前言
前幾天我們介紹且實作了GAN,並討論了其另外兩個變體,而今天我們終於要來到尾聲了-模型優化
正文
優化GAN模型是一個關鍵任務,可以提高生成質量、穩定性和效率,同時也是一個相當繁瑣的任務,需要不斷試驗和調整,在訓練時可能會造成以下影響。
- 模型不收斂,變得不穩定。
- 生成器產生的圖像缺乏多樣性和細節,並且難以與真實資料區分開來。
- 訓練時發生梯度消失。
因此,我們可以嘗試這些方式來優化模型
- 改進生成器和判別器,增加神經網路的複雜度可以提高模型的表示能力,有助於生成更逼真的數據。
- 使用正規化技術如批次正規化(Batch Normalization)可以幫助穩定訓練過程,減少模式崩潰問題。
- 使用深度卷積和轉置卷積層可以幫助模型捕獲更多的細節。
- 使用殘差連接可以幫助信息在網絡中更好地流通,有助於減少梯度消失問題。
而在改進損失函數方面也可以嘗試以下方法:
- 使用Wasserstein GAN(WGAN)或其變種:WGAN和其變種的損失函數可以改善訓練過程的穩定性,並提高生成質量。
- 有梯度規範的損失函數:例如,Gradient Penalty可以用於WGAN變種,有助於約束梯度的大小。
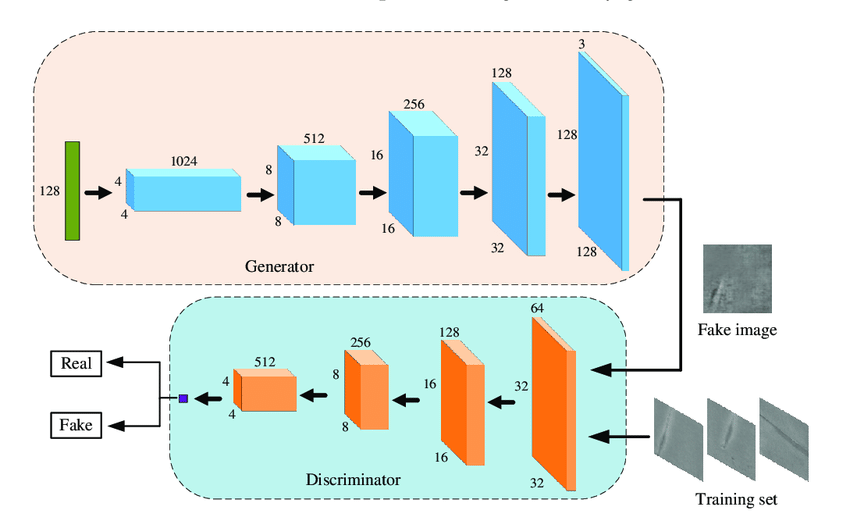
WGAN的架構圖:圖源
優化GAN模型需要不斷試驗和調整,並且需要對模型的表現進行評估和分析。其實優化GAN的方式與優化AE的方式大同小異,也可以使用樣本和數據預處理、超參數調整等方式來解決,詳情可以看[DAY20]Autoencoder的模型優化
參考網站:網站 網站
總結
以上就是今天介紹GAN模型優化的方法啦,不知不覺我們也來到了倒數第二天,明天將會是對這次自我挑戰的心得與感想,那我們明天見!


 iThome鐵人賽
iThome鐵人賽