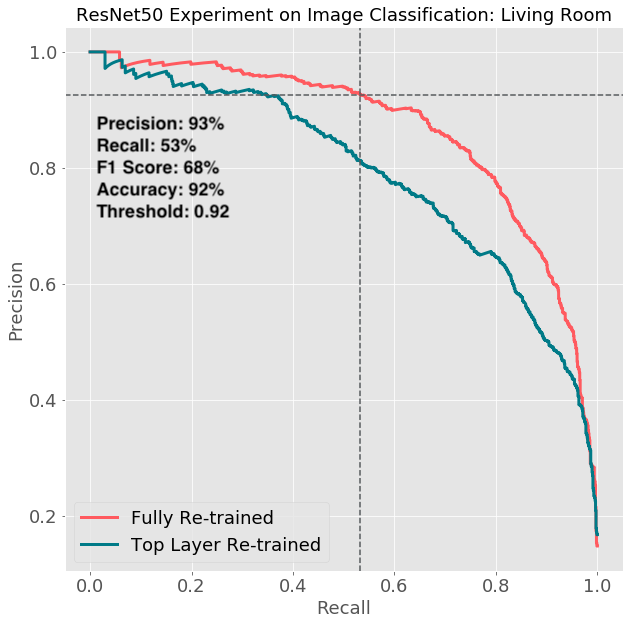
Airbnb 最後使用的六個模型,其 precision 約為 95%,而 recall 為 50%。
最後是幾個 Airbnb 的小小心得和建議:
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:

