今天介紹在影像中常見的資料前處理和資料增生(Data augmentation)
資料前處理:如果資料是自己收集的,多少會有一些缺失值、重複數據、異常值等。
資料增生:通過不同方式和技術來增加現有數據集的大小,以改善機器學習模型的性能和泛化能力。
首先我們先引入函式庫和設定路徑
from torchvision import transforms
from matplotlib import pyplot as plt
from torchvision import datasets
train_path = './cat-vs-rabbit/train-cat-rabbit'
test_path = './cat-vs-rabbit/test-images'
val_path = './cat-vs-rabbit/val-cat-rabbit'
單純做正規化,所以跟原圖看起來差不多:
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.ToTensor(),
normalize
])
train_dataset = datasets.ImageFolder(train_path, transform = transform)
row_img, label = train_dataset[802]
plt.imshow(row_img.permute(1, 2, 0))
plt.show()
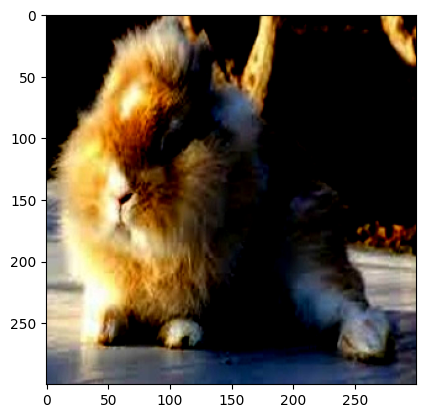
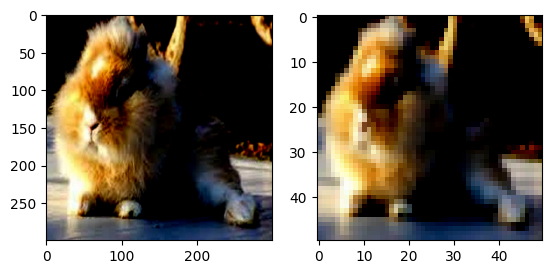
Resize() :將圖片調整為給定的大小:
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.Resize(50),
transforms.ToTensor(),
normalize
])
train_dataset = datasets.ImageFolder(train_path, transform = transform)
resize_img, label = train_dataset[802]
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(row_img.permute(1, 2, 0))
plt.subplot(1, 2, 2)
plt.imshow(resize_img.permute(1, 2, 0))
plt.show()
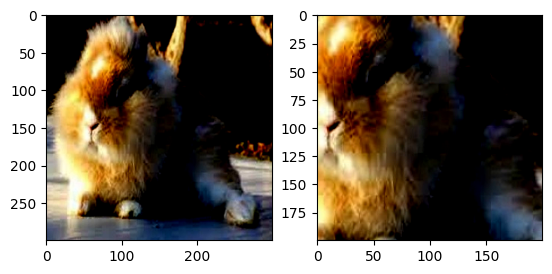
CenterCrop():以輸入圖的中心點為中心做指定size的裁剪操作。
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.CenterCrop(200),
transforms.ToTensor(),
normalize
])
train_dataset = datasets.ImageFolder(train_path, transform = transform)
center_crop_img, label = train_dataset[802]
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(row_img.permute(1, 2, 0))
plt.subplot(1, 2, 2)
plt.imshow(center_crop_img.permute(1, 2, 0))
plt.show()
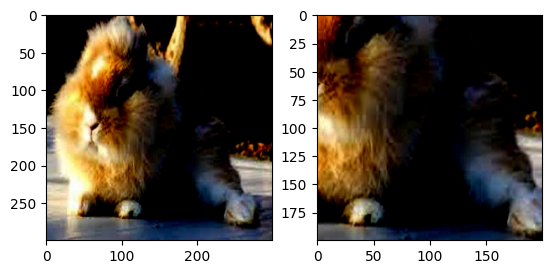
RandomCrop():以輸入圖的隨機位置為中心做指定size的裁剪操作。
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.RandomCrop(200),
transforms.ToTensor(),
normalize
])
train_dataset = datasets.ImageFolder(train_path, transform = transform)
random_crop_img, label = train_dataset[802]
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(row_img.permute(1, 2, 0))
plt.subplot(1, 2, 2)
