資料預處理 ( Data Preprocessing ) 指的是在進行機器學習或深度學習之前,對原始的資料進行處理或轉換的過程,是相當重要的流程,為了確保訓練模型時使用的資料品質、一致性與合適程度以提高模型性能與泛化能力,常見的預處理技術有:
資料清理是資料預處理過程的重要步驟,包括處理資料中的缺失值,異常值和重複值等,確保數據的準確性、完整性和一致性,下面是資料清理的常見方法:
資料清洗是確保數據的基礎,它可以消除數據中的噪音,提高對資料的分析和模型的準確性與可靠性,適當的對資料做預處理可以提升模型的性能,模型的結果表現很大程度上也取決於輸入數據的質量。
資料平滑處理目的是在資料中移除或者是減少雜訊干擾 ( Noise ) 的過程,這樣就可以更好地觀察數據的流動趨勢,這個方法在處理有雜訊的數據時非常有用,可以幫助我們提取真實的數據特徵,假設你有一個每日銷售額的數據資料,但因某些外部因素 ( 人為失誤、機器故障 ),有某幾日的銷售額出現了極端的高值或低值,這些值可能不符合真實情況,這些極端值可能會影響你對銷售額趨勢的分析,此時就可用資料平滑處理方法來減少極端值帶來的影響,可利用移動平均的算法。
移動平均 Moving Average:移動平均是通過計算一個固定窗口大小內數據的平均值來平滑數據。例如:3 日的移動平均就是將每三天的數據值取平均,然後用該平均值替換原始數據。
依據移動平均的算法,
假設原始數據如下:
Day 1: 10
Day 2: 15
Day 3: 25
Day 4: 5
Day 5: 30
計算 3 日移動平均:
Day 1: (10) / 1 = 10
Day 2: (10 + 15) / 2 = 12.5
Day 3: (10 + 15 + 25) / 3 = 16.67
Day 4: (15 + 25 + 5) / 3 = 15
Day 5: (25 + 5 + 30) / 3 = 20
得到經過平滑處理後的數據,會發現到數據相較於原始的變得更加平穩平滑,替換了原先的極端值,使得數據序列的波動變得比較平滑,有助於更好地觀察數據的趨勢,不會被極端值所影響。這邊要注意的是,經平滑處理後的數據能減少原有的噪音,但同時也可能導致對於原始數據的某些細節丟失。
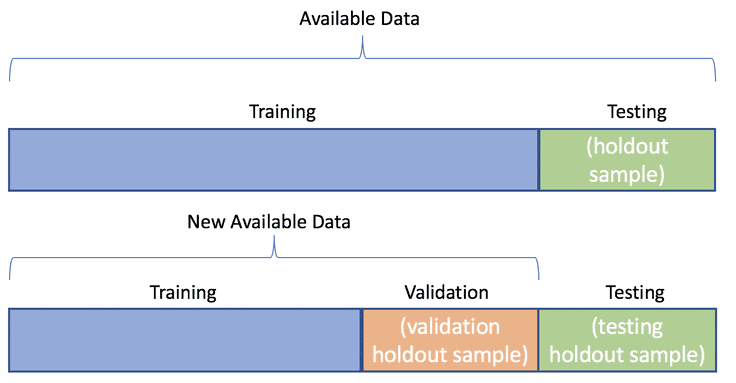
資料切割是指將原始的資料集切割為多個子集的過程,好讓模型有這些資料能夠訓練 ( Training )、驗證 ( Validation ) 和測試 ( Testing ),最常見的切割方式會把資料集依照給定比率切分為訓練集(Training Set)和測試集(Testing Set)。
驗證集(Validation Set),讓模型在經測試集測試前能夠依據在驗證集上的表現調整參數和超參數,進而減少模型過度擬和 ( Overfitting ) 的情況發生。今天學到:
資料的預處理是機器學習中不可或缺的一個步驟,明天我們將介紹其它的資料處理手段,像是對資料進行正規化 ( Normalization ) 與標準化 ( Standardization ),那我們就下篇文章見 ~
https://algotrading101.com/learn/train-test-split/


 iThome鐵人賽
iThome鐵人賽