昨天介紹了一些在生成對抗網路 (GAN)會常遇到的問題,以及可能的解決辦法,要提升GAN的訓練穩定性也有許多方法,例如使用WGAN等。那也因為本系列是圖像生成的任務,所以還是得使用以圖像處理為主軸的卷積神經網路 (Convolution Neural Network, CNN),並使用這層神經網路為主軸建立一個Deep Convolutional Generative Adversarial Networks (DCGAN)。在實作之前先來了解一下DCGAN的一些細節吧。
DCGAN是一個使用深度卷積為主架構的GAN模型。它比普通的GAN更能提取圖片的特徵等細節,故生成能力會比使用普通全連接層 (Dense)的GAN要來的優秀。另外也因為CNN訓練參數比單純Dense層來的少一點,所以訓練速度基本上會比較快。
DCGAN在模型架構上通常會用3層以上的卷積處理,如下圖,可看到圖片下方DCGAN的生成器架構使用了四層CNN層,並且輸出層也是使用CNN直接輸出圖片。雖然圖片中只有描述生成器的架構,不過通常為了平衡訓練,在簡單的GAN中,生成器與判別器的架構並不會差太多。所以看生成器架構如何,判別器架構大致上也就那樣了!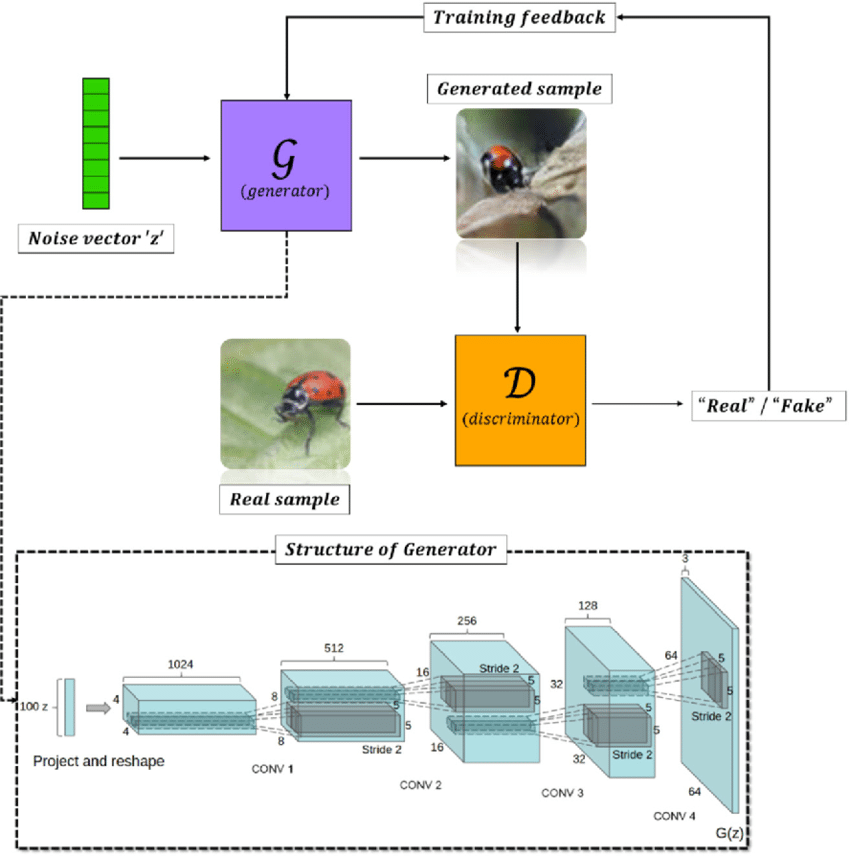
DCGAN訓練架構。[圖源]
其他的訓練目標,目標函數基本上與原始的GAN完全相同,因為只是網路架構被替換而已,是相當簡單的一個GAN種類。
DCGAN在建立時根據其原始論文有幾項原則:
