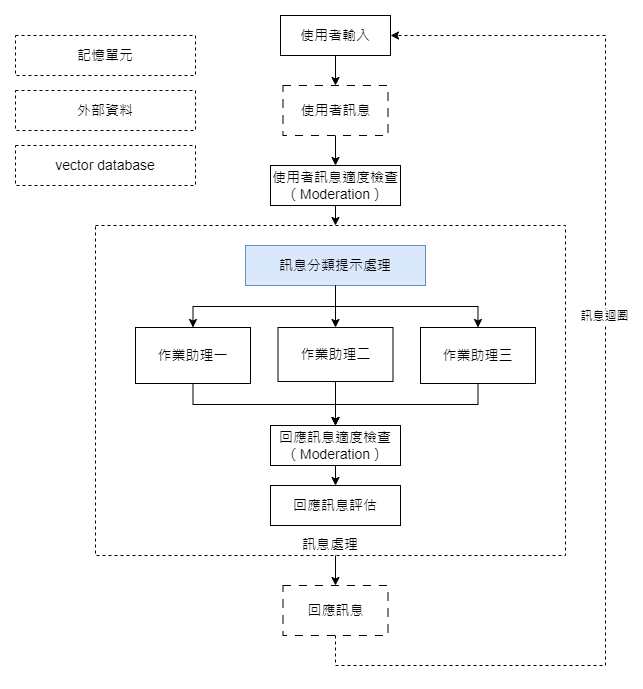
今天,我們將與大家分享一些在設計提示訊息時不可或缺的基本技巧。這些技巧包括「結構化輸出」、「任務分類」,以及如何透過「思維鏈」來優化提示效能。
在傳統應用程式開發中,結構化資料的處理幾乎是不可或缺的,尤其當我們需要資料交換和查詢時。因此,將語言模型的推論結果轉化為結構化輸出成為一個關鍵的整合步驟。
常用的結構化格式有 CSV 和 JSON 等。以下分別是以 CSV 和 JSON 格式進行輸出的範例:
#這裏是使用者的訊息
user_message = f"""
我想學習怎麼點餐。
"""
# 這裏是訊息記錄
messages = [
{ # 任務的指令
'role':'system',
'content': """"你是一個專業的外語老師,下方是學生的學習背景,請按照使用者學習情境隨機推薦 3 個學習詞彙。
學習背景
學生的母語: 中文
想要學習的語言: 英文
輸出時將 3 個詞彙以 csv 的格式輸出,例如: item1,item2,item3
"""
},
{ # 使用者的需求
'role':'user',
'content': f"{user_message}"
}
]
# 呼叫 ChatCompletion
response = get_completion_from_messages(messages)
print(response)
輸出:
menu, order, restaurant
較複雜的 JSON 格式字串處理範例如下:
#這裏是使用者的訊息
user_message = f"""
我想學習怎麼點餐。
"""
# 這裏是訊息記錄
messages = [
{ # 任務的指令
'role':'system',
'content': """"你是一個專業的外語老師,下方是學生的學習背景,請按照使用者選擇的學習情境隨機推薦 1 個學習詞彙並且使用那個學習詞彙做造句。
學習背景
學生的母語: 中文
想要學習的語言: 英文
輸出時將學習詞彙以及學習詞彙的造句以 json 的格式輸出,例如:{
"lex": <學習詞彙>,
"sentence": <學習詞彙的造句>
}
"""
},
{ # 使用者的需求
'role':'user',
'content': f"{user_message}"
}
]
# 呼叫 ChatCompletion
response = get_completion_from_messages(messages)
print(response)
輸出:
{
"lex": "menu",
"sentence": "I would like to see the menu, please."
