啊,忽然不知不覺就是第二天挑戰了,但是腦子還是一片混亂, 所以我們還是就來簡單説説作為一個資料工程師,在胡搞瞎搞馬上要入手時,第一個該開始的地方Create(至少我是從這裡開始的)
開始囉!
身為一個Data Engineer, 在日常的工作中, 主要的工作內容就是針對現有的資料進行清理(Data Cleaning), 協助分析師抑或是資料科學家進行後續的資料加值,
那在做資料清理的時候,最重要也是第一步會是什麼呢?
當然就是,你要先取的資料,並且讀入你的工具中
這邊簡單介紹一下主要有5種方法可以來Create 你的DataFrame,幫助你做後續的清理工作!
RDD = Resilient Distributed Datasets (彈性分散式資料集), 顧名思義它可以分散成多個分區,每一個分區就是你的dataset 的片段, 也就是這樣的架構,可以達到分散式運算的效果。
所以我們將資料藉由RDD載入DataFrame中, 在後續的運算上就可以利用分散式架構達到快速運算的目的rdd.toDF = 將data / column Header(ColumnName)進行mappingdf.show() = show出你的DataFrame的長相,通常會像是表格(其中也有一些有趣的parameter可以玩,這個後續再介紹)df.printSchema() = 將你的DataType 顯示出來
情境:
對我來說, 因為這樣的資料需要手動輸入, 所以通常都是拿來做範例的時候使用(就是像現在啦)
下面範例:
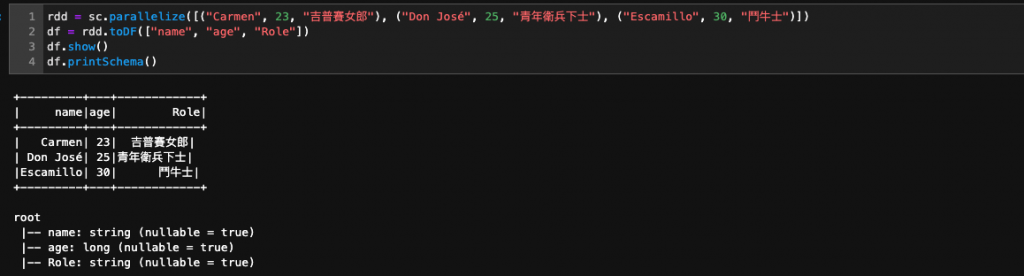
rdd = sc.parallelize([("Carmen", 23, "吉普賽女郎"), ("Don José", 25, "青年衛兵下士"), ("Escamillo", 30, "鬥牛士")])
df = rdd.toDF(["name", "age", "Role"])
df.show()
df.printSchema()
'''
+---------+---+------------+OUTPUT+---------+---+------------+
+---------+---+------------+
| name|age| Role|
+---------+---+------------+
| Carmen| 23| 吉普賽女郎|
| Don José| 25|青年衛兵下士|
|Escamillo| 30| 鬥牛士|
+---------+---+------------+
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- Role: string (nullable = true)
+---------+---+------------+OUTPUT+---------+---+------------+
'''
在使用這個方法的時候要注意, 需要import pandas as pd的library 去create DataFrame 然後再轉成Spark的DataFrame!
這時候可能會有人好奇想問,既然可以直接利用pandas 這麼主流的library去做資料處理及分析, 那為什麼還需要Spark呢?