但我的經驗是似乎使用LeakyReLU、ReLU作為激活函數與輸出層使用Tanh跟Sigmoid作為激活函數的效果差別不大,所以在簡單的任務中激活函數的使用上會比較彈性。除此之外也有許多變種的ReLU函數可以使用,例如ELU函數、SeLU函數、GELU函數、Swish函數等,相當多選擇,但最常見還是以LeakyReLU、ReLU為主。
這些函數也給各位看看長怎樣,有興趣的話TensorFlow可以直接使用這些函數:
from tensorflow.keras.activations import elu, selu, gelu, swish
y = elu(x) # 將x作為輸入並計算elu(x)
ELU函數圖: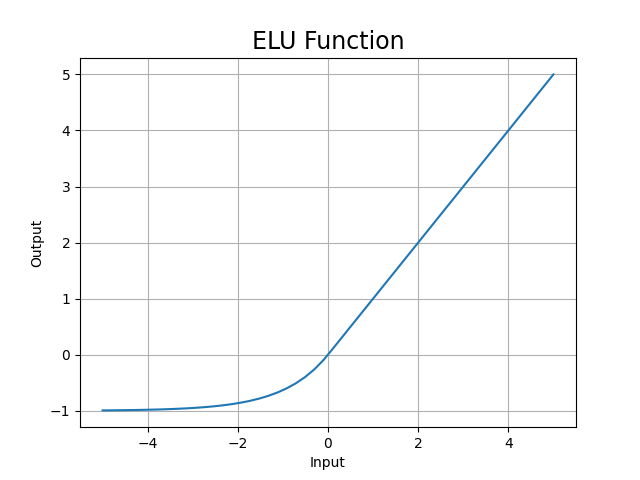
SELU函數圖: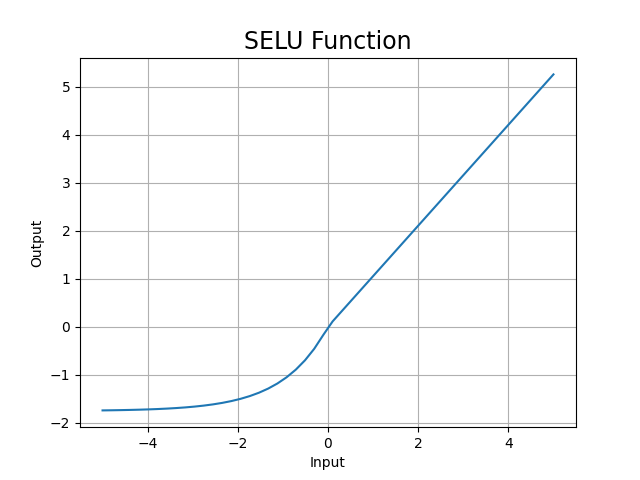
GELU函數圖: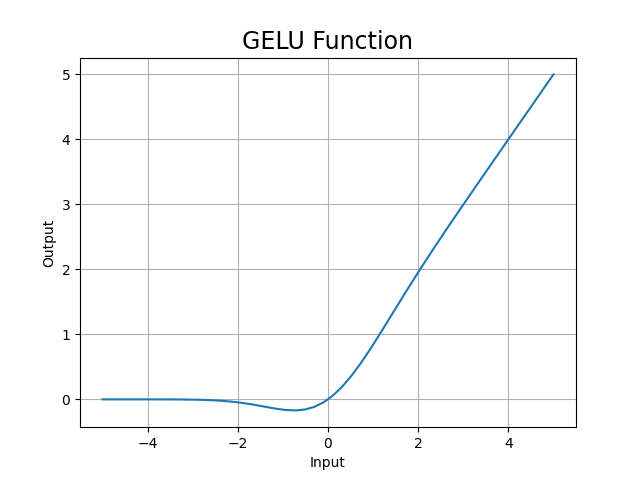
Swish函數圖:
今天向各位介紹了DCGAN,DCGAN是一個比較簡單的GAN模型,所以並沒有太多的細節。明天會帶各位實作DCGAN模型,並同樣生成mnist資料集。但因為任務簡單所以在生成圖片時結果並不會有太大的差異,希望各位可以先了解簡單的生成網路,之後再一步一步慢慢將網路複雜化。DCGAN也很常被用來作動漫人物的頭像生,各位有興趣也可以去玩玩看喔~