plt.imshow(random_crop_img.permute(1, 2, 0))
plt.show()
RandomHorizontalFlip():以0.5機率水平翻轉給定的圖像。
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
train_dataset = datasets.ImageFolder(train_path, transform = transform)
random_horizontal_flip_img, label = train_dataset[802]
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(row_img.permute(1, 2, 0))
plt.subplot(1, 2, 2)
plt.imshow(random_horizontal_flip_img.permute(1, 2, 0))
plt.show()
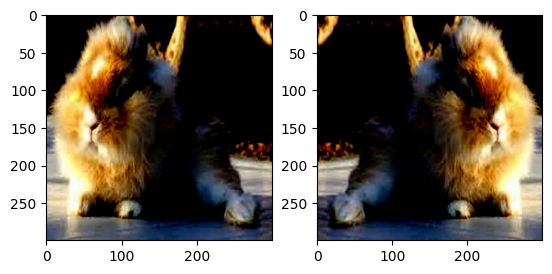
RandomVerticalFlip():以0.5機率垂直翻轉給定的圖像。
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
normalize
])
train_dataset = datasets.ImageFolder(train_path, transform = transform)
random_vertical_flip_img, label = train_dataset[802]
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(row_img.permute(1, 2, 0))
plt.subplot(1, 2, 2)
plt.imshow(random_vertical_flip_img.permute(1, 2, 0))
plt.show()
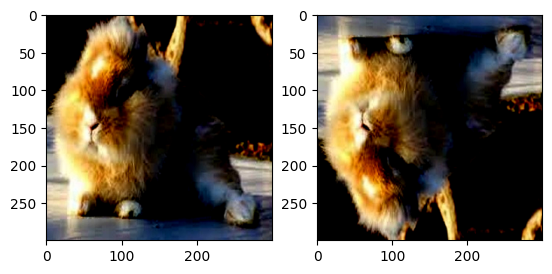
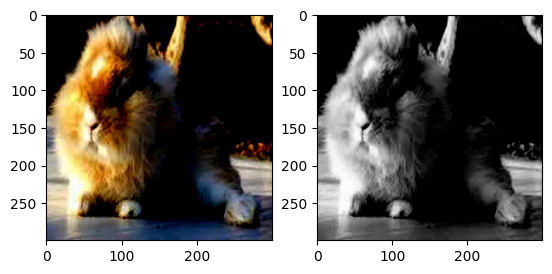
Grayscale():將給定圖像轉換為灰度圖像。
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.Grayscale(num_output_channels=3),
transforms.ToTensor(),
normalize
])
train_dataset = datasets.ImageFolder(train_path, transform = transform)
grayscale_img, label = train_dataset[802]
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(row_img.permute(1, 2, 0))
plt.subplot(1, 2, 2)
plt.imshow(grayscale_img.permute(1, 2, 0))
plt.show()
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.RandomCrop(200),
transforms.RandomHorizontalFlip(),
transforms.Grayscale(num_output_channels=3),
transforms.ToTensor(),
normalize
])
train_dataset = datasets.ImageFolder(train_path, transform = transform)
after_img, label = train_dataset[802]
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(row_img.permute(1, 2, 0))
plt.subplot(1, 2, 2)
plt.imshow(after_img.permute(1, 2, 0))
plt.show()
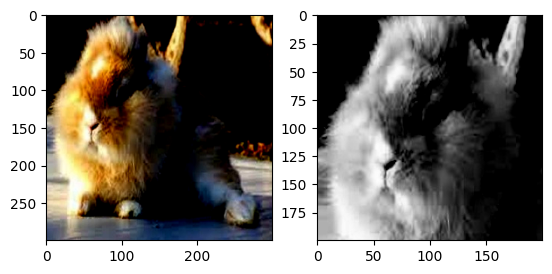
今天介紹透過資料前處理的一些基本方法,透過放大縮小、裁減、顏色改變等等,如果攝影機亮度出現改變,或是接近或較遠的拍照,機器還是可以認出是同一個類別。

