今天要來介紹生成式AI的一些入門知識了,總算是進入正題了。生成式AI作為當前全球關注的技術,許多人因為這項技術受益,但也有許多人因此受害,故這些技術都是一體兩面的,是好是壞全根據使用的人而定。那究竟甚麼是生成式AI,它到底可以做甚麼?具有甚麼神力讓人們為之瘋狂?接下來我將介紹生成式AI的前世今生。
生成模型隨著時間發展現有許多框架可以使用,其中最有名的幾個模型如下:
這些模型都各有優缺點,也有獨特的特質,接著就來一個一個介紹這些模型吧。
GAN是一種由兩個神經網路組成的生成式AI模型,其中一個神經網路 (生成器, Generator)負責生成新數據,另一個神經網路 (判別器, Discriminator)負責判斷數據是真實的還是生成器生成的假資料,這兩個神經網絡互相競爭,在競爭過程中會不斷提升自己的能力,訓練目標就是使生成器能夠產生出足以欺騙判別器的數據。當生成器生出來的圖片已經逼真到判別器判斷不出來的時候就代表圖片的品質已經足夠優秀。
GAN基本上在訓練時會根據目標函數 (Objective Function)來進行優化,如下圖。目標函數基本上可算作是生成器與判別器的損失,但生成器的損失要盡量最小化 (代表生成器生成的圖片優秀,已經沒有值得學習的了);判別器的損失要最大化 (代表生成器生成的圖片優秀,判別器無法分辨圖片真假,所以會導致判斷出錯從而提高損失)。
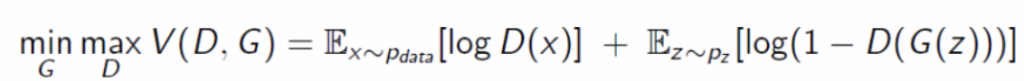
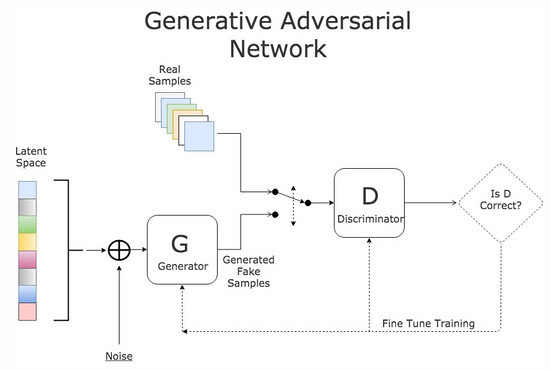
GAN的概念圖,未來會詳細介紹這個生成模型。[圖源]
GAN的優點:
GAN的優點是它可以生成高質量和多樣性的數據,而且資料及中可以不使用標籤資料。舉例來說之前做過的mnist資料集,我們不需要它的標籤資訊,僅需要將圖片資訊丟入模型中就可以訓練了。那除非是要作條件生成 (Condictional Generation)才需要使用標籤資料。
GAN的缺點:
GAN的缺點是它很難訓練,真的超難訓練 (哀怨),訓練時容易出現模式崩潰和不穩定的現象,而且訓練中難以評估生成數據的質量。我在訓練GAN真的常常發現它訓練失衡。例如生成器太弱,被判別器壓著打,根本沒辦法進步;或者判別器太弱,生成器隨便亂生成判別器也判斷不出來。
GAN可以用在甚麼地方:
GAN可以用於圖像生成、圖像轉換、圖像修復、圖像超分辨率、圖像去噪、圖像增強等。圖像轉換例如把馬的照片與斑馬的照片轉換、把圖片變成畢卡索的畫風等;圖像修復即將一張帶有瑕疵或者不完整的圖片給修復成完整圖片;圖像超分辨率是將一張低解析度的圖片轉為高解析度的圖片,例如永遠都是144p畫質的尼斯湖水怪可以使用這個技術轉換成1080p高清無碼的尼斯湖水怪 (但目前沒有實際圖片,所以生成內容還是會根據餵給AI訓練的資料集生成)。圖像去噪就是把圖片噪聲或污染物從圖像中去除,以提高圖像的品質和信噪比。圖像增強是將圖像的某些特徵或屬性進行改善或增強,以提高圖像的視覺效果和感知質量,例如把一張爬山的照片中將山上的霧氣消除並且提高照片的色彩與對比度等等。對於圖像的應用GAN真的可以做到很多事,不過還是要根據需求訓練對應的模型。