當然在處理資料量較少的狀況可以用Pandas去做Data Cleaning, 但是當你遇到TB等級的資料時, pandas 因為缺乏分散式運算的能力, 相對的也就無法快速地處理現有的資料。
情境:
所以當你想要把pandas 的DataFrame轉換成更有效率的Spark DataFrame做Data Cleaning時
下面範例:
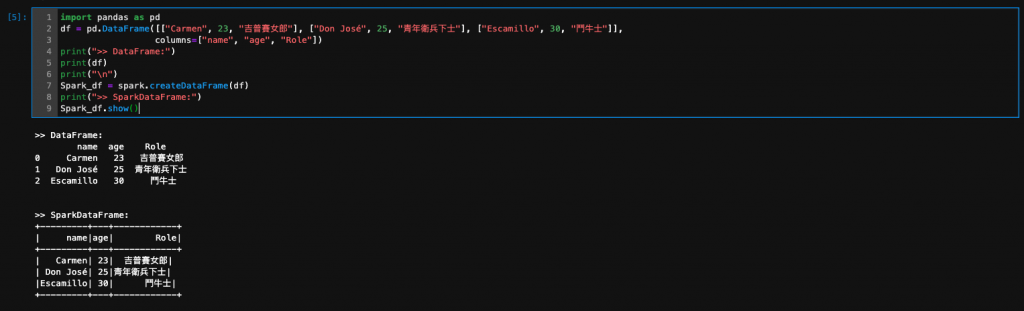
import pandas as pd
df = pd.DataFrame([["Carmen", 23, "吉普賽女郎"], ["Don José", 25, "青年衛兵下士"], ["Escamillo", 30, "鬥牛士"]],
columns=["name", "age", "Role"])
print(">> DataFrame:")
print(df)
print("\n")
Spark_df = spark.createDataFrame(df)
print(">> SparkDataFrame:")
Spark_df.show()
'''
+---------+---+------------+OUTPUT+---------+---+------------+
>> DataFrame:
name age Role
0 Carmen 23 吉普賽女郎
1 Don José 25 青年衛兵下士
2 Escamillo 30 鬥牛士
>> SparkDataFrame:
+---------+---+------------+
| name|age| Role|
+---------+---+------------+
| Carmen| 23| 吉普賽女郎|
| Don José| 25|青年衛兵下士|
|Escamillo| 30| 鬥牛士|
+---------+---+------------+
+---------+---+------------+OUTPUT+---------+---+------------+
'''
恩 對 就是這樣
情境:
對我來說, 因為這樣的資料需要手動輸入, 所以通常都是拿來做範例的時候使用(就是像現在啦)
下面範例:
list_values = [["Carmen", 23, "吉普賽女郎"], ["Don José", 25, "青年衛兵下士"], ["Escamillo", 30, "鬥牛士"]]
Spark_df = spark.createDataFrame(list_values, ["name", "age", "Role"])
Spark_df.show()
'''
+---------+---+------------+OUTPUT+---------+---+------------+
+---------+---+------------+
| name|age| Role|
+---------+---+------------+
| Carmen| 23| 吉普賽女郎|
| Don José| 25|青年衛兵下士|
|Escamillo| 30| 鬥牛士|
+---------+---+------------+
+---------+---+------------+OUTPUT+---------+---+------------+
'''
終於來到重頭戲之一, 也就是直接讀CSV/Json 啦
在讀取CSV資料的時候要非常小心他的delimiter,正確的設定delimiter 就可以讀到被切的很乾淨的資料, 才不會發生跑版(?)的問題
同場加映:read.option
CSV: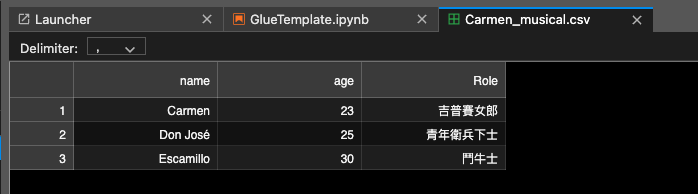
情境:
大部分的情境中,讀取CSV來做初步的Data Cleaning 可能是最常見的一種CASE, 總而言之很好用
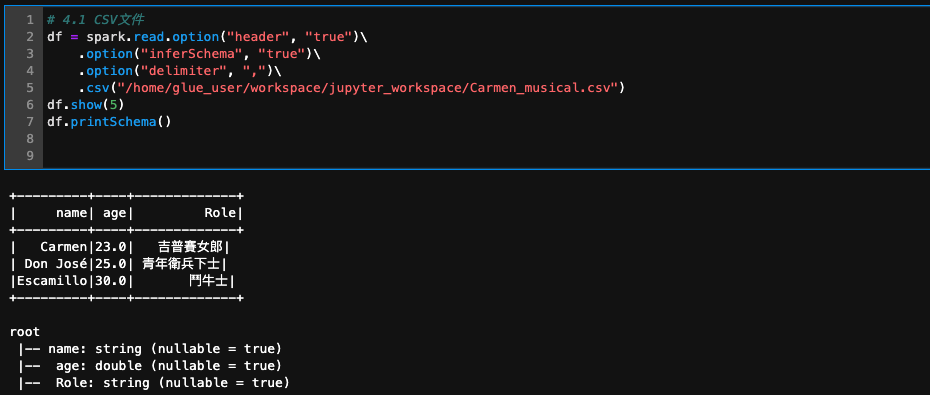
df = spark.read.option("header", "true")\
.option("inferSchema", "true")\
.option("delimiter", ",")\
.csv("/home/glue_user/workspace/jupyter_workspace/Carmen_musical.csv")
df.show(5)
df.printSchema()
'''
+---------+---+------------+OUTPUT+---------+---+------------+
+---------+----+-------------+
