在我們上一篇文章中,我們提到了ChatGPT實際上在內部進行的是一種“文字接龍”遊戲。這個遊戲的運作方式和訓練機制也得到了初步的解釋。在本篇文章中,我們將深入探討這一主題。
最先,讓我們從“GPT”這三個字母開始,來了解ChatGPT的關鍵技術。作為引子,我們將以ChatGPT自己對這個問題的回答為開始。
我們可以在 ChatGPT 的回答中,注意到了幾個關鍵詞:預訓練和微調。另外,還有一個未在前文中提到,但對ChatGPT之所以強大起著重要作用的技術 - 增強式學習,這三個關鍵技術的重要概念以及彼此間的運作細節,我們將在本篇文章中一一介紹。
在上一篇文章中,我們提到可以利用網路上大量的文本資料作為機器學習的訓練材料。這些文本可以通過前後文的切割來自動生成成對的訓練資料,這樣的過程即為“預訓練”。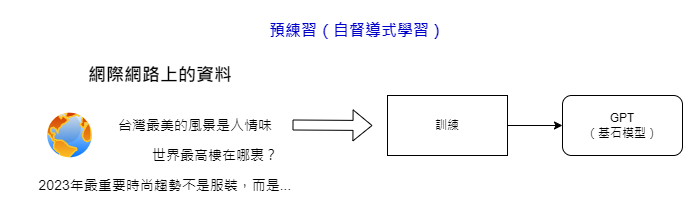
然而,這種預訓練的方法也有其局限性。以“台灣最美的是…”這句話為例,網上的回答可能多到令人驚訝。所以這個問題也就引出了一個問題:如何讓機器更精確地回答我們實際想知道的問題?這就需要進行所謂的“微調”。
我們提到過,預訓練的模型可以被視為一種“基石模型”。為了讓這個模型更能符合我們的需求,我們會在其基礎上進行微調。通過微調,當模型遇到類似的問題,比如“台灣最有名的伴手禮是什麼?”時,它將更有可能給出我們期望的答案,比如“鳳梨酥”。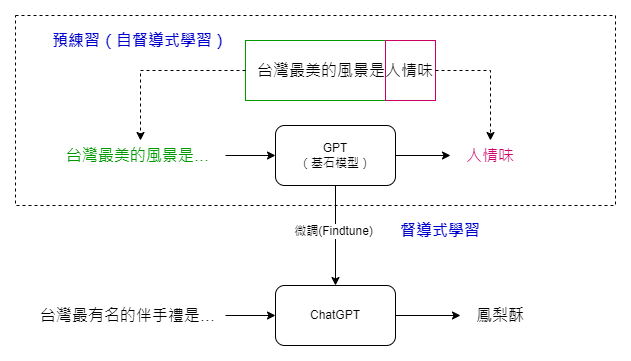
而微調詳細的運作機制,想像一下,GPT模型就像是一個初學者,通過網路上的大量文本數據已經學會了基本的人類語言和知識。但是,要讓這個“初學者”更貼近我們的需求和期望,我們需要進一步的指導。這就是人類教師參與的地方。
這些“教師”會對GPT模型生成的答案進行評分,就像在學校裡教師給學生的作業打分數一樣。收集了足夠的評分之後,我們會訓練出一個專門的“教師模型”。這個模型會理解哪些答案更受我們喜愛,哪些則不符合我們的期望。
所以,當你問ChatGPT:“台灣最美的風景是什麼?”時,它就能根據這個“教師模型”的建議,選出最合適、最符合大多數人期待的回答。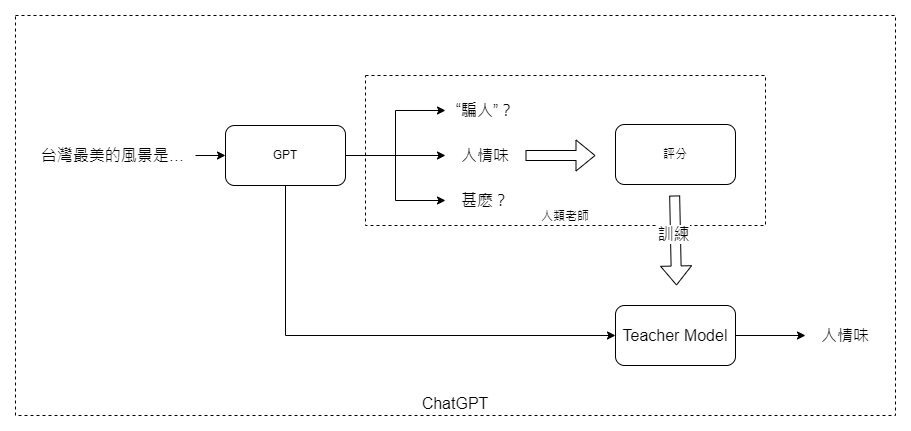
既然我們有了一個懂得評價回答的“教師模型”,下一步就是怎麼讓GPT模型更加強大。這就需要用到一個叫做“增強式學習”的高級技術。
簡單來說,增強式學習就像是一個反饋迴路。每次GPT模型給出一個答案後,教師模型會給它一個分數,這個分數就像是一個回饋訊號。GPT模型會根據這個回饋進行自我調整,就像人類根據錯誤來學習和成長一樣。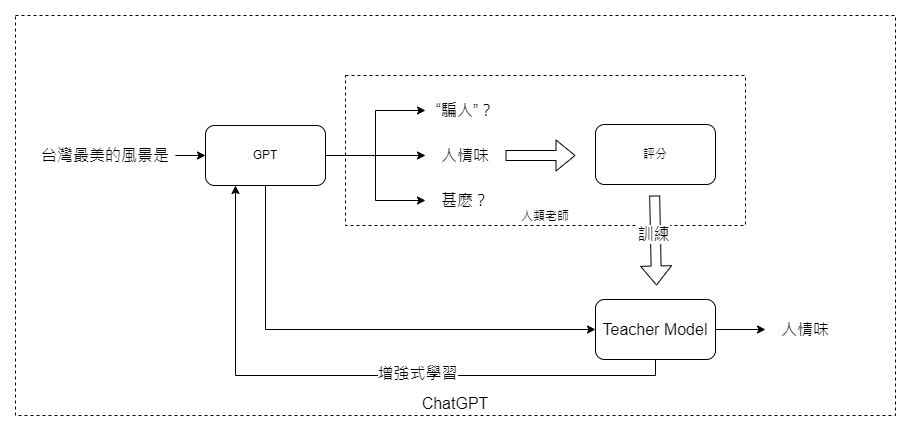
而 GPT 模型加上微調以及增強式學習後,整體的運作流程大致就會分為幾個步驟:
這樣一來,ChatGPT 就不僅僅是個會回答問題的機器,而是一個可以不斷學習和進化,更接近我們期望和需求的機器。希望本文的說明能讓你更了解這三個關鍵技術,預訓練、微調和增強式學習,是如何讓ChatGPT變得如此強大。


 iThome鐵人賽
iThome鐵人賽