上一篇談到了這次 P0 事件中的警報過程,以及具體的事件成因。在這一篇中,就要介紹接下來的一連串處理流程,以及在整個流程中筆者自己有學到,也認為值得分享的一些相關技術知識。但還是不得不說, P0 事件果然還是最快促使工程師成長的方式呢。
延續上一篇的說明,我們接下來要做的事情其實相當單純,就是請客戶把修改過的 NS Record 給修改回來即可。但這馬上迎來了第一個問題,就是客戶為什麼要修改 NS Record 呢?
事實上,這裡的描述方式與實際的處理流程還是稍微有些差異。因為我們首先要先確認,客戶到底是否真的有進行這次的修改。雖然技術上我們大致可以確認,只要客戶能夠做這個修改,因此上一篇文章中就跳過了這個流程,但實際上要進行不失禮貌的確認,也是會需要花點時間的。只是這一段主要會是產品經理的工作,與 SRE 的工作沒有什麼具體的關係就是了。
在確認客戶的確有修改的過程中,我們也同時理解了客戶修改 NS Record 的理由。其實非常單純,就只是因為他們想要修改某些 DNS 轉址的設定而已。具體而言,他們想要將修改某一個 DNS 轉址的設定,並新增一個 DNS domain。
按照在前一篇文章中有提到過的合作方式。因此正確的流程應該是,他們會送這個修改的相關請求資訊給我們。我們跟據他們所提供的資訊,來在正確的時間點執行相關規則的修改。但也許是因為某些溝通上或人員異動時交接上的誤會,導致他們最後直接選擇先修 NS Record 之後,再自己執行 DNS 轉址的設定。當然,這裡所提到的 DNS 轉址設定,就是他們自己另外有一個設定的平台,而不是用我們的了。
解決了一開始提到的第一個問題,接下來馬上就面臨了第二個問題,也就是溝通,或說是翻譯上的困難。由於在這個專案裡面的客戶是一間日本公司,在這個鐵人賽系列文章的第二篇「系統警報概論」中有提到,一般在發生這種緊急狀況時,會有一位通日語的產品經理,來負責傳達或翻譯相關的資訊。
當時其實有預先提及了,在某些非常複雜的情況下,我們可能會必須跳過產品經理來直接跟客戶溝通,而這次的事件就屬於這個類型。事實上,我們最後也是直接與對方的產品經理溝通,而非對方的工程師,因為對方的工程師應該是完全不會說英語。
跳過產品經理直接向客戶溝通其實是相當罕見的狀況,因為這必須同時符合「是緊急 P0 事件」、「狀況複雜到產品經理難以翻譯」以及「相關操作必須交給客戶來操作」這三個條件才行。一般而言,在一個事件中,以上三個條件只會一次符合兩個而已。
而在溝通的過程中,因為當下所有資訊都還不是非常明朗,因此從客戶的角度來看,他們無法理解為什麼我們希望他們修改 NS Record,而頻頻向我們確認這個操作的合理性,並再三要求我們要保證該操作不會破壞他們原本的設定。畢竟他們原本想要執行的 DNS 轉址設定,的確會在 NS Record 修改後被覆蓋掉沒錯,因此這個顧慮並非完全沒有道理。
而從筆者的角度而言,要求進行相關的設定修改是否能如預期修復網站,在當下也無法非常肯定。事實上,在溝通的當下,已經陸續有使用者開始反映網站無法存取的狀況( DNS 已經被更新了)。由於修改完 NS Record 之後一樣會面臨比較近的 DNS 伺服器還沒有被更新的可能性(對使用者來說),在同時還要以英語解釋相關技術細節的情況下,壓力可以說是非常大。