| name| age| Role|
+---------+----+-------------+
| Carmen|23.0| 吉普賽女郎|
| Don José|25.0| 青年衛兵下士|
|Escamillo|30.0| 鬥牛士|
+---------+----+-------------+
root
|-- name: string (nullable = true)
|-- age: double (nullable = true)
|-- Role: string (nullable = true)
+---------+---+------------+OUTPUT+---------+---+------------+
'''
需要特別注意的是,使用超過2.3以上的spark版本才可以使用以下語法!
json:
[
{
"name": "Carmen",
"age": 23,
"Role": "吉普賽女郎"
},
{
"name": "Don José",
"age": 25,
"Role": "青年衛兵下士"
},
{
"name": "Escamillo",
"age": 30,
"Role": "鬥牛士"
}
]
情境:
讀取json來做初步的Data Cleaning 也是另一個很方便的case,也很好用
df = spark.read.option("multiline","true").json("/home/glue_user/workspace/jupyter_workspace/Carmen_musical.json")
df.show(5)
df.printSchema()
'''
+---------+---+------------+OUTPUT+---------+---+------------+
+------------+---+---------+
| Role|age| name|
+------------+---+---------+
| 吉普賽女郎| 23| Carmen|
|青年衛兵下士| 25| Don José|
| 鬥牛士| 30|Escamillo|
+------------+---+---------+
root
|-- Role: string (nullable = true)
|-- age: long (nullable = true)
|-- name: string (nullable = true)
+---------+---+------------+OUTPUT+---------+---+------------+
'''
各個DB幾乎都可以連,只要你提供正確的連線資訊就可以囉!
情境:
清理大量資料,去資料出來做分析或是建資料管道(Data Pipeline)的時候很好用喔~
## 使用mysql jdbc作為連線讀取DB中的data
url = "jdbc:mysql://localhost:3306/test"
df = spark.read.format("jdbc") \
.option("url", url) \
.option("dbtable", "runoob_tbl") \
.option("user", "root") \
.option("password", "8888") \
.load()\
df.show()
df.printSchema()
'''
+---------+---+------------+OUTPUT+---------+---+------------+
+------------+---+---------+
| Role|age| name|
+------------+---+---------+
| 吉普賽女郎| 23| Carmen|
|青年衛兵下士| 25| Don José|
| 鬥牛士| 30|Escamillo|
+------------+---+---------+
root
|-- Role: string (nullable = true)
|-- age: long (nullable = true)
|-- name: string (nullable = true)
+---------+---+------------+OUTPUT+---------+---+------------+
'''
如果有任何不理解、錯誤或其他方法想分享的話,歡迎留言給我!喜歡的話,也歡迎按讚訂閱!
我是 Vivi,一位在雲端掙扎的資料工程師!我們下一篇文章見!Bye Bye~
【本篇文章將同步更新於個人的 Medium,期待與您的相遇!】


 iThome鐵人賽
iThome鐵人賽