昨天介紹了DCGAN,這個GAN主要是使用卷積層來當作模型的主架構,今天會實際帶各位實作一次DCGAN,並且分析模型的訓練成果。因為資料處理的部分都寫過了,有許多內容就會快速帶過~接著就直接來看程式吧。
我們一樣使用第9天分享的SOP來DCGAN建立模型。
任務類型很簡單就是生成mnist圖像資料,使用的模型為DCGAN。
這一步會匯入函式庫,因為會使用CNN,所以也要匯入相關的網路層:
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, BatchNormalization, LeakyReLU, Activation, Conv2DTranspose, Conv2D
from tensorflow.keras.models import Model, save_model
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
import os
這一步在第九天也介紹過了,但因為生成器輸出的激活函數是tanh,這個函數的值域會落在-1~1之間,所以對資料集中的數據也要轉成-1~1之間。
def load_data(self):
(x_train, _), (_, _) = mnist.load_data() #底線是未被用到的資料,可忽略
x_train = x_train / 127.5 - 1 #正規化
x_train = x_train.reshape((-1, 28, 28, 1))
return x_train
這邊就與之前介紹的沒什麼差別了 (只有改變類別名稱為DCGAN而已),以及資料的儲存都存到DCGAN資料夾中。程式碼如下:
class DCGAN():
def __init__(self, generator_lr, discriminator_lr):
self.generator_lr = generator_lr #生成器學習率
self.discriminator_lr = discriminator_lr #判別器學習率
self.discriminator = self.build_discriminator() #生成器
self.generator = self.build_generator() #判別器
self.adversarial = self.build_adversarialmodel() #對抗模型
#紀錄生成器與鑑別器損失
self.gloss = []
self.dloss = []
if not os.path.exists('./result/DCGAN/imgs'):# 將訓練過程產生的圖片儲存起來
os.makedirs('./result/DCGAN/imgs')# 如果忘記新增資料夾可以用這個方式建立
這一步同樣會建立生成器、判別器、對抗模型以及訓練的方法,訓練步驟與原始的GAN沒有差異。
生成器:生成器輸入依然是一段隱向量雜訊,雜訊輸入後會經過一般Dense層把輸出變為7x7x32長度的向量再Reshape成(7, 7, 32)的形狀接著再經過CNN計算,最後輸出一張圖片。
根據我的經驗生成器使用ReLU與LeakyReLU都差不多,各位也可以多實驗看看看效果如何
def build_generator(self):
input_ = Input(shape=(100, ))
x = Dense(7*7*32)(input_)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Reshape((7, 7, 32))(x)
x = Conv2DTranspose(128, kernel_size=2, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Conv2DTranspose(256, kernel_size=2, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
out = Conv2DTranspose(1, kernel_size=1, strides=1, padding='same', activation='tanh')(x)
model = Model(inputs=input_, outputs=out, name='Generator')
model.summary()
return model
判別器:判別器也是一樣使用CNN網路判斷該張圖片是真是假,但是經過我的調整發現在判別器中使用批次正規化會導致模型訓練到最後梯度小到幾乎無法優化,看起來也是梯度消失,所以判別器中並未使用批次正規化。
def build_discriminator(self):
input_ = Input(shape = (28, 28, 1))
x = Conv2D(256, kernel_size=2, strides=2, padding='same')(input_)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(128, kernel_size=2, strides=2, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(64, kernel_size=2, strides=1, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Flatten()(x)
out = Dense(1, activation='sigmoid')(x)
model = Model(inputs=input_, outputs=out, name='Discriminator')
dis_optimizer = Adam(learning_rate=self.discriminator_lr , beta_1=0.5)
model.compile(loss='binary_crossentropy',
optimizer=dis_optimizer,
metrics=['accuracy'])
model.summary()
return model
對抗模型:對抗模型一樣將生成器與判別器接在一起,注意要將判別器的權重固定住喔!