非常幸運的是,在修改完 NS Record 後,我們非常迅速地收到了 Pindgom UP 的通知,代表我們的操作正確無誤。緊急問題已經解決之後,剩下的就會是流程的改善,就主要會是產品經理的工作內容了。
但必須承認一件事情,由於筆者在當時對 DNS 相關知識的理解不足,因此在更換了 NS Record 之後,筆者並沒有接續修改客戶原本預期要做的 DNS 轉址設定,導致其實整個專案有部分的服務是處在壞掉的狀況,或說實際上,筆者的某些裝置可以存取,但另一些裝置不行(一樣是前面提到 DNS 伺服器的設定同步問題)。這個問題一直到晚上,筆者左思右想之後覺得實在不太勁,在真的搞懂這裡問題並按照客戶的需求來修改 DNS 轉址的設定後,才算是完全解決。
一直到現在,我們已經理解了整個事件的過程以及相關成因。這邊筆者想要分享一些當初有使用到,一些與 DNS 相關的指令和工具。這些都是由事件當下資深工程師所提供,且實際上有使用到的指令和工具。雖然希望是不要再用到啦,但也許能給讀者一些啟發。
digdig <DNS-server> <site url> ,可以用+short來只回覆IPdig service.com
dig @1.1.1.1 service.com
dig @8.8.8.8 service.com
dig <ns_name> service.com
在事件發生的當下,由於 DNS 伺服器同步設定還沒完成,因此出現了「詢問CloudFlare或Google」與「詢問最近的伺服器」的回應不同的狀況。這也是為什麼一開始,雖然 Pingdom DOWN 的警報已經響了,但我們與一般的使用者都還可以正常存取的狀況。
curlcurl [ipinfo.io/<ip_address>](http://ipinfo.io/<ip_address>)
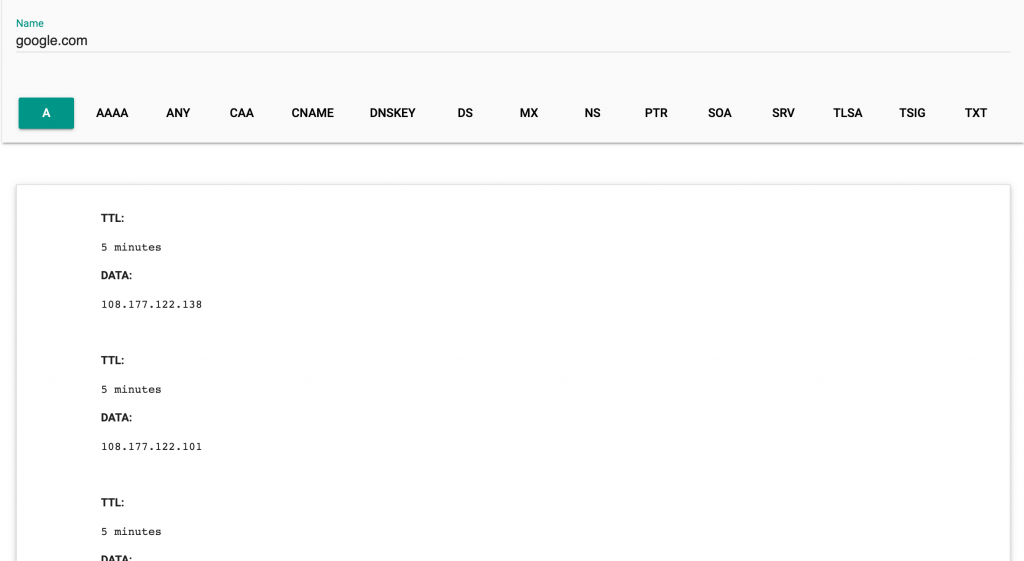
網址:https://toolbox.googleapps.com/apps/dig/
如果想要查詢 google.com 的 DNS 轉址設定,輸入該網址後可以得到如下圖的資料:
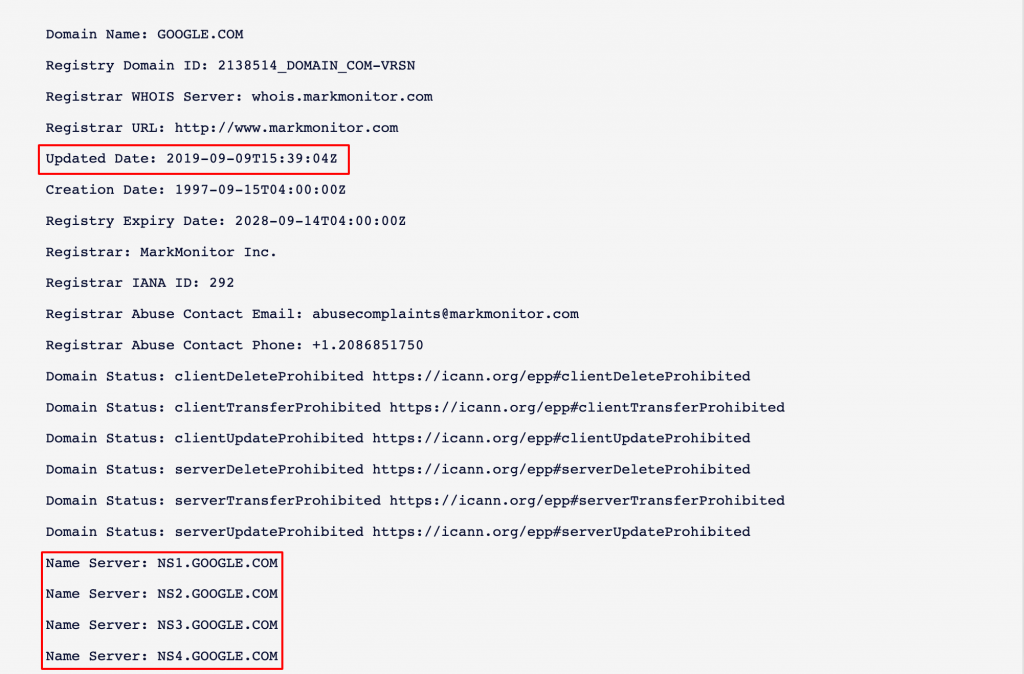
網址:https://www.gandi.net/en/domain/p/whois
輸入 google.com 後,可以看到該網域最後的修改時間( Updated Date )是 2019 年的 9 月 9 號。而在這次事件當下,我們發現專案的最後修改時間差不多就是在幾個小時之前而已,而且 Name Server 的設定也跟我們預期的完全不同,因此才確認,應該是客戶在幾個小時之前修改了 NS Record。
人生還是不要遇到太多次像這樣的事件才好。
但也必須承認,這個事件應該是筆者成為 SRE 一年以來,最精彩刺激,也是學到最多的一次事件。
然而,這邊最主要想分享給讀者的,還是希望讀者能從這個事件中,看出我們在一個事件中,可能可以如何追查事件成因,以及如何解決的流程。也同時能讓讀者理解, SRE 在一個重大 P0 事件中可能辦演的角色。
當然還是必須再強調一次, SRE 的日常工作只會有非常一小部分會撞到這種大型事件。而即使是大型事件,常常也會因為是程式面的問題,而讓 SRE 沒有主動介入的空間。像這樣如此麻煩,而且 SRE 必須全程參與的事件,真的只是一小部分而已。
接下來,會進入其它的重大 P0 事件。

