pytorch 提供一些方法來抓取電腦上有的裝置:
torch.cuda.is_available():檢查電腦是否有可以使用cuda的硬體,若有會回傳True否則回傳False
torch.backends.mps.is_available():檢查電腦是否有Metal GPU,若有會回傳True否則回傳False
# 取得要運算的裝置
# NVIDIA的話會顯示cuda,因為我使用Mac的M2晶片,因此會顯示mps裝置
if torch.cuda.is_available():
device = "cuda"
elif torch.backends.mps.is_available():
device = "mps"
else:
device = "cpu"
print(f"Using {device} device")

要建立模型我們要先定義類別,此類別繼承 nn.Module,繼承的概念可以理解為複製別人寫好的程式碼,並使用要用到的內容。此處定義的類別包含兩個函數,初始化 __init__ 函數定義了模型的樣子,forward函數定義了前向傳播的過程。
這邊很多專業術語不懂沒關係,後續會慢慢介紹。
# 新增一個自定義的Class
# 繼承 nn.Module
class PeterNeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
# flatten 將輸入的展開成一維的向量(原本圖像可能是2或3維)
self.flatten = nn.Flatten()
# 建立神經網路
# 此處為三層的神經網路
# Relu為激勵函數
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
# 此函數用來前向傳播
# 此過程就是把圖片輸入到model到最後輸出一個結果
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
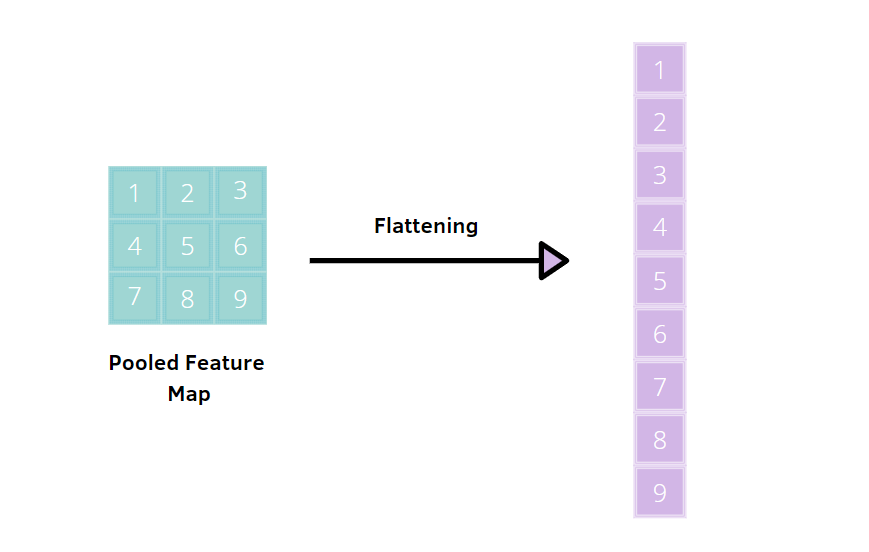
Flatten的示意圖
定義好類別需要將其建立成物件,此時也會選擇要運行此模型的裝置(第一小節有指定要用哪個裝置運行)。
# 實例化 PeterNeuralNetwork 物件到 M2 晶片中
peter_model = PeterNeuralNetwork().to(device)
print(peter_model)
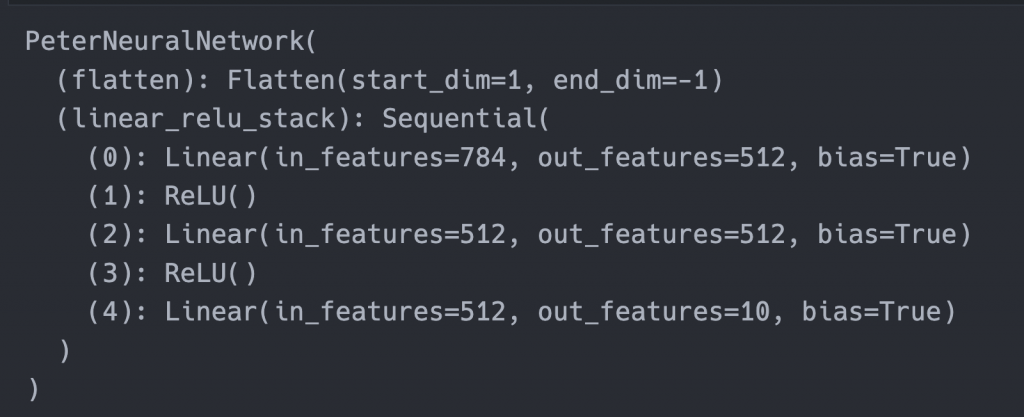
將peter_model輸出到會顯示出模型的架構:
將模型畫出來的樣子大概會是長這樣: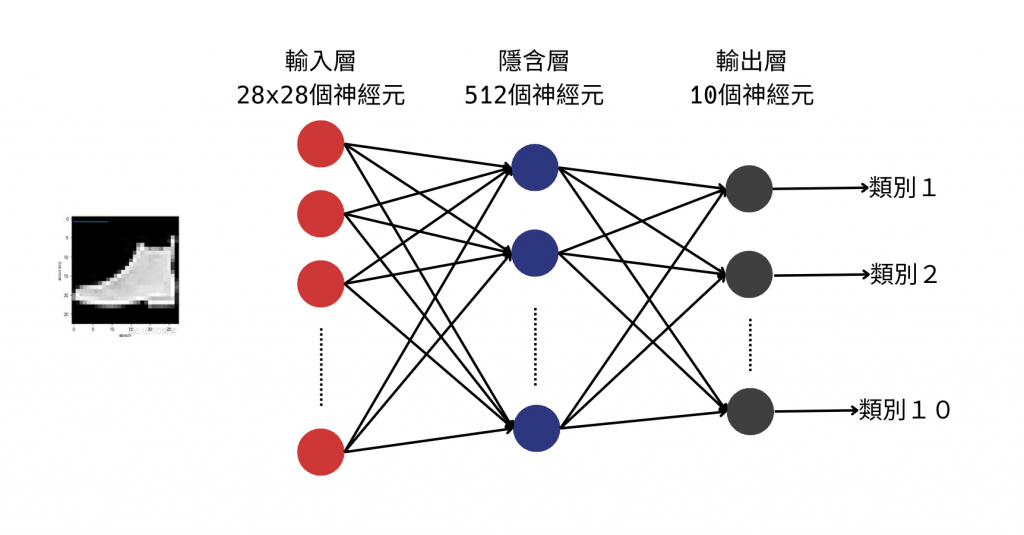
這次我們說明了如何建立模型,昨天、今天章和後面幾天會先把Pytorch整個架構的流程講過一次,後續會說明這些專業術語的用途。
個人學習的心得是第一次一定是矇矇懂懂的,玩過幾次資料就會對整個架構越來越理解,所以別放棄繼續努力吧~
提問~什麼是層數?
我的解釋:
深度學習是神經網路的一種,透過每一層萃取特徵來做出預測,以圖像處理來說,第一層會找到邊邊角角、第二層可能會找到耳朵的些微形狀,可以參考以下的圖方便理解(每一列都是一層)。
現在的神經網路通常都超過三層,因此又被命名為比較炫砲一點的深度學習。
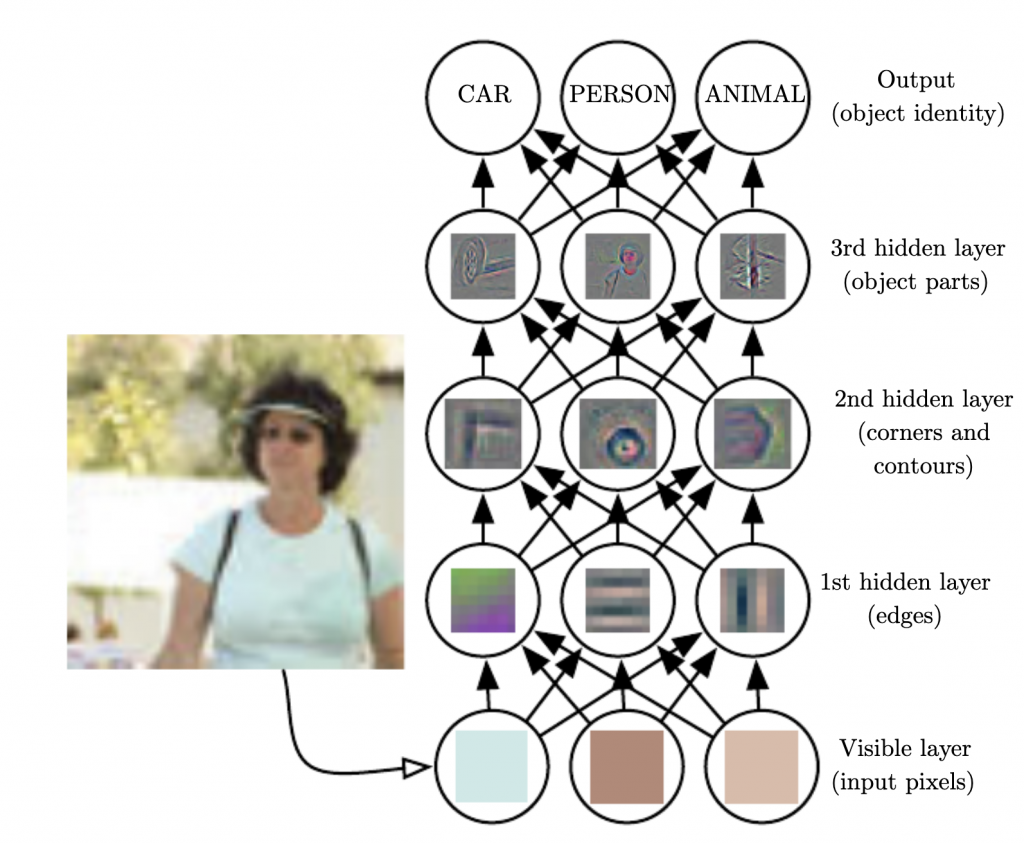
後面對女友疑問(層數)的講解很平易近人,讓人一下就能理解,是行走的深度學習專業術語的字典吧~
謝謝你的誇獎,其實我一時也回答不上來,是去查了資料才能回答的

