在本文開始之前,讓我們先來探討一張圖表,該圖表詳細描述了大型語言模型的族系、演變軌跡和發表年代。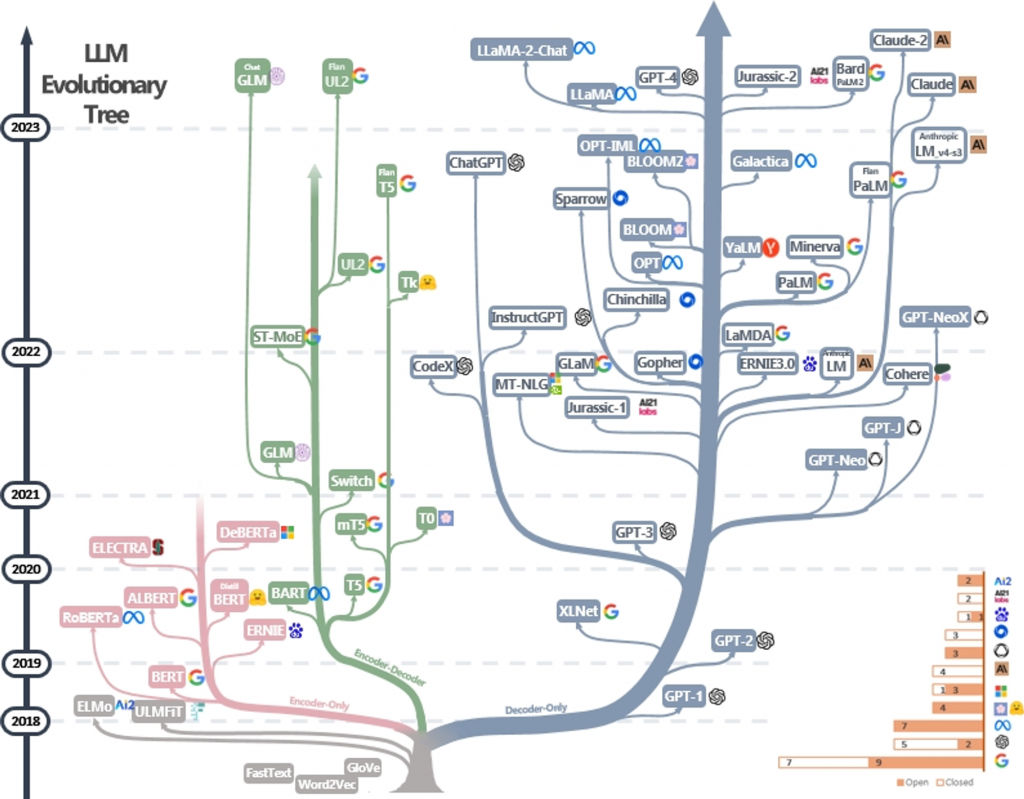
從這張圖表中,以下幾點吸引了我的注意:
基於上述觀察,我有幾個疑問:
Word2Vec 是一種專門用於建立詞向量(詞嵌入)的語言模型。其核心功能是將自然語言轉化為數學表示形式,這讓我們能夠量化各個詞彙間的相似性。舉例來說,想像我們的語言就像一個多彩的大城市,其中每個詞就是一個特定的地點。Word2Vec 的工作就是為這些地點分配座標,以便不僅可以確定每個地點的位置,還能依照不同地點間距離的遠近,探索不同地點之間的相似關係。
想像一下,Encoder-Only 語言模型就像是一位專心閱讀一本書的人。這個人(或模型)在閱讀的過程中,不斷地用大腦(或算法)對讀到的文字進行“編碼”。這個編碼過程就是一種深入解讀和理解,它將文字轉換成思考和理解的內容。
這種模型特別擅長分析詞與詞之間的關係,以及理解整個句子或段落的含義。因此,它在特定的任務或場景下表現尤為出色,例如文字分類和情感分析。
然而,Encoder-Only 語言模型有一個顯著的局限性:它不能“回答問題”或者“生成新的文字”。換句話說,它就像一個出色的閱讀者,能夠深入理解讀到的內容,但無法用自己的話來回應或創造新的敘述。
什麼是文字分類和情感分析?
