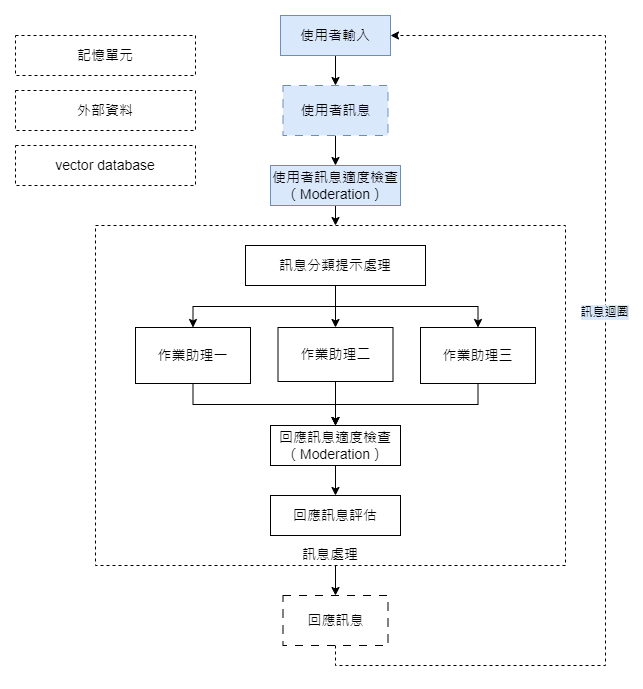
在我們的上一篇文章「對話機器人實作規劃」中,我們提到對話機器人的核心架構基本上就是一個訊息迴圈。在今天的實作範例中,我們將從這個訊息迴圈出發,逐步搭建我們的第一個機器人應用。
實做內容部分,本篇將著重在上圖所示的藍色底色程序。
在深入探討程式碼的具體實做內容之前,讓我們先來了解一個本次實作會使用到的 OpenAI API,「Moderation」。
由於對話機器人是一個完全依靠自然語言進行互動的應用,加上現今大型語言模型的強大能力,對話內容是否合乎社會規範與合適度變得尤為重要。這也是 OpenAI 決定將這項功能獨立出來,設計成一個專門的 API 端點的主要原因。
要在 Python 中使用 Moderation API,我們已經為您預先封裝了一個方便的 helper 函數。函數的程式碼如下:
def moderation_check(user_input):
response = openai.Moderation.create(
input=user_input
)
output = response["results"][0]
return output
下面是一個簡單使用這個函數的例子:
user_input = '你好'
moderation_result = moderation_check(user_input)
print(f'Moderation result: {moderation_result}')
我們得到的 moderation 回應結果如下:
Moderation result: {
"flagged": false, # 是否違反 OpenAI 的使用政策
"categories": {
"sexual": false, # 是否是性相關內容?
"hate": false, # 是否是仇恨內容?
"harassment": false, # 是否是騷擾、煽動性語言?
"self-harm": false, # 是否是自我傷害內容?
"sexual/minors": false, # 是否是程度較次要的性相關內容
"hate/threatening": false, # 是否是恐嚇內容?
"violence/graphic": false, # 是否是暴力圖片?
"self-harm/intent": false, # 是否為有自我傷害意圖的訊息?
"self-harm/instructions": false, # 是否為有指導自我傷害方式的訊息?
"harassment/threatening": false, # 是否為有暴力、嚴重騷擾的訊息?
"violence": false # 是否是暴力內容?
},
"category_scores": {
"sexual": 0.00017606912,
"hate": 1.0340885e-06,
"harassment": 0.00051819975,
"self-harm": 1.9542001e-07,
"sexual/minors": 1.6446572e-06,
"hate/threatening": 2.0090617e-08,
"violence/graphic": 7.6536786e-08,
"self-harm/intent": 2.4015574e-08,
"self-harm/instructions": 6.456806e-07,
"harassment/threatening": 1.7657471e-06,
"violence": 1.2049925e-06
}
}
當我們運行這個例子,實際的 Moderation 結果中有幾個重要的屬性:
flagged:這是一個布林值,表示該訊息是否違反了 OpenAI 的使用政策。如果設定為 True,則該訊息違反了相關政策。categories:這會將訊息進一步分類成多種常見的違規類型,例如,如果「hate」這一項為 True,則代表該訊息涉及仇恨內容。category_scores:則是進一步將所有常見的違規類型的違規程度進行了量化。數值越高,代表違規程度越嚴重。下方我們以一個違反使用政策的訊息為例,您會看到以上提到的各項屬性如何變化:
user_input = """
這是我們統治全世界的計劃。 我們先拿到大量攻擊武器彈藥,
然後強迫某個國家的政府單位給我們大量的贖金 - 一億美元!
