開發資料應用,相對於一般的應用軟體開發,特有的挑戰有:
其中,1, 2 算是企業的經營管理問題、3~6 才是純萃的資料工程 (data engineering) 問題。
前面提到,我是去 L 社業務部處理 BI 問題。考慮工作時,我心裡也冒了一個問號?「咦, L 社人才濟濟,工程部門的軟體工程師更是上百人,怎麼會想到要找我?」不過,由於我內心深處對於自己業界知名度,總是有著嚴重的錯誤認知,「想必是因為,桃李不言,下自成蹊吧!」這句話配合著滿滿的自我感覺良好在我腦中響起,於是,我就沒有在多想,接下了這分工作。
後來,我才得知,這個工作大概是如何產生的:在 L 社的慣例,企業內部系統,要交給海外團隊開發。由於 2019 年,L 社成長的力道相當強勁,L 社的海外團隊表示,『要開發這套軟體的話要排隊,而且同時還有太多的企業內部系統要開發,全部都在排隊。還有,你們的規格,一直都開得不夠清楚。』
而我的主管則表示,「該哭的人,都哭過一遍了,該跪的人,也都跪過一遍了。」總之,後來,要求該軟體務必要能準時交付的高層,給了我主管一個雇用人的名額 (head count),所以我的那分工作就這樣子產生了。
這邊有一些經營管理問題:
日後,當我開始接案,協助數家企業處理 BI 系統的問題時,也發現很多企業也或多或少都有類似的症狀。一個讓公司管理層面難以滿意的 BI 系統,常常是用 Excel 堆疊而成、又或是讓 backend engineer 使用 OLTP 常用的技術來硬寫。
讀者可能會問,「管理階層的認知、整合知識的困難這些問題,最後就是導致,重要且困難的工作,全部被交給第一線的員工來設法解決,這樣算是好的解決方案嗎?」
任何的管理階層有其知識的極限,所以當一間企業有可能會因為知識不足導致經營管理上的阻礙時,該企業應該考慮雇用外部顧問之類的方式,來協助管理階層在關鍵的時刻,可以找得到人來問。如此,才容易去正確地認知困難問題的本質、做正確的決策。
另外,管理學普遍認為,職缺的設計是經營成效的重要關鍵。有設計良好的職缺,人的能力只要可以填滿職缺的需求,組織就可以產生效能,也因此可以做到『讓平凡的人做出不平凡的事』。
以 BI 相關問題來講,有一個職缺叫分析工程師 (Analytic Engineer),他負責的工作恰好是寫 OLAP 的 SQL query,這就可以很巧妙地補足從資料分析師到資料工程師之間的知識落差。可惜,在寫本文的同時,該職缺在台灣還非常不流行。
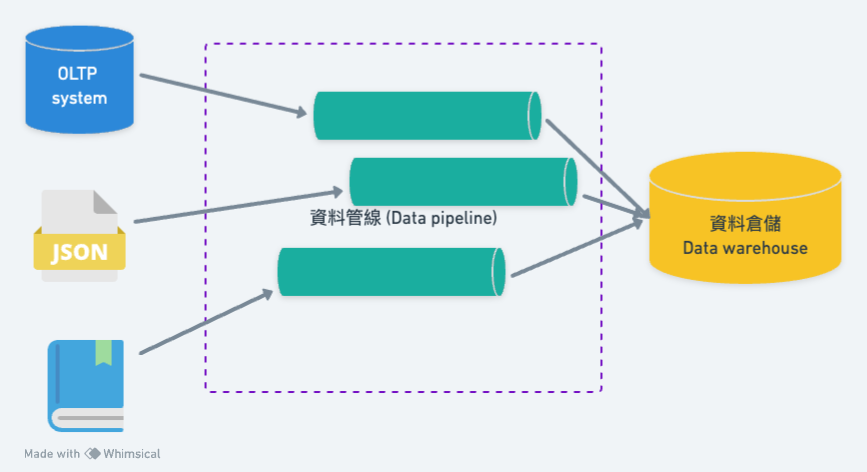
在 BI 系統,資料來源通常可以分成三種不同的來源 (見上圖):
這三種來源,就各有各的難題。比方說,來自自家系統的資料,那自家公司的 OLTP 系統是否有提供 API 呢?很多時候也不一定會有,如果是在業務部的話,可能只有提供 Excel/CSV 匯出的功能。
來自第三方的資料,運氣好的話,可以從 API 取得。沒有 API 又想要做自動化時,可能得考慮寫網頁爬蟲去撈取。
讓員工手動輸入的資料,最基本的,可能就是讓員工用類似 Google 表單的方式填資料,然而,一旦當資料有相依性時,要讓人可以正確地一次就把資料填對,填資料的界面就需要從資料庫去撈取選項,讓使用者可以用選單的方式來填入。真的要做得好的話,往往又需要發展成另一個 OLTP 系統。
一間企業隨著業務的成長,很有可能會有愈來愈多的異質資料來源,資料來源愈多,要有效地整合,就愈來愈困難,到後來很可能會變成有無數難以維護的 ETL 程式:
有很多時候,我們去取得一個 API 的輸出,比方說,長成下方的樣子
{"name": "Jack"
"gender": "Male"
"age": 27}
然後,有一天,不知為何,API 就會給出如下的輸出
{"name": "John"
"age": 15}
該怎麼辦呢?
從資料源來的資料,多久要跟資料倉儲 (data warehouse) 同步一次呢?
考慮到資料在原始資料系統中如何儲存時,就得來思考資料儲存的特性。一般而言,原始資料會有兩種儲存方式:
可變方式記錄的,是某些資料實體 (data entity) 最新的狀態。而不可變方式記錄的,則是發生的事件 (event)。
如果以常見的銷售管理系統來舉例子的話,客戶資料 (customer),往往是用『可變』的方式來記錄,比方說,客戶的電話修改了,就直接修改到客戶資料表裡,客戶資料表隨時有最新的客戶資料。而訂單 (order) 因為記錄的是一個又一個獨立的事件,則是用『不可變』的方式來記錄,每一筆新的訂單就是一筆新的記錄,甚至,就算有修改原始的訂單,也要再產生一筆新的記錄。
這類「儲存特性」必須在移動資料時,即從原始資料源同步到資料倉儲時,做充分的考慮與因應設計,否則也會導致錯誤的結果。


 iThome鐵人賽
iThome鐵人賽