昨天建立了一個類神經網路用於分類mnist手寫圖片,也看到訓練時損失與準確率的變化,今天我們要根據訓練的情況來分析看看類神經網路的效能。其實評估模型訓練得好不好也是會根據任務類型來選擇適合的指標的,接下來就從分類任務開始,來一窺評估類神經網路的門道吧。
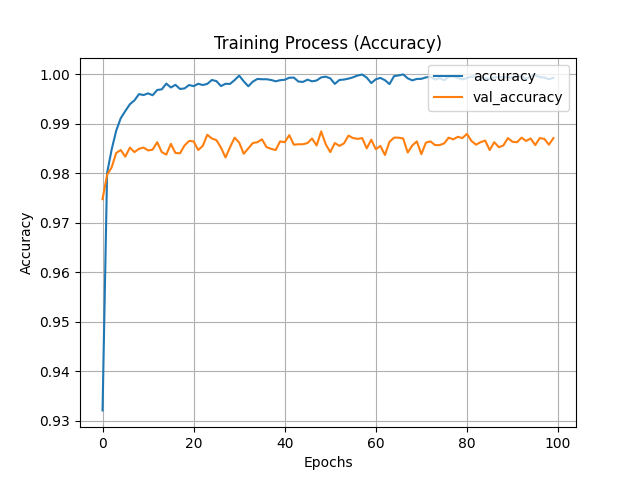
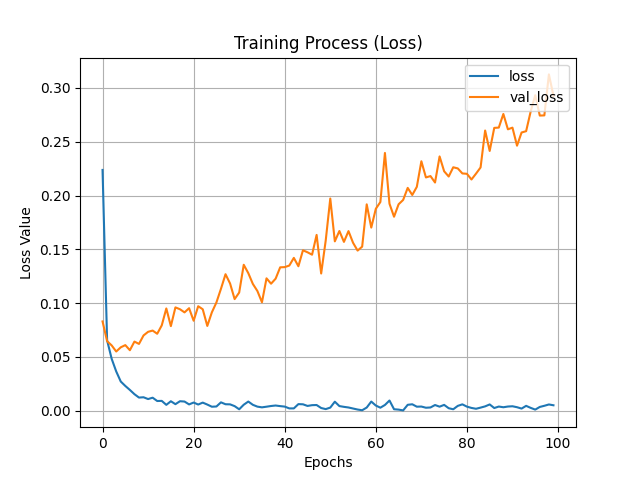
昨天訓練時的圖片長這樣,因為神經網路有牽扯到機率分布等概念,所以每次的結果可能都不同,若結果跟我有些微不同則無須擔心。從準確率來看都可以發現大約在訓練20次時訓練與驗證集變化就不明顯了,也就是說在訓練到20步時模型基本上就已經收斂了,這時再增加訓練次數也無濟於事。損失可以看到驗證集損失有提升的趨勢,這代表模型訓練已經有一點過擬合了 (over-fitting),這時可以考慮降低訓練次數。
過擬合的成因很多,基本上可以分為以下幾種成因:
資料集可能不平衡 (imbalanced),也就是說某一個類別的數量遠多於其他類別 (例如類別1的圖片有50000張,其他9個類別一共10000張)。這樣的話,模型可能會傾向於預測這個類別,從而提高準確率,但會降低其他指標,如召回率 (recall)或F1-score。
因為是Tensorflow他們整理過的資料集,故基本上不會是這個原因。
損失函數可能不太適合任務類型。例如今天使用交叉熵(cross-entropy)作為損失函數,那麼當模型對某一個類別的信心很高時,即使預測錯誤,也會產生很大的損失值。這可能導致驗證損失提高,但基本上這不影響準確率。
⚠️本次的程式成因比較像是這個原因,但這不是說交叉熵不適合,只是使用這個損失函數就可能會發生這個問題。結論來說結果是好的就好了!