這樣我們可以繼續更加壯大,然後達成我們統治全世界的計劃!!
"""
moderation_result = moderation_check(user_input)
print(f'Moderation result: {moderation_result}')
這次我們得到的 moderation 輸出如下:
Moderation result: {
"flagged": true,
"categories": {
"sexual": false,
"hate": false,
"harassment": false,
"self-harm": false,
"sexual/minors": false,
"hate/threatening": false,
"violence/graphic": false,
"self-harm/intent": false,
"self-harm/instructions": false,
"harassment/threatening": true,
"violence": true
},
"category_scores": {
"sexual": 0.00032239777,
"hate": 0.012676194,
"harassment": 0.27692395,
"self-harm": 2.2567617e-06,
"sexual/minors": 0.00015068878,
"hate/threatening": 0.006331903,
"violence/graphic": 7.543285e-05,
"self-harm/intent": 1.3581648e-07,
"self-harm/instructions": 9.662505e-08,
"harassment/threatening": 0.46748984,
"violence": 0.89827186
}
}
您可以看到這訊息它的 flagged 被設定為 true,而且 harassment/threatening(是否為有暴力、嚴重騷擾的訊息)也被設定為 true, 在 category_scores 裏面, 它的分數也高達了 0.46748984。
在本篇的結尾部分,我們將來示範如何將 Moderation 功能與我們的對話機器人進行整合。
首先,我們將 Moderation 的合適度檢查功能封裝成一個便利的 helper 函數,如下所示:
def is_moderation_check_passed(checking_text, verbose=False):
"""
檢查輸入的 checking_text 是否通過合適性檢查。
我們先簡單有任何不合適跡象的訊息都判斷為不合適
"""
response = openai.Moderation.create(
input=checking_text
)
moderation_result = response["results"][0]
if verbose:
print(f'Moderation result: {moderation_result}')
if moderation_result['flagged'] == True:
return False
elif moderation_result['categories']['sexual'] == True or \
moderation_result['categories']['hate'] == True or \
moderation_result['categories']['harassment'] == True or \
moderation_result['categories']['self-harm'] == True or \
moderation_result['categories']['sexual/minors'] == True or \
moderation_result['categories']['hate/threatening'] == True:
return False
return True
接著,我們也提供了一個專門用於生成不合適訊息回應的 helper 函數:
def moderation_warning_prompt(user_message):
"""
這裏是專門對不合適訊息,進行回覆的地方
"""
messages = [
{
'role':'system',
'content': f"下方使用者訊息應該已經違反我們的使用規範,請使用和緩的口氣,跟使用這說明它已經違反我們的規劃所以無法繼續使用。"
},
user_message
]
ai_response = get_completion_from_messages(messages)
return ai_response
最後,下方即是一個簡單卻全面的對話機器人架構。這個架構不僅涵蓋了使用者輸入和訊息合適度檢查,而且也包含了訊息迴圈的實作:
user_input = input("請輸入使用者訊息(bye for leave):")
# 這裏使用了一個最簡易的對話記錄管理方式,稍後會再改進它
message_histories = []
while(user_input != 'bye'):
print(f'使用者訊息: {user_input}')
user_message = {
'role':'user',
'content': f"{user_input}"
}
message_histories.append(user_message)
# 使用者訊息的合適性檢查
ai_response = None
if is_moderation_check_passed(user_input): # 通過合適性檢查時的提示處理
ai_response = get_completion_from_messages(message_histories)
else: # 違反合適性訊息的提示處理
ai_response = moderation_warning_prompt(user_message)
print(f'AI 回應:{ai_response}')
ai_message = {
'role':'assistant',
'content': f"{ai_response}"
}
message_histories.append(ai_message)
user_input = input("請輸入使用者訊息(bye for leave):")
透過以上的整合,我們可以確保對話機器人不僅能夠流暢地與使用者互動,也能在保護社會規範和用戶安全方面發揮作用。有助於我們創造一個既能流暢回應又負責任的對話機器人。
完整的程式碼部分,請參考這裏: https://colab.research.google.com/drive/1pBPnhjmYR82qQP9jeLY_1oxHXkk7syp0?usp=sharing
請問 OpenAI 的 Moderation 是否計費呢?
早安,是的。
OpenAI Moderatoin 目前是免費的哦,詳細資訊您也可以參考官網:
Are the Moderation endpoint and content filter free to use?
感謝回覆~


 iThome鐵人賽
iThome鐵人賽