資料正規化 ( Normalization ) 與標準化 ( Standardization ) 在機器學習中是為重要的資料預處理技術,將特徵值縮放到一個特定的標準範圍內之過程,以確保特徵資料之間的尺度一致性。這可以幫助改善機器學習模型的性能和收斂速度,對於類別變數 ( Categorical Variable ),能夠轉換成模型可接受的資料格式,對模型的訓練是不可缺少的一環。
不同特徵可能有不同的尺度和範圍,例如一個特徵的數值範圍介於 [ 0 , 1000 ],而另一個介於 [ 0 , 1 ]之間,這樣個尺度差異可能對某些機器學習算法產生負面影響,具有較大尺度的特徵可能會在模型的訓練過程中佔主導地位 ( 影響力較大 ),導致其他特徵的影響被忽略。
如果你今天要做房價的預測模型,而你給他的特徵資料有房屋的面積跟臥室的數量,面積的特徵值通常在數千到數萬平方英尺之間 ,而臥室數量特徵值通常在 [ 1 , 5 ] 之間,兩者特徵的尺度範圍就相差甚遠,如果在這時候不做資料標準化,直接使用原始的特徵值來訓練模型,面積特徵在模型訓練時影響較大,臥室數量特徵的影響較小,這種情況下模型可能會誤認為房價主要由面積特徵值決定 ( 因為尺度較大 ),而忽略了臥室數量的重要性,因此透過標準化,將面積和臥室數量的值按比例調整到相似的範圍,像是調整到 [ 0 , 1 ] 之間,特徵尺度大小的相差就不會那麼大,各個特徵的影響力就不會懸殊甚大,模型也就會平等重視所有特徵進而做出更準確的預測,資料預先經過標準化,也能夠在模型訓練時避免梯度爆炸或消失的問題。
Z-Score ( Z-Score Normalization ) 是一種常見的資料標準化方法,對每個特徵個別進行標準化,針對每個特徵 ,計算其訓練資料的平均值
和標準差
,在用平均值和標準差將所有樣本的特徵值轉換至接近 0,數值較小的範圍內,如 [ -0.5 , 0.5 ]、[ -1 , 1 ]。這樣就可以確保每個特徵值都在一個相差不大的範圍內,確保特徵尺度一致性,Z-Score 公式為:
以一張圖片為例,圖片會用 1 個位元組來表示一格像素的顏色值,因此顏色值區間為 [ 0 , 255 ],面對這情況做標準化時可不用 Z-Score 去專門計算標準差和平均值,可直接對每個特徵值 ( 每個像素的顏色值 ) 除以 255,如此一來就把每個特徵值轉換至 [ 0 , 1 ] 區間內。
值得注意的是,對於訓練集和測試集,兩者使用的標準化參數 ( 標準差、平均值 ) 要相同,不可單獨進行標準化,模型是用經標準化的訓練集訓練出來的,因此訓練集用哪些參數標準化換在測試集就要用哪些參數標準化,否則會導致:
下面是用 Python 的 StandardScaler 實現標準化範例:
from sklearn.preprocessing import StandardScaler
# 四筆特徵資料 X,每列為一筆資料
X = [[1.0, 2.0],
[2.0, 3.0],
[3.0, 4.0],
[4.0, 5.0]]
# 建立 StandardScaler 物件
scaler = StandardScaler()
# 使用訓練資料計算平均值和標準差,並進行標準化
X_scaled = scaler.fit_transform(X)
print("原始特徵:\n", X)
print("標準化後的特徵:\n", X_scaled)
在機器學習中,類別變數是指有很多個可能值的變數,這些值通常表示不同的類別或分類,可能為數字、文字等,因為模型都會需要資料為數值的型別 ( numerical ) 作為輸入,如下圖的 Feedback 欄位,資料型別為文字時,就必須作類別變數處理,要把文字的資料轉成數值型別,處理方式以標籤編碼和獨熱編碼最常見:
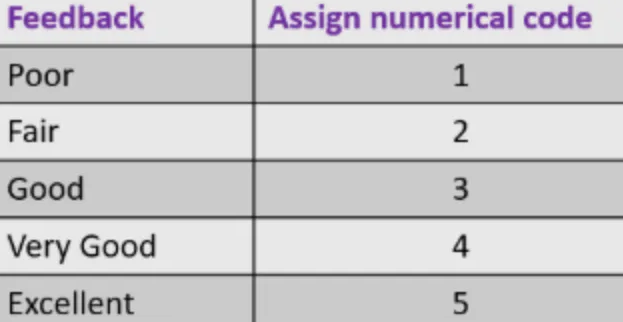