驗證集可能資料太少或資料品質差。這可能導致驗證結果不穩定或不可靠。
因為是Tensorflow他們整理過的資料集,故基本上也不會是這個原因。
若要解決過擬合的原因的話,以下也有幾種方向可以提供給各位下手:
增加數據集的大小或多樣性,或者使用數據增強(data augmentation)來創造更多的數據。
減少模型的複雜度或參數數量,例如減少隱藏層的數量或大小。
使用正規化 (Regularization)或丟棄 (Dropout)等技術來限制模型的自由度或抑制過度學習。 這兩個都是Keras有網路層可以運用的,方式如下:
x = BatchNormalization(momentum=0.8)(x) #批次正規化,momentum代表動量
x = Dropout(rate=0.5)(x) #隨機丟棄層,rate代表要丟棄的比例
批次正規化 (BatchNormalization)是會將每一批資料都進行正規化已讓資料分布的均值為0、變異數為1,以加速訓練、提高模型泛化能力。momentum參數是控制這層的運行均值與運行變異數的更新速度,這個值越大則更新速度慢;值越小則更新速度快。
丟棄層 (Dropout)會將每層輸出做隨機丟棄,rate是丟棄的比例,如果設定0.5代表輸出資料會有50%變成0,有點像薩諾斯彈指這樣。隨機丟棄資料的用意也是為了提高模型的泛化能力,使其不容易過擬合。
使用提早結束訓練(early stopping)等技術來在適當的時候停止訓練,避免模型在訓練集上過度學習,並且過擬合。
分類任務通常會分為兩類:
多類別分類 (Multi-Class Classification)
這個是指每筆資料只能屬於一個類別,例如昨天的mnist辨識,每張圖片只代表一個數字。
常用的評估指標有準確率(accuracy)、混淆矩陣(confusion matrix)、F1-score等等。
多標籤分類 (Multi-Label Classification)
這個是指每筆資料可以屬於多個類別,例如圖片標註,一張圖片包含狗跟貓,分類就可以被歸類為狗、貓兩個類別。
常用的評估指標有準確率 (Accuracy)、精確率 (Precision)、召回率 (Recall)、Hamming loss等等。
因為昨天做的是多類別分類的任務,所以今天會帶各位實作混淆矩陣,混淆矩陣是可以很明確地看出模型分類的預測值與真實值的差距,簡單來說如下表。可以看到真實標籤0而模型預測1的case有兩個;真實標籤1而模型預測為0的有一個,這樣就可以非常直觀的觀察到模型的分類預測情況了!不過今天的標籤有10個,所以混淆矩陣共有10行&10列。
| 混淆矩陣範例 | 真實標籤 0 | 真實標籤 1 |
|---|---|---|
| 模型預測 0 | 48個 | 1個 |
| 模型預測 1 | 2個 | 49個 |
接下來就開始介紹程式吧。
混淆矩陣可以使用sklearn去建立,接著使用matplotlib去將之繪圖出來。
sklearn也是pip下載就好了!
pip install sklearn==1.1.1
首先我們先用測試資料集來考考昨天訓練的模型吧,直接使用model.predict(x_test)就可以針對測試資料做預測了喔。詳細部分可以看看昨天的文章喔。
另外混淆矩陣輸入的資料是原本的標籤資料,不是經過one-hot轉換的喔。這點要注意,所以我們要使用tf.argmax()去尋找輸出機率最大的是對應哪個類別 (tf.argmax()這個方法使用來找最大值的索引值,因為mnist的類別跟索引值一樣,類別0索引值就是0,以此類推,故可以直接應用),axis=1代表沿著列的方向 (即每一筆預測結果)去找最大值。
import tensorflow as tf
y_pred = model.predict(x_test)
y_pred = tf.argmax(y_pred, axis=1)
print(y_pred[:10])
print(y_test[:10])
接著就是畫出混淆矩陣啦
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y_test, y_pred) #建立混淆矩陣
plt.imshow(cm, cmap=plt.cm.Blues) #以藍色風格畫出混淆矩陣
plt.title('Confusion Matrix of Model Predict')
plt.colorbar() #圖片右側的直條,可以根據顏色判斷這個區塊的數量多不多
#接著設計一下刻度(ticks)的值與內容
plt.xticks([i for i in range(10)], ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'])
