上一篇討論 OpenAI API基本的用法,接著我們利用微調(Fine-tuning)建立企業專屬的模型,作為特定領域的資料庫,讓使用者以 ChatGPT 提問。
『微調』是轉移學習(Transfer Learning)重要的概念,大型語言模型(LLM)是一個基礎模型(Foundation Model),好比是一支萬用的螺絲起子,接上各種插頭,就會有不同的功能,例如情緒分析、Q&A、文本生成...,這個方式就是微調(Fine-tuning)。
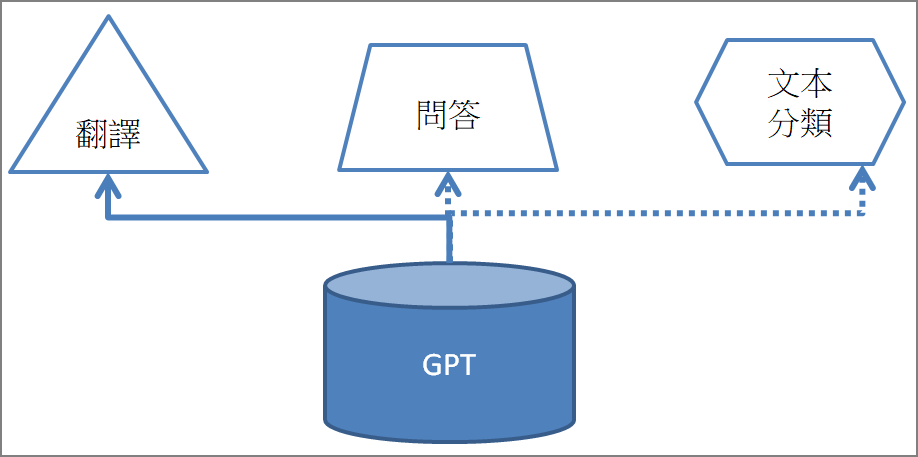
圖一. 模型微調(Fine tuning),可實現不同的任務
一般企業會有專有的商品或服務,例如金控公司會有各式的基金、保險、金融商品...,如果向ChatGPT提問相關商品資訊,很難得到正確答案,這時就可以利用『微調』,建立企業專屬的模型,提供客戶或內部使用者查詢。
依官網文件說明,『微調』還有以下優點:
微調不需要寫程式,步驟如下:
以下進行一個簡單的情緒分析測試,部分資料如下,完整資料可自GitHub sentiment_simple_CN.csv下載:
prompt,completion
這部達文西密碼真棒。,1
這部蝙蝠俠真棒。,1
這部斷背山真棒。,1
這部哈利波特真棒。,1
這部驚魂記真棒。,1
這部星際大戰真棒。,1
這部不可能的任務真棒。,1
這部達文西密碼糟透了。,0
這部蝙蝠俠糟透了。,0
這部斷背山糟透了。,0
這部哈利波特糟透了。,0
這部驚魂記糟透了。,0
這部星際大戰糟透了。,0
這部不可能的任務糟透了。,0
在終端機或cmd中,執行以下指令,會有一系列的問答,通常使用預設值即可:
openai tools fine_tunes.prepare_data -f <檔案>
建立微調模型,在終端機或cmd中,執行以下指令,模型請參考表二:
openai api fine_tunes.create -t <資料檔> -m <模型>
微調模型訓練完成後,會產生模型代碼,即可測試模型:
openai api completions.create -m <模型代碼> -p <提示>
注意,提示要遵守訓練資料的格式來撰寫。
也可以使用API或在Playground測試。
目前只限在GPT-3模型進行微調,不支援最新的GPT-3.5或4.0,GPT-3又分為以下模型: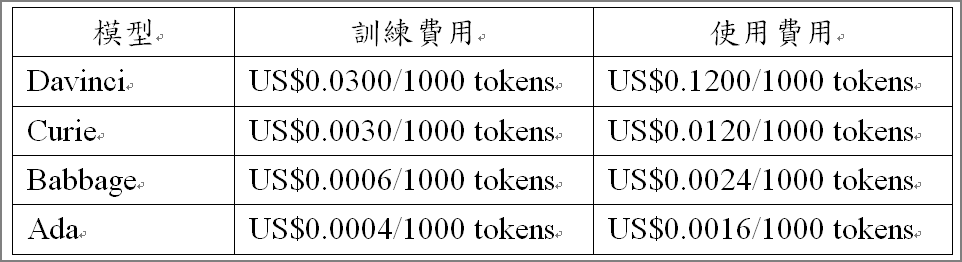
表二. GPT-3各類模型
