P0 事件並不常發生,但只要一發生就非常刺激,說起鬼故事來一個比一個還要精彩。因此,這類型的故事講起來常常都能津津樂道一番。不過,如同戰爭中真正交火的時間只佔據一小部分一樣,其實 SRE 最主要的工作還是確保系統的穩定度,以及日常維運的各種事務。
因此,筆者在編排系列文章時,還是花了大量的篇幅先講述了最重要的日常維運,一直到後半段才進入 P0 事件的系列。這個系列的篇幅可能也不會太長,主要還是希望能先帶給讀者一個觀念,處理 P0 事件並非 SRE 的主要工作(也沒人希望是),而且大部分發生狀況的當下, SRE 不一定能真正起到什麼作用。
不知道是不是因為八字比較輕的關係,筆者在值班的時候發生 P0 事件的比例似乎特別高,甚至被主管詢問過是否要去廟裡求神問卜一下。不過這件事情,在入職一年左右之後就回復正常了的樣子,但果然還是不能不信邪。筆者曾經看過一句話:「軟體產品和教堂幾乎是一樣的,首先我們把它建好,然後我們開始祈禱。」(Software and cathedrals are much the same – first we build them, then we pray. by Sam Redwine)
這篇所要介紹的,就是筆者第一次遇到的一個重大事件。這也應該是目前親手處理的事件中,最值得分享的一個吧。
事件是由一連串的 Pingdom DOWN 開始的。讀者如果不記得 Pingdom 是什麼,可以這個鐵人賽系列的第一篇文章,在基本監控系統中有詳細的介紹。簡而言之,該警報代表本身已經無法被存取,因此通常是最嚴重的警報等級。
在警報發生的那個時間點,該專案所有 Pingdom 有關的警報全部都叫了。換言之,不只是部分服務無法被存取,而是直接整個倒站了。
但最神奇的是,其實當下我嘗試直接存取該網站時,發現是完全可以存取的。而我們有一個負責對系統進行確認的團隊,也傳達了系統可以正常存取的訊息。
讀者到了這邊,也許可以稍微停一下,試著去想想看這裡發生了什麼事情,以及我們應該如何排查問題。第一個想法當然是假警報,或是說 Pingdom 本身出現了誤判。如果是這麼單純,就不會被放在這邊介紹了。
事實上筆者自己在警報發生的當下,是處在非常六神無主的狀況。雖然嘗試著去理解 Pingdom 所回覆的訊息,但沒有得到任何結果。尤其在警報的當下還可以正常存取網站,幾乎要直接判定是 Pingdom 的誤判了。
更精彩的是,其實當實另一個專案也傳來了嚴重的 P0 事件的消息 (到底八字是有多輕?)因此大概有一段時間內,這個警報是處於被筆者忽略的狀態。
幸好,資深工程師這時傳來了透過 DNS 查詢工具所得到的結果,證實了該服務的整個 name server 已經被取代為新了的結果。
