昨天先跟各位稍微介紹Autoencoder的架構以及類型,今天我們將更進一步說明Autoencoder的數學基礎,那我們正文開始!
自動編碼器(Autoencoder)是一種特定類型的神經網絡,主要設計用來將輸入資料編碼成壓縮且有意義的表示,然後再解碼回來,以使重建後的輸入資料盡可能地與原始資料相似。
他們定義函數為𝐴:R𝑛 → R𝑝(編碼器)和𝐵:R𝑝 → R𝑛(解碼器),並且滿足
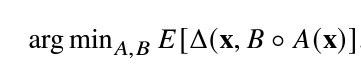
其中,𝐸表示對𝑥的分佈的期望值,Δ則是重建損失函數,用於衡量解碼器的輸出與輸入之間的距離。通常情況下,後者常被設置為L2-norm。
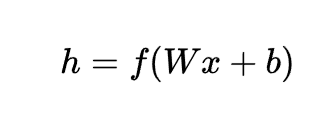
其中,h是編碼器的輸出,f是激活函數(例如Sigmoid、ReLU等)。
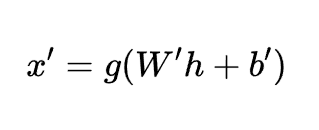
常用的損失函數包括均方差(Mean Squared Error,MSE):
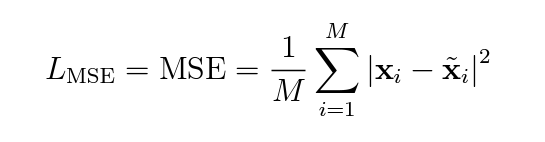
以及二元交叉熵(Binary Cross-Entropy):
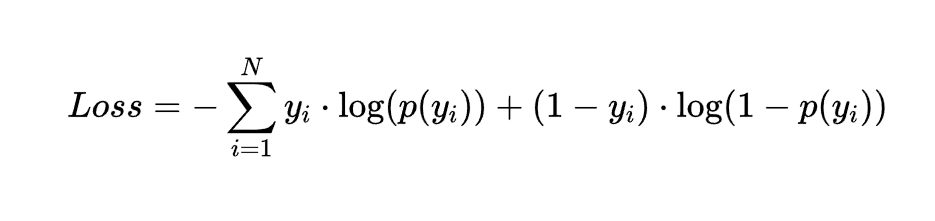
其中y 是實際標籤(0或1)。p(y)是模型的預測概率(0到1之間的實數)。
以上就是小弟我今天分享有關於用Autoencoder的基本數學樣式,明天將會分享Autoencoder實現MNIST手寫數據集的實作,那我們明天見!
參考連結:arxiv autoencoder


 iThome鐵人賽
iThome鐵人賽