除了圖像資料以外GAN也能拿來作自然語言處理 (Natural Language Processing, NLP),與強化學習 (Reinforcement Learning, RL)搭配,應用層面可謂非常廣泛。
AE是一種由兩個神經網絡組成的生成式AI模型,其中一個神經網路 (編碼器, Encoder)負責將原始數據壓縮成低維度表示,例如一張64*64的彩色圖片,因為色彩通道是3所以一共有12288個數據,編碼器就會把它壓縮成100個數據之類的;另一個神經網路 (解碼器, Decoder)負責將低維度的數據表示還原成原始數據,就是反過來把100個數據還原成12288個數據。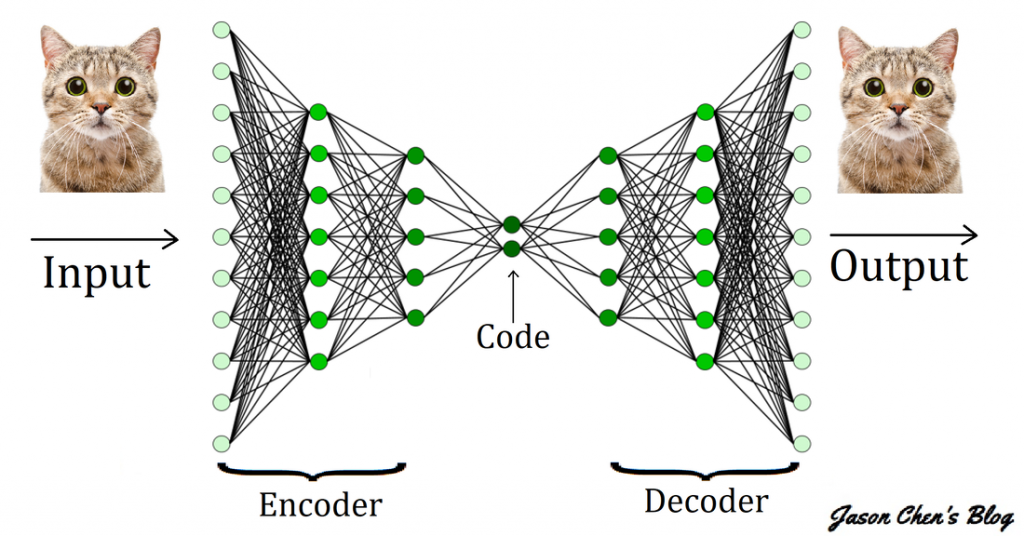
自動編碼器架構。[圖源]
AE的優點:
AE的優點是它可以學習數據的內在結構和特徵,而且可以處理不同類型的數據例如圖片,訊號資訊等等。這意味著AE可以對數據進行有效的表示和壓縮,並且可以適應不同的數據分佈和變化。同時也可以通過增加非線性或隨機性來提高其表達能力和生成能力,從而實現更複雜和更多樣的數據模型。AE還可以通過結合其他的深度學習模型來實現更高級的功能和應用,例如剛剛介紹的GAN、注意力機制 (Self Attention)等。
AE的缺點:
AE的缺點是它可能會出現過度擬合或訊息丟失的問題,而且重建的數據可能會失去細節或多樣性。因為壓縮過後的資訊難免會缺少一些資訊,有時候編碼器在將圖片編碼時就會將一些細節捨棄;且解碼器是透過一段低維資料還原成原始資料,但因為低微資料缺乏細節,所以還原後想當然在細節的把控上也有可能會有一些缺失。
AE可以用在甚麼地方:
AE可以用於數據降維、數據壓縮、數據去噪、數據生成等。例如主成分分析降維 (PCA)是一種線性的Auto Encoder,它可以用來實現數據降維;數據壓縮就是使用編碼器將數據壓縮成低維資料,這可以降低資料的佔用空間,有時候要節省空間就可以使用此方法壓縮,並竊在需要的時候在使用解碼器還原成原本的資料;有時候圖片有一些雜訊也可以用AE來將數據去噪,使用編碼器將圖片的重要訊息儲存下來,細節 (雜訊)等會捨棄,所以在解碼器還原時就可以得到去噪後的圖片;VAE是一種變分的Auto Encoder,它可以用來實現數據生成等,這個模型將低維資料轉成常態分佈的格,所以更適合做數據生成的任務。以上這些都是自動編碼器在資料處理方面的一些範例,具體情況也還是跟著任務而定,通常有很多人可以把這些技術玩得很花式。
擴散模型是近期被廣泛應用的生成模型,它可以將擴散過程反過來,而擴散過程就是指將一張圖片透過逐步加上高斯分佈之雜訊的過程,最後圖片會完全變成雜訊。將擴散過程反過來就是從雜訊逐步回復成圖片。這與一般的去噪有些差異,一般的去噪是指少量的雜訊,基本上還是看得出來圖片片原本的樣子;但是擴散模型是把完全一張雜訊反轉成圖片,大概像治好小感冒跟起死回生的差別。它可以應用於各種任務,如圖像生成、圖像去噪、圖像修復、圖像超分辨率等。基本上GAN能做到的是擴散模型也都做到。
