歡迎回到我們的30天人臉技術探索之旅!在前面的幾天中,我們已經了解了人臉技術的基本概念、人臉偵測的重要性以及傳統的人臉偵測方法。今天,我們將深入研究人臉偵測領域的巔峰 — 基於深度學習的方法。
深度學習已經在計算機視覺領域取得了巨大的成功,並且在各種任務中超越了傳統方法。人臉偵測不例外,深度學習技術已經成為當今人臉偵測系統的主導力量。在本篇文章中,我們將深入探討基於深度學習的人臉偵測方法,重點關注一些最先進的架構,如MTCNN和Single Shot MultiBox Detector(SSD)。
MTCNN(Multi-task Cascaded Convolutional Networks)是一個流行的基於深度學習的人臉偵測架構,由Kaipeng Zhang等人於2016年提出。MTCNN具有三個網絡級聯,每個網絡都有不同的任務:人臉偵測、人臉對齊和人臉特徵點定位。以下是MTCNN的架構和訓練細節:
MTCNN如下圖由三個網絡組成:P-Net、R-Net和O-Net。這些網絡依次應用,以實現人臉偵測,對齊和特徵點定位。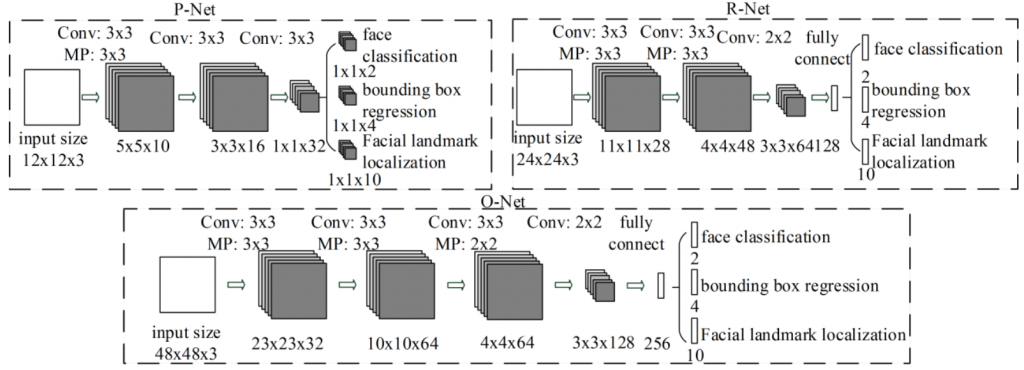
以下是每個網絡的詳細信息:
Proposal Network(P-Net)
P-Net是MTCNN的第一個網絡,它的主要任務是生成潛在的人臉候選區域(bounding boxes)。它是一個小型的卷積神經網絡,一共包括兩個分支:一個用於二元分類(人臉/非人臉),另一個用於回歸(邊界框調整)。P-Net 通過滑動窗口方式在圖像上生成多個候選區域,然後通過二元分類器確定哪些候選區域包含人臉,哪些不包含。
Refine Network(R-Net)
第二個網絡稱為Refine Network(R-Net),顧名思義它是用來調整的。R-Net對P-Net生成的候選區域進行進一步的篩選和調整。它同樣是一個卷積神經網絡,不僅確定區域是否包含人臉,還對候選區域的邊界框進行精確調整,以更好地對齊人臉。
Output Network(O-Net)
O-Net是MTCNN的第三個網絡,它專注於在檢測到的人臉上定位重要的特徵點,如眼睛、鼻子和嘴巴。O-Net通過回歸問題來預測這些特徵點的精確位置,同時還執行人臉/非人臉的二元分類。
我們使用下圖來描述整個模型的運作過程: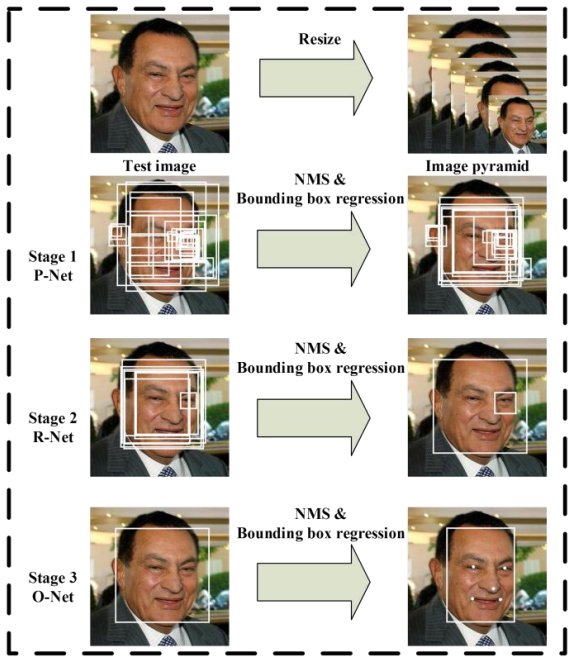
詳細步驟:
假設我們的照片為
Step.1 我們先把輸入的照片 resize 成各種大小的照片,resize N 次,每次 resize 成為面積的一半,這樣一共有 N + 1 張照片,最小 12x12 的大小(符合 P-Net 的輸入大小),然後我們將這 resize 後的照片丟進 P-Net 去生出一堆模型覺得可能是臉的框,作法是切下一塊塊 12x12 大小的 patch,可以想成想要判斷不同 scale 的範圍內有沒有人臉。模型每次 output 都是 16 維的,包含以下東西:
* 2 維的使否有人臉分類 ( 有的機率, 沒有的機率
* 4 維人臉 bounding box 的 offset (因為切下來的 patch 可能歪歪的所以回傳預測 框應該在哪裡
* 10 維的人臉關鍵點位置(一共5個點,每個點有 x, y 座標
最後我們把所有的框丟進使用NMS計算去除掉重複範圍的框
Step.2 我們把 P-Net 大致找到可能是人臉的框放大回原圖並且 resize 成為 24x24 大小的圖片並且交由 R-Net 去預測然後再執行跟 P-Net 相同的計算得到相同的 16 維然後一樣採取一樣的判斷處理
Step.3 基本上與 O-Net 執行上述兩部相同,記得 resize R-Net 的結果成為 48x48圖片就好!
MTCNN的訓練過程相對複雜,因為它涉及多個網絡和多個任務。以下是MTCNN的訓練步驟:
訓練P-Net
P-Net首先在大型人臉數據集上進行訓練,用於生成候選區域。訓練包括二元分類(人臉/非人臉)和邊界框回歸兩個任務。通過這一訓練,P-Net學會了生成初步的人臉候選區域。
訓練R-Net
R-Net接受P-Net生成的候選區域,進一步篩選和調整這些區域。R-Net的訓練也包括二元分類和邊界框回歸,以確保生成的區域更精確地對齊人臉。
訓練O-Net
O-Net的訓練是最複雜的,因為它需要預測特徵點的位置。O-Net在眼睛、鼻子和嘴巴等位置預測關鍵點,同時執行人臉/非人臉的二元分類。這一訓練確保了偵測到的人臉具有準確的特徵點位置。
MTCNN的訓練需要大量的標註數據,這些數據包括人臉圖像和對應的標籤,如人臉位置和特徵點位置。這些數據集包含大量多樣化的人臉圖像,確保模型能夠處理各種場景和變化。一些常用的人臉偵測資料集包括:
WIDER Face:這是一個大型的人臉偵測資料集,範例如下圖,包含在不同條件下的數萬張圖像(ex.不同大小,角度,遮擋,表情等等),其中有多個人臉實例以及每個實例的邊界框和特徵點標註。可由 WIDER Face 官網上下載
CelebA:這個資料集主打包含各種名人的圖像,其中包括多個人臉。它被廣泛用於人臉偵測和識別的研究。官方下載位置在這
FDDB:FDDB(Face Detection in the Wild)是一個針對自然場景中人臉的資料集,它包含各種環境中的人臉圖像,如戶外、室內等。官方下載位置
MTCNN是一個強大的基於深度學習的人臉偵測工具,它的優勢在於它的多級聯結結構,允許模型在多個階段進行人臉檢測,每個階段都有不同的任務。這種分階段的方法使MTCNN能夠在不同尺度和精度下進行人臉檢測,可以實現高性能的人臉偵測、對齊和特徵點定位。該模型的訓練過程需要大量標註數據,並包括多個任務,如二元分類和回歸。通過MTCNN,我們可以實現準確和穩定的人臉偵測,這在許多應用中都是至關重要的。