def build_adversarialmodel(self):
noise_input = Input(shape=(100, ))
generator_sample = self.generator(noise_input)
self.discriminator.trainable = False
out = self.discriminator(generator_sample)
model = Model(inputs=noise_input, outputs=out)
adv_optimizer = Adam(learning_rate=self.generator_lr, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=adv_optimizer)
model.summary()
return model
訓練步驟:
訓練步驟與第10天介紹的一樣,因為DCGAN與GAN的訓練方式真的一模一樣,不同之處只有模型架構而已,所以這邊就不贅述了,只放上程式碼。若對GAN的訓練方式有問題可以看看註解或者回去看看第10天的內容喔。
def train(self, epochs, batch_size=128, sample_interval=50):
# 準備訓練資料
x_train = self.load_data()
# 準備訓練的標籤,分為真實標籤與假標籤
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# 隨機取一批次的資料用來訓練
idx = np.random.randint(0, x_train.shape[0], batch_size)
imgs = x_train[idx]
# 從常態分佈中採樣一段雜訊
noise = np.random.normal(0, 1, (batch_size, 100))
# 生成一批假圖片
gen_imgs = self.generator.predict(noise)
# 判別器訓練判斷真假圖片
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
#儲存鑑別器損失變化 索引值0為損失 索引值1為準確率
self.dloss.append(d_loss[0])
# 訓練生成器的生成能力
noise = np.random.normal(0, 1, (batch_size, 100))
g_loss = self.adversarial.train_on_batch(noise, valid)
# 儲存生成器損失變化
self.gloss.append(g_loss)
# 將這一步的訓練資訊print出來
print(f"Epoch:{epoch} [D loss: {d_loss[0]}, acc: {100 * d_loss[1]:.2f}] [G loss: {g_loss}]")
# 在指定的訓練次數中,隨機生成圖片,將訓練過程的圖片儲存起來
if epoch % sample_interval == 0:
self.sample(epoch)
self.save_data()
首先定義隨機生成圖片的副程式,與第10天介紹的不同,這一次會將sample(epoch)與predict()方法合併起來,讓程式碼更簡潔:
def sample(self, epoch=None, num_images=25, save=True):
r = int(np.sqrt(num_images))
noise = np.random.normal(0, 1, (num_images, 100))
gen_imgs = self.generator.predict(noise)
gen_imgs = (gen_imgs+1)/2
fig, axs = plt.subplots(r, r)
count = 0
for i in range(r):
for j in range(r):
axs[i, j].imshow(gen_imgs[count, :, :, 0], cmap='gray')
axs[i, j].axis('off')
count += 1
if save:
fig.savefig(f"./result/DCGAN/imgs/{epoch}epochs.png")
else:
plt.show()
plt.close()
接著定義儲存訓練資料的副程式save_data(),這邊都與前幾天介紹的幾乎一樣,只是把資料夾名稱改成DCGAN而已XD:
def save_data(self):
np.save(file='./result/DCGAN/generator_loss.npy',arr=np.array(self.gloss))
np.save(file='./result/DCGAN/discriminator_loss.npy', arr=np.array(self.dloss))
save_model(model=self.generator,filepath='./result/DCGAN/Generator.h5')
save_model(model=self.discriminator,filepath='./result/DCGAN/Discriminator.h5')
save_model(model=self.adversarial,filepath='./result/DCGAN/Adversarial.h5')
這次訓練的參數設定如下:
| 參數名稱 | 參數值 |
|---|---|
| 生成器學習率 | 0.0002 |
| 判別器學習率 | 0.0002 |
| Batch Size | 128 |
| 訓練次數 | 20000 |
if __name__ == '__main__':
gan = DCGAN(generator_lr=0.0002,discriminator_lr=0.0002)
gan.train(epochs=20000, batch_size=128, sample_interval=200)
gan.sample(save=False)
這次訓練的損失其實視覺效果上看起來還蠻漂亮的,一樣使用log(x+1)來壓縮一下圖片的數值。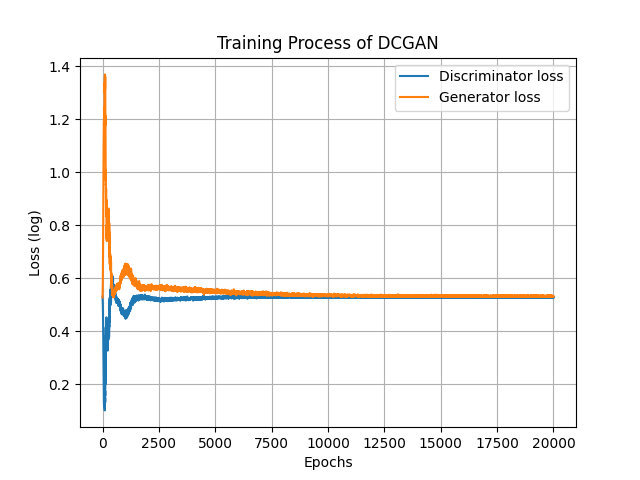
另外也給各位看看訓練過程中產生的圖片,總得來說似乎比一般的GAN更快學習到圖片的特徵。
Epoch=200:
Epoch=2000:
Epoch=5000,此時數字雛型已經出來了:
Epoch=15000,此時訓練已經差不多達到平衡了,不過有些結果還是有小瑕疵,但總得來說效果還算優秀:
訓練的圖片變化:
今天帶各位實作了DCGAN,在我看來DCGAN也會有許多訓練問題,不過這些都是可以被克服的。例如明天要介紹到的WGAN,這個GAN的變種使用了全新的目標函數,雖然數學公式會比較複雜,但希望我能盡力解釋讓大家都能聽懂。各位也可以實作看看DCGAN,並用它來生成不同資料集中或者自己蒐集的圖片喔!
