全局模型解釋是試圖理解整個模型的行為,而不僅僅是對單個預測進行解釋。Permutation importance 方法就是一種廣泛用於評估機器學習模型特徵重要性的技術之一,而且它是一種與模型無關的可解釋技術。
此模型解釋方法通常會返回每個特徵的重要性分數,分數越高則該特徵對於模型的影響性越大。因此當我們對其中一個特徵數值修改後對整體預測結果變動很大,可以推論該特徵可能是重要的。具體來說就是把一個特徵的某個值替換成另一個值之後,到底會對預測 error 有多大的影響。以預測區域房價為例,Permutation importance 算出來結果越小的話代表該特徵一點都不重要,有無它都沒關係。而計算出來越大的特徵,例如收入對於該地區的房屋價格預測是有很大的貢獻。
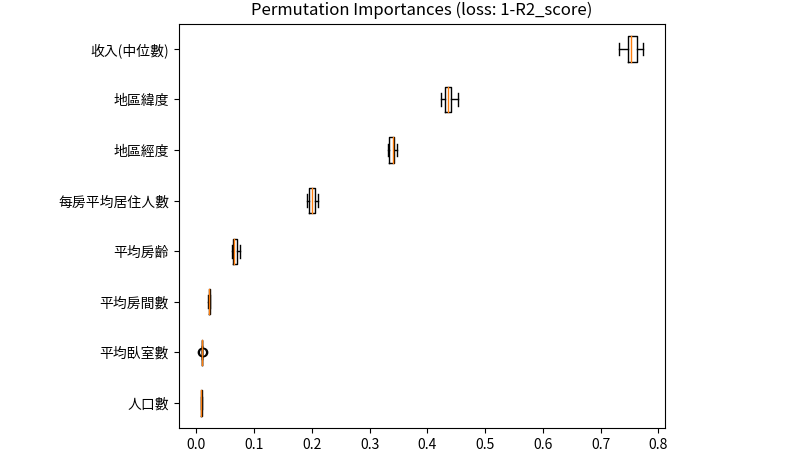
Permutation importance 的基本概念是將資料集中的每個特徵進行隨機重排,然後測試模型在重排後數據上的推論變化。如果某個特徵隨機排列對模型的預測產生了顯著的影響,則可以推斷該特徵對模型的重要性較高。

實際步驟如下:首先用訓練資料訓練一個模型,接著用測試資料及對每筆資料做預測並計算一個分數。R2 分數是評估一個迴歸模型有多好,所以 1-R2 代表預測結果有多不好。而 AUC 是衡量分類問題的指標越接近 1 越好,因此 1-AUC 可以視為該模型預測多麼不好,類似於 Error 的感覺。當然分類問題也可以使用準確率。接著如果我們要對特徵 x 來查看有多重要,就是隨機的對 x 特徵替換掉其他的數值最後再計算這個 Error 有多大。因此 Permutation importance 計算某特徵的重要程度公式為,搗亂之後的error/原始乾淨資料集的error,又或是兩個分數相減。
重複2、3步驟直到所有特徵都執行過一遍。
eli5 是一個解釋機器學習模型的 Python 套件,其中提供了 Permutation Importance 的方法。它可以計算模型的特徵重要性,並將其可視化為一個長條熱圖,可以快速地比較每個特徵的重要性。首先透過 pip 安裝 eli5 套件:
pip install eli5
接著載入今天的範例測試集。fetch_california_housing 是 sklearn 中的一個內建資料集,用來預測加州地區的房屋價格中位數。這個資料集包含了 8 個特徵,分別是:
這個資料集包含了 20640 筆樣本,每個樣本都有上述 8 個特徵以及房屋價格中位數作為目標變數。
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
import numpy as np
# 載入加州地區房屋價格預測資料集
data = fetch_california_housing()
feature_names = np.array(data.feature_names)
X, y = data.data, data.target
# 切分資料集為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 訓練隨機森林迴歸模型
model = RandomForestRegressor(random_state=0).fit(X_train, y_train)
本範例訓練一個隨機森林模型,並使用了 eli5 套件中的 PermutationImportance 方法,用於計算每個特徵在模型中的重要性。程式碼中的 model 是指建立好的機器學習模型,而 X_test 和 y_test 則是測試資料集。
import eli5
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(model, random_state=42).fit(X_test, y_test)
eli5.show_weights(perm, feature_names = feature_names, top=8)
上述程式碼中使用 PermutationImportance 方法來計算每個特徵的重要性,並將結果存入 perm 變數中。在計算過程中,random_state 參數用於確保結果的再現性。接著使用 eli5.show_weights 方法將結果可視化。feature_names 參數是特徵的名稱列表,top 參數則用於指定要顯示的重要性排名前幾的特徵。這個方法將會顯示每個特徵的名稱以及其對應的重要性分數,分數越高表示該特徵對模型的影響越大。
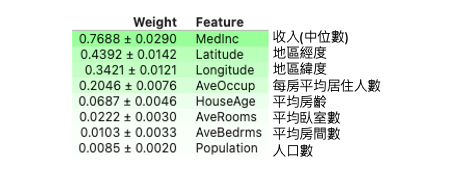
上面的結果,可以看到最重要的特徵是該地區的收入中位數,確實挺合理的。若出現紅色負數的分數其實都可以視作幾乎不重要的變數。
Permutation importance 的優點是可以用於任何模型演算法和任何資料集,並且可以提供關於每個特徵的直觀解釋。值得注意的是該方法忽略了特徵之間的交互作用,即特徵之間可能存在依賴關係,某些特徵在單獨考慮時看似不重要,但在與其他特徵結合後可能會產生重要的影響。因此,Permutation importance 方法不能完全代表特徵對模型的影響,而應當結合領域知識、模型內部解釋等多種方法進行綜合評估。另外它的缺點是計算量較大,特別是在資料集較大、特徵較多的時候。若想同時考慮到兩個特徵對於輸出的影響該怎辦?明天就會來跟大家介紹另一種 Model Agnostic 全局解釋的方法 Partial Dependence。
本系列教學內容及範例程式都可以從我的 GitHub 取得!
R2 分數是評估一個迴歸模型有多好,所以 1-R2 代表預測結果有多不好。而 ROC 是衡量分類問題的指標越接近 1 越好,因此 1-ROC 可以視為該模型預測多麼不好,類似於 Error 的感覺。
這邊有點混淆?因為 ROC 不是指標,而是一個曲線。通常衡量的指標應該是AUC (Area Under the ROC Curve)。正確說法應該是「AUC 越接近 1 越好」。
已修正謝謝hlb布丁提醒!確實用AUC來說會比較精準。

