今天介紹如何創建一個 DataLoader,它的用途是在每次模型學習時將要學習的資料搬到模型裡,首先我們先指定存在硬碟中的資料夾路徑:
train_path = './cat-vs-rabbit/train-cat-rabbit'
test_path = './cat-vs-rabbit/test-images'
val_path = './cat-vs-rabbit/val-cat-rabbit'
將資料送進去模型之前,必須先將資料轉成模型懂得格式,且也會做正規化讓機器學習更有效率,通常也會做資料增生,本篇先介紹最簡單的水平翻轉,明天會再補一篇關於資料前處理的文章。
# 正規化是機器學習常用的資料前處理,將資料範圍變成[0,1]之間
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.RandomCrop(224), # 隨機裁減
transforms.RandomHorizontalFlip(), # 圖像水平翻轉
transforms.ToTensor(), # 轉成 tensor 格式
normalize
])
定義好資料前處理的方法後,用昨日講到的 ImageFolder 建立資料集:
# 建立資料集
train_dataset = datasets.ImageFolder(train_path, transform = transform)
val_dataset = datasets.ImageFolder(val_path, transform = transform)
test_dataset = datasets.ImageFolder(test_path, transform = transform)
接著使用 torch.utils.data 中的 DataLoader 建立此任務的資料搬運工,以下會介紹幾個比較常用到傳入 DataLoader 的引數:
dataset(Dataset):要取得資料的地方(就是我們上面建立的資料集)。
batch_size(int):每個批次要載入多少樣本,預設值是 1。
shuffle(bool):每個 epoch 是否打亂資料集的順序,預設值是False。
num_workers(int):要用多少個 subprocesses 來讀取資料,數字越大讀取越快,預設值是0。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataloader = DataLoader(val_dataset, batch_size=64, shuffle=True)
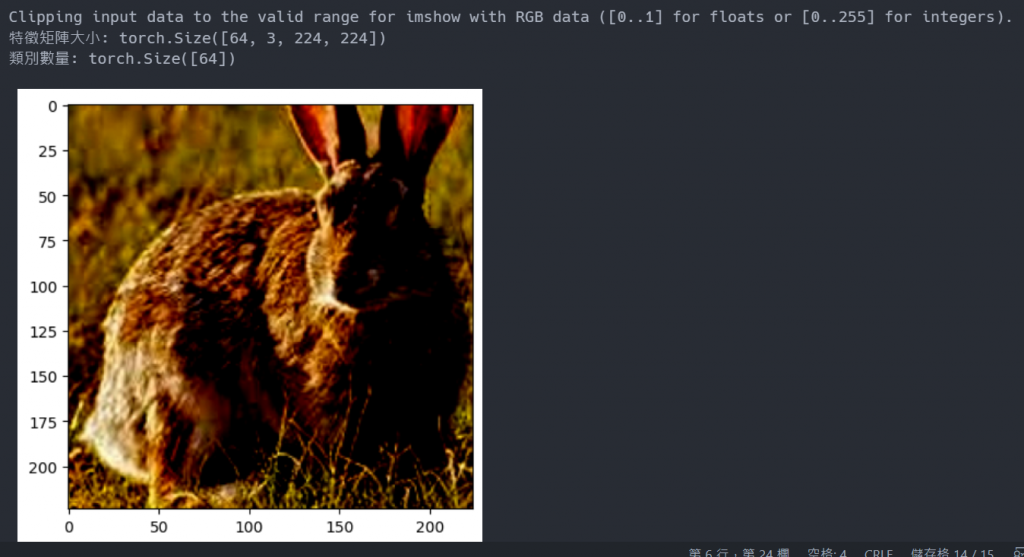
此段程式碼每次跑都會讀取 64 張圖片和 64 個對應標籤,我們顯示第 0 個結果。
# 顯示圖片和對應的標籤
train_features, train_labels = next(iter(train_dataloader))
print(f"特徵矩陣大小: {train_features.size()}")
print(f"類別數量: {train_labels.size()}")
img = train_features[0]
label = train_labels[0]
plt.imshow(img.permute(1, 2, 0))
plt.show()
print(f"Label: {label}")
今天介紹了怎麼使用 DataLoader,其中有使用一些資料前處理的方法,明天會整理一篇關於資料前處理常用的方式。