其他大家常聽到的 Object detection 框架其實也都可以拿來改成預測人臉位置,像是知名的 SSD(Single Shot MultiBox Detector)是一種多用途的目標檢測架構,旨在檢測圖像中的多個目標,包括人臉。那因為他在其他地方已經有足夠多的介紹了,我們重心就不放在這。它以其簡單性和高效性而聞名,適用於實時應用。以下是SSD的主要結構特徵:
基礎網絡
SSD的基礎網絡通常使用卷積神經網絡(CNN)來提取圖像特徵。常見的選擇包括VGGNet、ResNet和MobileNet等。這些網絡負責從輸入圖像中提取特徵,這些特徵將用於目標檢測。
多尺度特徵圖
SSD引入了多尺度特徵圖的概念,這些特徵圖來自基礎網絡的不同層級。這些特徵圖具有不同的解析度,可以檢測不同尺寸的目標。多尺度特徵圖有助於處理不同大小的人臉。
多個檢測層
SSD的檢測層通常位於多尺度特徵圖的不同層級上。每個檢測層都負責檢測特定尺寸範圍內的目標。每個檢測層由兩部分組成:
卷積層:卷積層用於從特徵圖中提取目標的位置和類別信息。
檢測框生成層:檢測框生成層負責生成檢測框,通常使用不同尺寸和長寬比的錨點(anchors)來生成檢測框。
類別分數:這些分數用於確定目標的類別,包括人臉和其他可能的目標類別。
邊界框坐標:這些坐標用於確定目標的精確位置。它們定義了檢測框的位置和大小。
先驗框(Prior Boxes):
SSD使用先驗框來定義不同形狀和尺寸的邊界框,這有助於提高檢測準確性。
非極大值抑制(NMS)
為了去除重疊的檢測框,SSD使用非極大值抑制(NMS)技術。NMS確保每個目標只有一個檢測框與之相關聯,從而消除多重檢測。
訓練SSD模型需要大規模標註的資料集,這些資料集包含圖像以及對應的目標(人臉)位置和類別標籤。訓練自己的人臉偵測模型基本上直參考這個連結即可,包括以下步驟:
資料準備:載入訓練資料集,包括圖像和對應的標籤。資料集中的每個人臉都有一個對應的類別標籤(人臉)和邊界框坐標。
特徵提取:將訓練圖像通過基礎網絡,獲取多尺度特徵圖。
檢測框生成:對每個多尺度特徵圖生成一組預定義大小和比例的錨點,這些錨點用於生成檢測框。
損失計算:計算預測的類別分數和邊界框坐標與真實標籤之間的損失。SSD使用多個檢測層,每個檢測層都有自己的損失。
反向傳播:根據損失值調整模型的權重,使用反向傳播算法。
重複訓練:重複執行上述步驟,直到模型達到滿意的性能水準。
# Intialize detector
detector = cv2.dnn.DetectionModel("ssd.caffemodel", "deploy.prototxt")
# Read image
img = cv2.imread("image.jpg")
# Getting detections
detections = detector.detect(img)
基於深度學習的人臉偵測方法代表了當今最先進的技術,具有出色的準確性和效率。MTCNN和SSD等架構為人臉偵測帶來了重大突破,使其成為許多應用的核心組件。然而,人臉偵測仍然面臨著一些挑戰,如低光照環境和不同尺度的人臉。因此,研究人員仍在不斷努力改進這些方法,以實現更廣泛的應用。