文字分類:這是一種將文本訊息按照預定類別進行分類的技術。比如,這可以用來判斷一封郵件是否是垃圾郵件。
情感分析:這則是用來評估文本中隱含的情感,通常是正面、負面或中性。例如,它可以分析一篇客戶評論來判斷該評論是正面還是負面的。
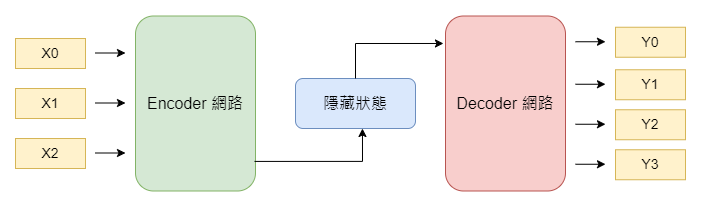
相較於 Encoder-Only 語言模型,Encoder-Decoder 語言模型更加多功能,因為它結合了編碼器(Encoder)和解碼器(Decoder)。為了讓一般人更容易理解,我們用一個簡單的比喻來解釋它的工作原理。
在 Encoder-Decoder 結構中,主要有兩個部分。首先是編碼器,其主要職責是仔細閱讀和理解你提供的文本或語音信息。接著,解碼器的工作就是將這些已經“理解”的信息轉化或翻譯成另一種形式或語言,以便讓你更易於理解。
正因為這樣的結構設計,Encoder-Decoder 語言模型特別適用於如機器翻譯、語音識別與生成,以及問答系統等多種場景。
什麼是機器翻譯、語音識別與生成、問答系統?
機器翻譯:這是自動將一種語言翻譯成另一種語言的過程。例如,將英文翻譯成中文。
語音識別與生成:語音識別是將人們說出的話轉換成文字形式。反過來,語音生成則是將文字信息轉換成聲音。
問答系統:這種系統能夠理解用戶提出的問題,並生成或選擇最合適的回答來回應。
Decoder-only 語言模型與 Encoder-Decoder 結構有所不同。這種模型並沒有編碼器(Encoder)部分,而只有解碼器(Decoder)。
為了訓練這種模型,首先會蒐集大量來源多元的文字資料,包括書籍、網站文章、新聞報導等。接著,這些文本會經過一系列前處理步驟,如分詞、移除不必要的符號和錯誤資料等。
資料清理完成後,就會進行實際的模型訓練。在訓練過程中,會從這些大量的文本資料中選取部分文字作為模型的輸入,然後使用緊接在這些文字後面的文字作為期望的輸出。舉例來說,如果有一個句子,我們可能會選擇句子的前四個字作為輸入,然後用隨後的一個字作為模型應生成的目標輸出。
訓練完成後,這個 Decoder-only 語言模型就能夠根據給定的輸入自動生成相關的下一個字或一系列字。由於模型結構的特點,它特別擅長創造性地生成文字。因此,你會經常看到它被應用在如文本生成、自動續寫和語言補全等場景。
什麼是文本生成、自動續寫、語言補全?
文本生成:這是用於創造全新文本內容的技術,如寫出新的故事、詩歌或廣告文案。
自動續寫:在這種情境下,當你輸入一個句子或短語的開頭,模型會自動生成接下來的文字以完成該句子或段落。
文字補全:這是一種文字工作的輔助功能,當你正在打字時,模型會自動預測並推薦接下來最可能出現的單詞或短語。
最後,不知道大家有沒有跟我一樣的問題,為何 Decoder-only 這麽不同?
相對於其他功能強大的語言模型,當大家第一次接觸到 ChatGPT 時,很多人像我一樣會感受到通用人工智慧(AGI)的潛力。為什麼 ChatGPT 能給人這樣的震撼呢?
首先,關鍵在於 ChatGPT 出色的文本生成能力。這是因為 ChatGPT 使用的 Decoder-Only 模型採用了自回歸(autoregressive)的生成方法,這使得模型能夠連續地生成文本。這種流暢和連貫的生成方式使其能進行更自然的對話、創作和解釋,更貼近人類自身的思考和表達模式。
其次,Decoder-Only 模型通常採用大量和多樣化的數據進行無監督學習。這種訓練方法不僅捕捉了語言的多樣性,也讓模型學習到了豐富的知識和語境,從而提升了其在各種不同任務上的適應性和通用性。
相對地,Encoder-Only 和 Encoder-Decoder 模型雖然在某些專門領域有出色的表現,但也有其自身的局限:
綜上所述,Decoder-Only 模型因其出色的生成能力和高度的通用性,往往給人留下深刻的印象,也讓人更容易想象到通用人工智慧的可能性。
以上便是大型語言模型從初期的詞嵌入技術到現代 ChatGPT 的發展歷程。我們也簡要介紹了這一過程中各個學派或流派的主要機制,以及他們之間的主要差異。雖然 ChatGPT 的崛起使大型語言模型逐漸為大眾所認識,但實際上,這個領域不僅僅限於 GPT 一種模型。希望今天的解說能讓大家對大型語言模型這個多元且深遠的世界有更全面和深入的了解。


 iThome鐵人賽
iThome鐵人賽