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, BatchNormalization, LeakyReLU, Activation, Conv2DTranspose, Conv2D
from tensorflow.keras.models import Model, save_model
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
import os
class DCGAN():
def __init__(self, generator_lr, discriminator_lr):
self.generator_lr = generator_lr
self.discriminator_lr = discriminator_lr
self.discriminator = self.build_discriminator()
self.generator = self.build_generator()
self.adversarial = self.build_adversarialmodel()
self.gloss = []
self.dloss = []
if not os.path.exists('./result/DCGAN/imgs'):# 將訓練過程產生的圖片儲存起來
os.makedirs('./result/DCGAN/imgs')# 如果忘記新增資料夾可以用這個方式建立
def load_data(self):
(x_train, _), (_, _) = mnist.load_data() # 底線是未被用到的資料,可忽略
x_train = x_train / 255 # 正規化
x_train = x_train.reshape((-1, 28, 28, 1))
return x_train
def build_generator(self):
input_ = Input(shape=(100, ))
x = Dense(7*7*32)(input_)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Reshape((7, 7, 32))(x)
x = Conv2DTranspose(128, kernel_size=2, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Conv2DTranspose(256, kernel_size=2, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
out = Conv2DTranspose(1, kernel_size=1, strides=1, padding='same', activation='tanh')(x)
model = Model(inputs=input_, outputs=out, name='Generator')
model.summary()
return model
def build_discriminator(self):
input_ = Input(shape = (28, 28, 1))
x = Conv2D(256, kernel_size=2, strides=2, padding='same')(input_)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(128, kernel_size=2, strides=2, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(64, kernel_size=2, strides=1, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Flatten()(x)
out = Dense(1, activation='sigmoid')(x)
model = Model(inputs=input_, outputs=out, name='Discriminator')
dis_optimizer = Adam(learning_rate=self.discriminator_lr , beta_1=0.5)
model.compile(loss='binary_crossentropy',
optimizer=dis_optimizer,
metrics=['accuracy'])
model.summary()
return model
def build_adversarialmodel(self):
noise_input = Input(shape=(100, ))
generator_sample = self.generator(noise_input)
self.discriminator.trainable = False
out = self.discriminator(generator_sample)
model = Model(inputs=noise_input, outputs=out)
adv_optimizer = Adam(learning_rate=self.generator_lr, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=adv_optimizer)
model.summary()
return model
def train(self, epochs, batch_size=128, sample_interval=50):
# 準備訓練資料
x_train = self.load_data()
# 準備訓練的標籤,分為真實標籤與假標籤
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# 隨機取一批次的資料用來訓練
idx = np.random.randint(0, x_train.shape[0], batch_size)
imgs = x_train[idx]
# 從常態分佈中採樣一段雜訊
noise = np.random.normal(0, 1, (batch_size, 100))
# 生成一批假圖片
gen_imgs = self.generator.predict(noise)
# 判別器訓練判斷真假圖片
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
#儲存鑑別器損失變化 索引值0為損失 索引值1為準確率
self.dloss.append(d_loss[0])
# 訓練生成器的生成能力
noise = np.random.normal(0, 1, (batch_size, 100))
g_loss = self.adversarial.train_on_batch(noise, valid)
# 儲存生成器損失變化
self.gloss.append(g_loss)
# 將這一步的訓練資訊print出來
print(f"Epoch:{epoch} [D loss: {d_loss[0]}, acc: {100 * d_loss[1]:.2f}] [G loss: {g_loss}]")
# 在指定的訓練次數中,隨機生成圖片,將訓練過程的圖片儲存起來
if epoch % sample_interval == 0:
self.sample(epoch)
self.save_data()
def save_data(self):
np.save(file='./result/DCGAN/generator_loss.npy',arr=np.array(self.gloss))
np.save(file='./result/DCGAN/discriminator_loss.npy', arr=np.array(self.dloss))
save_model(model=self.generator,filepath='./result/DCGAN/Generator.h5')
save_model(model=self.discriminator,filepath='./result/DCGAN/Discriminator.h5')
save_model(model=self.adversarial,filepath='./result/DCGAN/Adversarial.h5')
def sample(self, epoch=None, num_images=25, save=True):
r = int(np.sqrt(num_images))
noise = np.random.normal(0, 1, (num_images, 100))
gen_imgs = self.generator.predict(noise)
# gen_imgs = (gen_imgs+1)/2
fig, axs = plt.subplots(r, r)
count = 0
for i in range(r):
for j in range(r):
axs[i, j].imshow(gen_imgs[count, :, :, 0], cmap='gray')
axs[i, j].axis('off')
count += 1
if save:
fig.savefig(f"./result/DCGAN/imgs/{epoch}epochs.png")
else:
plt.show()
plt.close()
if __name__ == '__main__':
gan = DCGAN(generator_lr=0.0002,discriminator_lr=0.0002)
gan.train(epochs=20000, batch_size=128, sample_interval=200)
gan.sample(save=False)

