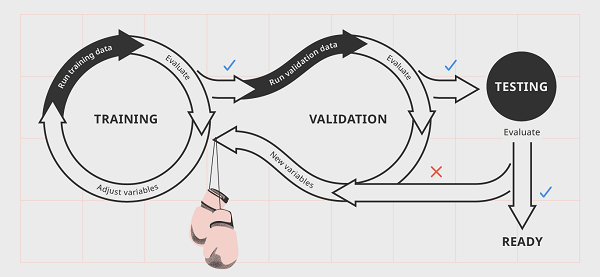
要產生機器學習的模型會有下面幾個步驟,深度學習是機器學習的一種,因此產生模型的過程也會與這些步驟相似:
訓練:隨機初始化參數,根據每次結果的好壞來調整模型。
驗證:overfitting是機器學習很容易發生的情形,指的是模型在訓練資料上可以表現得很好,但是在真實情境下卻沒那麼好,如果用考試來比喻,就是我們完全把參考書答案背下來了,但是我們沒有學到考試真正的含義,因此真的面對考試就會回答得不好,通常我們會將可以訓練的資料分成訓練集和驗證集。
測試:模型處理真實資料的情況,若是在產品或工廠可能會有Phase1、2等,觀察模型表現得好不好,若是沒問題就會正式生產。
日後文章會詳細介紹,此處先解釋這兩個參數的用途:
loss function:用來評估模型的好壞。
optimizer:每次往好的地方修正多寡。
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
這邊定義一個函數來執行訓練的流程,傳入的參數分別是:
dataloader: 讀取的資料,詳細可以參考Day 4 透過 Pytorch 中的 torchvision 讀取資料。
model:設計好的模型,詳細可以參考Day 5 使用Pytorch建立模型。
loss_fn:上一節定義的損失函數。
optimizer:上一節定義的優化器。
訓練的流程會有以下幾個過程:
將資料輸入到模型中
資料的向量跟每一層神經網路做運算最後得到一個結果。
使用損失函數來看這個結果好不好(機器有沒有答對)。
反向傳播,使用損失函數的梯度來更新權重,使得下次模型可以預測更準。
def train(dataloader, model, loss_fn, optimizer):
# len()函數可以查看dataloader中有多少筆資料
size = len(dataloader.dataset)
# 將模型設定為訓練模式(模型有訓練和驗證模式,訓練模式會開啟一些幫助訓練的方法)
model.train()
# 此迴圈會將 dataloader中的資料跑過一遍
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# 將X(圖片)餵給模型,模型最後會預測一個結果
pred = model(X)
# 使用損失函數來看這次預測的好壞
loss = loss_fn(pred, y)
# 根據損失函數來進行優化
loss.backward()
optimizer.step()
# 反向傳播是透過梯度進行優化,每次優化好之後我們需要將梯度歸零
optimizer.zero_grad()
# 每一百次show一次當前的模型的狀態
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
測試的過程會有以下幾個步驟:
將資料輸入到模型中。
資料的向量跟每一層神經網路做運算最後得到一個結果。
輸出每個class的數值,並挑選最大的數值作為模型回答的答案。
計算這一次所有資料的平均損失和正確率。
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
# 將模型設定為估計模式
model.eval()
test_loss, correct = 0, 0
# 此段模型只用來預測結果,不進行訓練,因此不用紀錄梯度
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
# 將損失函數加總
test_loss += loss_fn(pred, y).item()
# 若是這次答對,correct數量+1
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
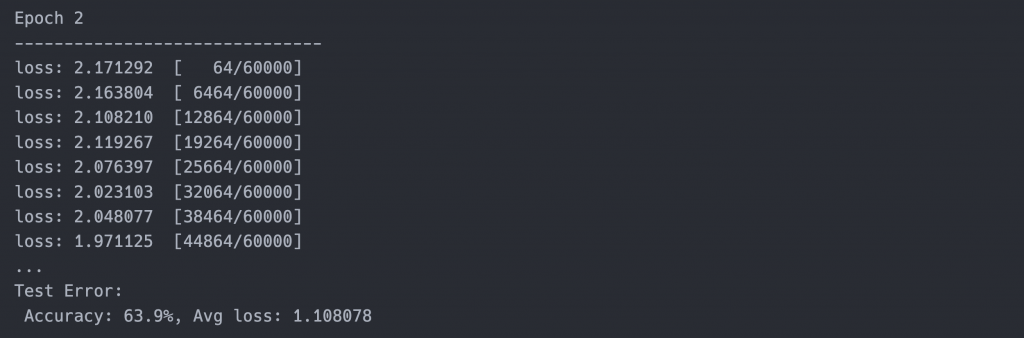
最後我們要運行剛剛寫的程式,epoch代表整筆資料要訓練幾次,以FashionMNIST來說總共有60000筆資料,我們設計每次會讀取64筆,當所有資料被讀過一次則代表一個epoch。
epochs = 5
# 總共跑5個epochs
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
# 訓練模型
train(train_dataloader, peter_model, loss_fn, optimizer)
# 測試模型
test(test_dataloader, peter_model, loss_fn)
print("Done!")
執行完5個epochs可以發現準確率有63%,有空的話可以嘗試調高epochs數來看準確率是不是可以更高哦!
本次介紹訓練和測試的流程,其中有提到一些參數(loss function, optimizer等等),這些可以先了解他的作用,後續的文章會說明這些參數的細節,明天會介紹如何把模型存下來和如何運用模型,Day4~Day7快速的將深度學習訓練的過程講過一遍,因此似懂非懂是很正常的!!接下來會針對每個細節介紹,透過資料集實作來更理解深度學習如何運作。