在解釋主因之前,我們需要對 DNS 這個東西有一定程度的理解。請參考下圖,上圖以 Google 為例,在說明使用者存取服務時的請求路徑:

當使用者(Client)在網頁輸入「www.google.com」的時候,會送出一個 DNS 請求給最近的 DNS 伺服器。伺服器本身會記錄該網址相對應的 IP 位址(142.251.46.174),並將該資訊回傳給使用者。如果該 DNS 伺服器沒有相關資訊,就會朝更上層的伺服器詢問,直到某個有記錄相關資訊的伺服器為止。使用者獲得 IP 位址後,才會將原本真正的請求送到該 IP 位址所在的伺服器。
這邊需要注意的事情是,在這個 DNS 轉址的設定中,各個 DNS 伺服器的設定理論上要完全相同。但如果要更新設定,因為會是由比較上層的 DNS 伺服器先接收到相關設定,然後才慢慢將資訊更新給其它 DNS 伺服器。因此在設定更新後的一小段時間內,其實使用者仍有可能會存取到舊的 IP 位址。這件事情在「日常維運系列文」中的「維護模式」有提到過,而這件事情也與這次的事件有非常重要的關聯,因此讀者可以先記得一下這件事情。
與 DNS 相關的服務主要會有網域(domain)的購買與 DNS 轉址的設定。在 AWS 中與之相關的服務是 Route 53 ,也是我們這次事件中的專案所使用的服務。其它比較知名的就是 GoDaddy ,而許多 CDN 廠商也會提供相關服務。
一般使用者在購買網域之後,可以再設定 DNS 轉址的設定。比如上圖中, Google 這間公司購買了「google.com」這個網域,然後再設定 DNS 轉址為「『www.google.com』轉址為『142.251.46.174』」,因此使用者輸入了「www.google.com」的時候,就會被轉址到「142.251.46.174」。同時間 Google 還可以設定其它 root domain 為「google.com」的各種轉址設定,比如「api.google.com」等等。
然而,任何人都可以在任何 DNS 服務的地方設定相關的轉址設定。比如說,筆者現在就可以進入自己 AWS 帳號中的 Route 53 服務,並在裡面設定「將『www.google.com』轉址為『123.123.123.123』」,但這並不會影響「www.google.com」原本的服務。這與 DNS 設定中另一個相當重要的 Name Server Record (NS Record) 有關。請見下圖:
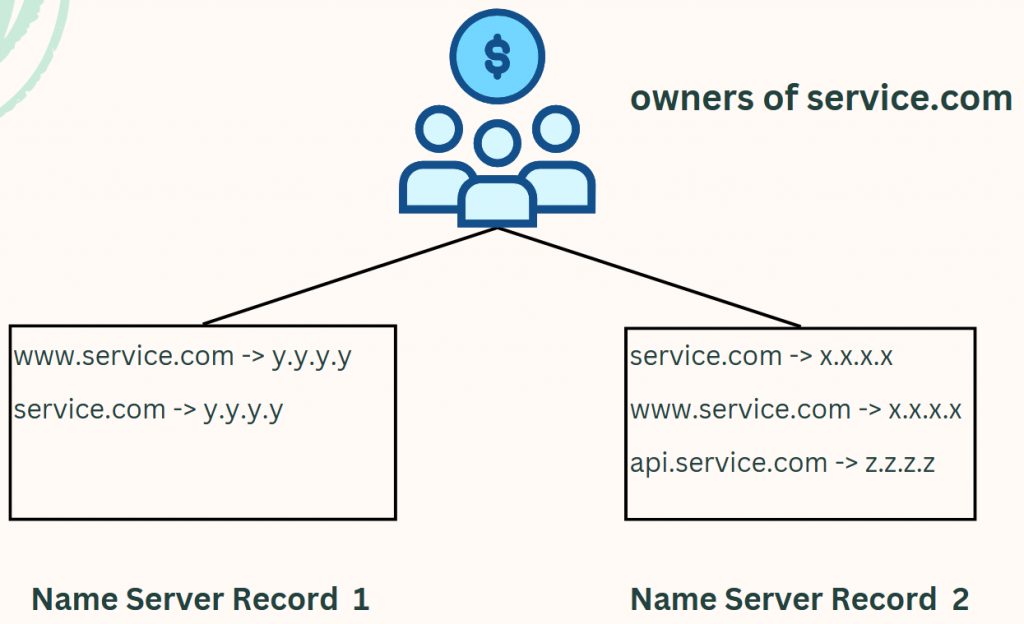