}
通過這種結構化輸出方式,大型語言模型的運算結果便可以方便地與其他系統或程式碼進行整合。
在開發聊天機器人時,任務分類不僅是一個優化效能的手段,更是一種能夠整合多個專門助理來達成更大、更完整任務的策略。一個完整的聊天機器人通常由負責不同任務的多個模組或助理組成,這樣做的目的是實現更全面和高效率的任務解決方案。
這種分工策略有其顯著優勢:首先,大型語言模型在一次推論中能處理的 token 數量是有限的,透過任務分類和模組整合,我們能確保每一個小任務都在這個限制內得到有效處理。其次,這種整合策略也簡化了整體邏輯,使我們更容易控制和調整模型的反應。
以下是對使用者訊息做任務分類的提示範例:
ef get_learning_method_prompt(user_message):
"""
使用者學習方法的分類器
"""
messages = [
{ # 任務的指令
'role':'system',
'content': """"
你是一個專門用於分類使用者學習方法的chat bot。你的任務是根據使用者的輸入,判斷他們想要哪種學習模式。
如果使用者沒有表達明確的學習模式,請引導他提示他的想法。
我們提供的學習模式有:
詞彙學習:當使用者提到「詞彙」或者顯示出對「單一詞彙」的興趣時,選擇這個模式。例如「我想學習新詞彙」。
例句學習:當使用者提到「例句」或者顯示出對「句子或語句」的興趣時,選擇這個模式。例如「我想看一些句子的例子」。
請輸出: 詞彙學習、例句學習或者無明確資訊
}
"""
},
{ # 使用者的需求
'role':'user',
'content': f"使用者的訊息: {user_message}"
}
]
# 呼叫 ChatCompletion
response = get_completion_from_messages(messages)
return response
測試案例一:
user_message1 = f"""
我想學習多學一些單字。
"""
user_selection1 = get_learning_method_prompt(user_message1)
print(user_selection1)
輸出:
詞彙學習
測試案例二:
user_message2 = f"""
我想從完整的句子中學習如何使用一個語言。
"""
user_selection2 = get_learning_method_prompt(user_message2)
print(user_selection2)
輸出:
例句學習
測試案例三:
user_message3 = f"""
我想學習怎麼點餐。
"""
user_selection3 = get_learning_method_prompt(user_message3)
print(user_selection3)
輸出:
詞彙學習
在第三個測試案例中,我們發現模型的回應有異常。根據我們的定義以及正常邏輯,它應該回應「無明確資訊」。為了解這個問題,我們引入了「思維鏈」的概念。
「思維鏈」可以看作是一系列的邏輯規則或指引,它用於提供語言模型更加明確和有目的性的方向。通過加入更多的判斷條件和具體範例,我們可以更精確地引導模型的反應。
簡而言之,它是一種用以引導模型思考的有效方法。
以下是加入思維鏈後的提示範例:
def get_learning_method_prompt_cot(user_message):
"""
使用者學習方法的分類器
"""
messages = [
{ # 任務的指令
'role':'system',
'content': """"
你是一個專門用於分類使用者學習方法的chat bot。你的任務是根據使用者的輸入,判斷他們想要哪種學習模式。
我們提供的學習模式有:
詞彙學習:當使用者提到「詞彙」或者顯示出對「單一詞彙」的興趣時,選擇這個模式。例如「我想學習新詞彙」。
例句學習:當使用者提到「例句」或者顯示出對「句子或語句」的興趣時,選擇這個模式。例如「我想看一些句子的例子」。
重要規則:
如果使用者的訊息明確提到「詞彙」或「例句」,請選擇對應的模式。
如果使用者的訊息沒有明確提到以上的任何一個學習模式或不是關於學習語言的內容,請回覆【無相關資訊】。
你只能輸入「詞彙學習」、「例句學習」或者「無相關資訊」。不可以回答任何其他的訊息。
}
"""
},
{ # 使用者的需求
'role':'user',
'content': f"使用者的需求: {user_message}"
}
]
# 呼叫 ChatCompletion
response = get_completion_from_messages(messages)
return response
我們再次使用之前有問題的測試案例來驗證加上思維鏈後的結果:
user_message4 = f"""
我想學習怎麼點餐。
"""
user_selection4 = get_learning_method_prompt_cot(user_message4)
print(user_selection4)
輸出:
無相關資訊
我們可以觀察到,語言模型已按照我們的預期正常運作。
以上,就是我們今天要介紹的核心提示技巧。在接下來的實作與文章中,我們會繼續分享更多實用的技巧和方法。敬請期待!
程式碼的部分,請見這裏: https://colab.research.google.com/drive/1JtOICyYi9v2yLyHNjz9ZRs7ry1aip6wO?usp=sharing


 iThome鐵人賽
iThome鐵人賽