Label Encoding 將類別值對應到數值,這個方法適用於存在高低順序關係的類別變數,類別間都有著順序關係,對於上圖 Feedback 欄位的類別變數,要讓模型知道類別間存在順序關係,就可以用 Label Encoding 來幫我們把該欄位的每個資料都轉成對應 Assign numerical code 欄位的的數值形式。
對於沒有高低順序關係的類別變數要轉換為數值,就可用 One-Hot Encoding,將每個類別值轉換為一個獨立的二進制特徵,若要轉換四種動物的名稱 ( 下圖 ):
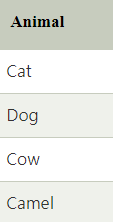
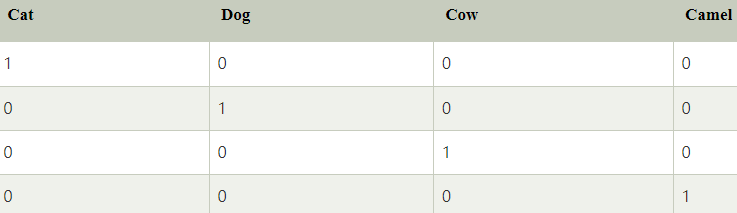
經過 One-Hot Encoding 就會轉換成四個特徵, “Cat “ 就變成 1000,動物 “Dog” 變成 0100 ( 下圖 )。
下面為 Python 實現對於 ”hello python” 這個字串資料的獨熱編碼:
str_data = 'hello python' # 特徵資料
print(str_data)
#特徵資料可能會出現的所有字母(包括空格)
eng_alphabet = 'abcdefghijklmnopqrstuvwxyz '
# 將所有字母(包括空格)都各自對映到一個數字0~26(為1的位置)
char_to_int = dict((c, i) for i, c in enumerate(eng_alphabet))
# 將數字0~26(為1的位置)都各自對映到一個字母(包括空格)
int_to_char = dict((i, c) for i, c in enumerate(eng_alphabet))
# 紀錄特徵資料轉換後為1的位置
int_encoded = [char_to_int[char] for char in str_data]
print(int_encoded)
# 進行獨熱編碼
onehot_encoded = list()
for value in int_encoded:
letter = [0 for _ in range(len(eng_alphabet))]
letter[value] = 1
onehot_encoded.append(letter)
print(np.array(onehot_encoded)) # 編碼後結果
inverted = int_to_char[argmax(onehot_encoded[0])] # 反轉編碼
print(inverted)
此外,在處理類別變數時需要考慮避免虛擬變數陷阱,這是因為在 One-Hot Encoding 中,如果將所有轉換後的特徵 ( 上圖右特徵欄位 ) 都包括在模型中,可能會造成多重共線性,多重共線性即指某些獨立的變數可以被其他獨立變數線性預測出來,像是上圖右的欄位,只要知道前三個欄位分別為 1、0、0,就可以確定最後一個欄位一定為 0 ( 可預測 ), 既然都可以被預測出來,Camel 欄位就成了無意義欄位 ( 虛擬變數陷阱 ),這就說明了多重共線性的係數解釋性低的問題:
為了解決有無意義欄位的問題,解決方法就是刪除其中一個獨熱特徵,把 Camel 欄位刪除即可解決,但不一定要是 Camel 欄位也可以是其他欄位,但只需刪除一個即可,至於不管是 Label Encoding 來是 One-Hot Encoding,選擇哪種資料的處理方式取決於類別變數的性質、資料集的大小以及模型需求,每種不同的方法都會影響著模型的效能表現。
今天學到了:
今天學習到了如何去實現資料的預處理步驟,明天我們就要來介紹機器學習中重要的兩個問題,分別代表著模型進行的不同任務,就是回歸問題 ( Regression Problem ) 與分類問題 ( Classification Problem ),我們下一篇文章見 ~
https://www.javatpoint.com/how-to-one-hot-encode-sequence-data-in-python


 iThome鐵人賽
iThome鐵人賽