擴散模型架構圖。[圖源]
擴散模型的優點: 它可以生成高質量和多樣性的圖像,超越了GAN的生成能力,生成的圖片其細節與整體觀感都無可挑剃,而且不需要擔心兩個模型對抗造成的訓練失衡,這讓訓練變得很穩定。而且擴散模型也可以與其他研究領域有密切的聯繫、應用,例如強化學習等。另外利用不同的擴散過程來實現不同的生成目標,如風格轉換、圖像編輯、圖像融合等也是擴散模型的一個特點。
訓練穩定是我個人覺得最心情最舒暢的事XD
擴散模型的缺點: 它的採樣速度慢,因為擴散過程中是一步一步加上雜訊的,通常需要數千個評估步驟才能抽取一個樣本,所以訓練時間會非常久,訓練時也要小心內存會不夠用,像小弟我的電腦內存常常不夠,所以只能降低訓練時的batch size。另外它的最大似然估計無法和基於似然的模型相比。而且擴散模型泛化到各種數據類型的能力較差,目前都是以圖像任務為主的。
擴散模型可以用在甚麼地方:
基本上剛剛提到的GAN中,與圖像任務有關的應用擴散模型都可以勝任。
GPT這名字很眼熟吧!去年年底openAI推出的Chat GPT就是一個GPT模型。GPT的全名是Generative Pre-trained Transformer,是一種基於Transformer架構的大型語言模型,可以生成各種類型的文本。這個模型主要是用在自然語言處理的領域的,但也不是不能用在圖片生成的領域。圖像生成的GPT基本上主要會根據給定的文字描述生成出相應的逼真圖片。
GPT的優點:
它可以生成多種不同的的內容,不僅限於文字,還可以生成包括圖像、聲音、音樂、影片等資訊格式,非常厲害。而且它還生成的圖片品質基本上都超越了其他的圖像生成模型。除此之外也可以生成多樣化的圖片,只要根據不同的文字描述,就能根據條件產生不同的風格、細節、場景等的圖片。
GPT的缺點:
它需要大量的計算資源和數據來訓練和運行,因此不適合低配置的設備,需要提供的計算資源可能不是一般人能負擔得起的。他的運算量比上述提到的幾個模型高出了幾個數量級,非常恐怖,所以現階段就只能使用那些大公司訓練出來的GPT模型,體驗看看用錢砸出來的模型到底多強。
這就是課金的威力
GPT可以用在甚麼地方:
基本上GPT可以運用的領域又更廣泛,除了上述提到的圖像生成以外,對於影片、文字、聲音的生成任務等GPT都可以一手包辦,另外結合其他工具GPT又可以做到更多事,例如製作簡報、整理文件摘要等。應用層面相當多元!單單一個ChatGPT就足以讓全世界都知道GPT模型的能力以及影響力了。
真的是非常廣泛XD
今天介紹了生成模型的基本知識以及目前較常見的幾鐘生成模型,明天會根據這些生成模型再更加詳細介紹他們的底下的分支,這些生成模型為了應付特定的任務通常會發展出各式各樣的類型。希望各位可以好好消化這些資訊,基本上比較艱深的部分會留在之後帶領各位實作的時候再介紹!初次與生成式AI見面先讓各位對生成模型有個好印象XD


 iThome鐵人賽
iThome鐵人賽