上圖中,以「service.com」這個網域為例。有兩個地方被指定了與之相關的 DNS 轉址設定,而這兩個地方各自有一個自己的 NS Record 。「service.com」的購買者(擁有者),則透過選擇 NS Record 的方式,來確認要套用哪一套 DNS 轉址設定。如果想要套用「將『www.service.com』轉址為『y.y.y.y』」的設定的話,就在已經購買好的「service.com」的頁面,指定 NS Record 為「Name Server Record 1」。
提個外話,這些知識都是筆者在事件發生後才惡補起來的。P0 事件的其中一個好處,就是會強迫工程師補上不足的知識呢。
在之前日常維運系列文章中的棒球賽中,有提到過專案本身是賣產品給另一個公司(客戶),而非直接面對使用者。針對 DNS 的合作方式,則是客戶自己購買了網域之後,透過將 NS Record 指定為我們的 DNS 轉址服務的方式,將 DNS 轉址相關的管理委派由我們處理。
事件主因其實非常單純,就是 NS Record 被修改掉了。請參考下圖:
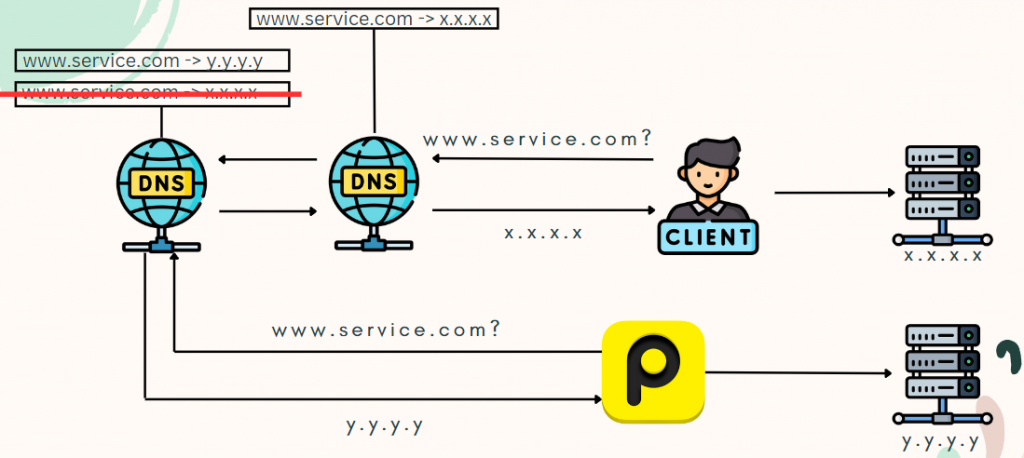
有了一些先備知識後,上圖應該非常好理解了。在 NS Record 被修改之後,原本「將『www.service.com』轉址為『x.x.x.x』」被變成了「將『www.service.com』轉址為『y.y.y.y』」。然而「y.y.y.y」的伺服器上面並沒有原本的服務,因此 Pingdom 在送請求的時候沒有得到預期的回應,就送出了 Pingdom DOWN 的警報。也因為改完 NS Record 之後,服務所有連結(比如網頁或 API )的 DNS 轉址都受到影響,因此所有與該專案有關的 Pingdom 警報都響了,才出現了倒站的結果。
然而前面有提到,在警報當下,其實我們還能夠正常存取網站。讀者還記得前面有提到, DNS 轉址設定會需要一點時間才能完全生效的事情嗎?我們還能夠正常存取網站的理由,就是因為距離我們最近的 DNS 伺服器,還存著尚未被修改掉的轉址設定。
換個說法,其實 24 小時內,我們應該就會陸陸續續無法存取網站了。而實際上,在警報發生後大約 4 個小時左右的時間,的確就有使用者開始回報無法存取網站的狀況。
從事後來看,我們所遇到的問題其實相當單純,就只要請客戶將 NS Record 修改回來即可。但不知道讀者有沒有在一開始,也自己思考一下問題的成因和釐清問題的方式呢?筆者想說明的是,如同 debug 一樣,要找到問題發生的理由其實並非一件簡單的事情。
正每個 P0 事件都會有一些獨立且特別的成因,要能成功找出問題並接續處理絕非容易的事情。這些都相當需要仰賴每次的實戰經驗,難以在事前學習或培養。而這也是筆者認為是SRE 之所以珍貴的其中一個理由。
在下一篇中,將會介紹這個事件的後續解決過程,以及事後筆者自己整理過後,認為值得分享給各位的一些技術相關的心得。


 iThome鐵人賽
iThome鐵人賽