Playground測試畫面如下,右邊選單可選擇剛訓練好的模型,要注意其他參數的設定,例如temperature、Maximum length,才能得到正確的回答: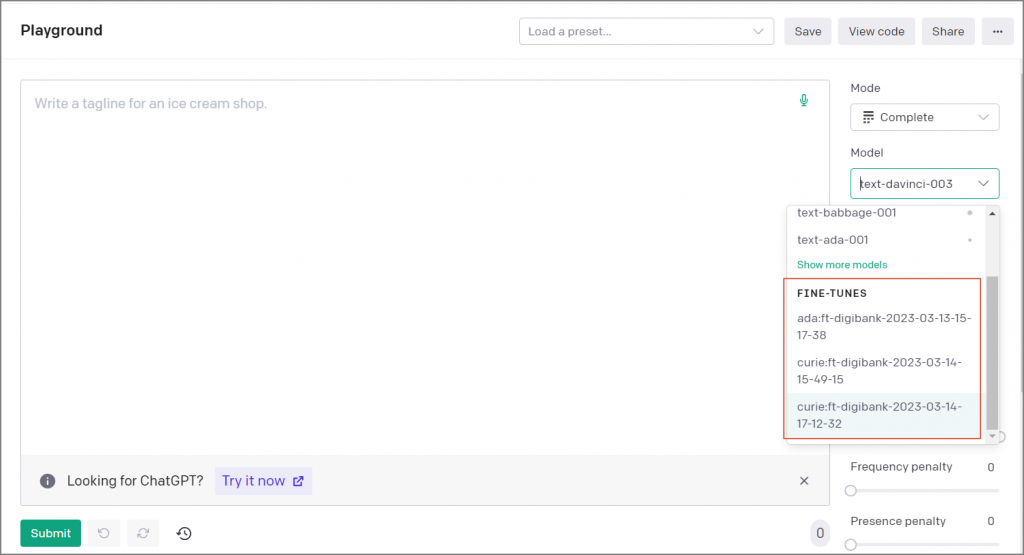
圖三. Playground
使用API測試很簡單,只要把模型設定為微調模型代碼即可,例如將以下程式碼存成fine_tune_test.py。
# 載入套件
import openai
if len(sys.argv) < 3:
print("執行方式:python fine_tune_test.py <prompt> <model>")
exit()
# 呼叫 API
prompt = sys.argv[1] + '->'
response = openai.Completion.create(
model=sys.argv[2],
prompt=prompt,
temperature=0,
max_tokens=1,
)
# 顯示回答
print(response.choices[0].text.strip())
執行 python fine_tune_test.py "The movie is great." "curie:ft-digibank-2023-03-14",即可得到答案,最後一個參數為模型代碼,須修改為讀者微調的模型。雖然訓練資料是中文,但輸入英文提示也是可以得到正確答案,而且提示也沒指名哪部電影,也OK。
微調的功能基本上屬於監督式學習,訓練資料必須標註答案,因此,一個問題如果能有各式各樣的提示,訓練出來的模型就愈強大,這可以透過『資料增補』(Data Augmentation)方式,產生更多的訓練資料。除了情緒分析外,也可以應用在問答、分類...等任務。
微調的成本看似低廉,但若使用大量資料訓練,成本還是不低,網路上有人訓練一個模型花了8,000美元,因此,訓練時先小量測試,確定程序及準確性沒問題後,再使用大量訓練資料,避免荷包大失血。
另外還有一種作法『文本嵌入』(Text Embedding),我們下次再來討論嘍。
更詳細的說明可參考拙著或OpenAI官網文件。
開發者必學:OpenAI API應用與開發。
ChatGPT企業實踐指南 | 技術透析與整合應用。
深度學習PyTorch入門到實戰應用。
ChatGPT 完整解析:API 實測與企業應用實戰。
Scikit-learn 詳解與企業應用。
開發者傳授 PyTorch 秘笈
深度學習 -- 最佳入門邁向 AI 專題實戰。
 I code so I am
I code so I am