plt.yticks([i for i in range(10)], ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'])
#幫x, y軸取名字
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
#把混淆矩陣的內容寫進每個區塊中
for i in range(10):
for j in range(10):
plt.text(j, i, cm[i, j], ha='center', va='center')
plt.show()
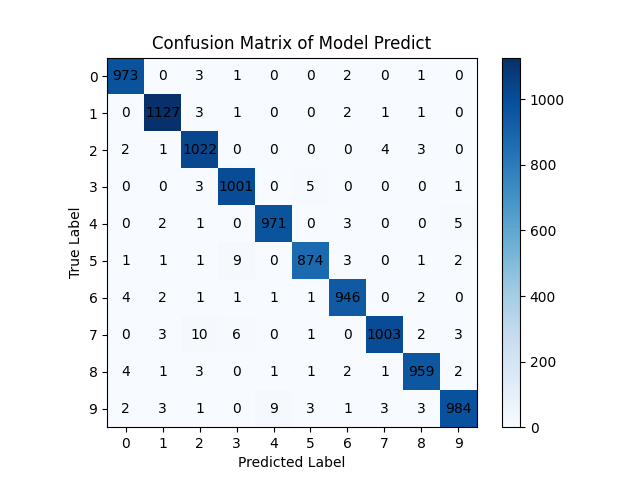
大功告成,接著可以看到把7看成2跟3、把5看成3,把9看成4都是比較常出現的錯誤。分析完錯誤後接著就可以根據這些資訊去考慮新增7、5、9的資料並給神經網路訓練 (但要小心過擬合原因2),或者改變網路層或者訓練的參數等 (比較推薦從這邊下手)。我做AI科學研究大部分時間都在調整參數🥲但訓練出一個好模型得到的成就感也滿滿。
除了分類任務以外,還有很多不同的任務,例如迴歸任務通常會使用MSE與MAE當作評估指標 (他們同時也是損失函數)。除此之外也可以使用這些指標:
除此之外機器學習也有許多任務,雖然與深度學習有點差異,但我就順便整理一下吧!機器學習包含分類與回歸,但除此之外也有分群、降維等任務。這些任務比較不常用深度學習模型去訓練。
分群是一種非監督式學習的任務,目的是將資料分成幾個相似的群組,例如 K-means、DBSCAN 等演算法。這項任務的訓練指標有:
降維也是一種非監督式學習的任務,它的目的是把高維度的數據轉換成低維度的數據 (例如資料特徵有5個,降維可以從中萃取出3個特徵以用來訓練),這樣做可以減少計算量,提取重要特徵等。較常用的有PCA、SVD等演算法。這個任務有以下幾種常見的指標:
講了那麼多其他的東西終於要進入正題了,圖片生成任務有沒有指標,當然有。而且都還蠻先進的,這邊會簡單介紹一下,之後也會帶各位實作。有些指標比較容易實現,但有些則需要花費較多心思才能實現,不過未來我都會將我所知介紹給各位。敬請期待!圖片生成任務的指標如下,這些指標的名字我都覺得很酷XD:
MSE與MAE:這兩個指標也可以計算與生成圖片與原始圖片每一個像素差的總和,若是0則代表兩張圖片完全一樣。不過我不推薦這個,因為這兩個指標只能反映圖像之間的數值差異,而不能反映圖像之間的結構等相似性。
結構相似性指數 (Structural Similarity Index, SSIM):這是一種用來評估圖片生成模型的指標,計算的是原始圖片和生成圖片之間的結構相似性,考慮了亮度、對比度和結構三個因素,可以反映圖片的視覺品質,值越接近1,表示生成圖片越像原始圖片。
峰值訊噪比 (Peak Signal-to-Noise Ratio, PSNR):這是一種用來評估圖片生成模型的指標,計算的是原始圖片和生成圖片之間的MSE,並轉換成分貝的形式,可以反映圖片的訊噪比,值越大,表示生成圖片越像原始圖片。
感知失真指數 (Perceptual Distortion Index, PDI):這是一種用來評估圖片生成模型在感知上的指標,計算的是原始圖片和生成圖片之間的感知失真程度。這個指標考慮了人類視覺系統對不同頻率和方向細節的敏感度,可以反映圖片的感知品質,值越小,表示生成圖片越像原始圖片。
Learned perceptual image patch similarity (LPIPS):這個指標是基於深度學習模型的特徵提取和映射來判斷圖片的品質。因為是使用深度學習模型當作特徵提取方法,所以並計算公式比較複雜。由此可知深度學習模型還可以被訓練來當作深度學習模型的訓練指標 (非常拗口)。
KID (Kernel Inception Distance)和FID (Fréchet Inception Distance):這兩個都是用於評估生成模型生成圖像品質的指標,它們都是基於Inception網路的特徵表示來度量生成圖像和真實圖像之間的距離 (又是使用深度學習模型來進行特徵萃取)。FID假設特徵表示服從正態分佈,並計算Fréchet Distance;KID則是計算特徵表示之間最大均值差異 (MMD)的平方。
KID比起FID有一些優勢,例如不需要假設常態分佈,有一個無偏估計值,可以更一致地匹配人類的感知。這些部分未來會更加詳細介紹。
除了PDI我尚未實做過以外,其他生成指標我都有做過,未來會以實際經驗帶各位建立這些指標!
今天帶各位分析了神經網路的效能,可以看到有許多評量方法,藉由這些評量方法我們可以訓練出最佳的模型。生成式AI的基本知識大致介紹到此,明天開始會進入正題介紹生成式AI的基礎等等,請注意前方逐漸高能。未來也會帶各位實作生成模型與圖像生成任務指標,也請各位敬請期待!


 iThome鐵人賽
iThome鐵人賽