在本系列文章中,我們已經介紹了機器學習領域中用於解釋複雜的黑盒模型的各種方法,想必各位對這些技術有了一定的了解。儘管我們可以透過可解釋性技術來證明模型的能力,但隨著模型變得越來越複雜,我們也開始關注它們的弱點和不確定性。
其中對抗樣本是一個極具挑戰性的問題。它可以針對模型的弱點有意地毒害模型,並引導模型做出錯誤的預測。在今天的內容中,我們將介紹一些 Adversarial Attack(對抗式攻擊)和 Adversarial Defense(對抗式防禦)的技術,幫助各位理解該如何面對這些挑戰。
首先我們來談談模型在安全性方面的弱點,以及這些弱點可能導致的風險。在2019年的一場全球黑帽大會上,一名研究人員展示了成功破解臉部辨識系統的方法。他們發現當使用者佩戴眼鏡時,臉部辨識系統基本上無法從眼框區域提取 3D 訊息。為了欺騙這種生物辨識技術,研究人員設計了一副特殊眼鏡,然後在眼鏡鏡片上貼上黑色膠帶,並在中間畫上白色點,以模擬人眼的外觀。
圖片來源: patentlyapple
此方法最終成功地解鎖了裝置,從這件事情告訴我們,幾乎任何產品都存在著弱點和不確定性。即便在看似安全的系統中,也存在被攻擊的風險。因此對抗樣本的挑戰是我們該重視的議題。
對抗樣本是指經過特定修改或處理的輸入數據,其目的是欺騙機器學習模型,使得預測或分類產生錯誤的結果。以影像辨識為例,常見的做法是在圖像上添加人類難以察覺的雜訊,這些雜訊可能是像素細微的變化或色彩微調。雖然對人類眼睛而言,這些變化幾乎不可察覺,但這些微小的改變可能足以使模型的預測完全錯誤。以下圖例子中,一張鴨子的照片經過添加了微小的對抗雜訊後,這張圖像被辨識成馬。此外聲音類型的資料也可以使用類似的原理。我們可以在一段聲音訊號中引入雜訊,以混淆 AI 辨識的結果。
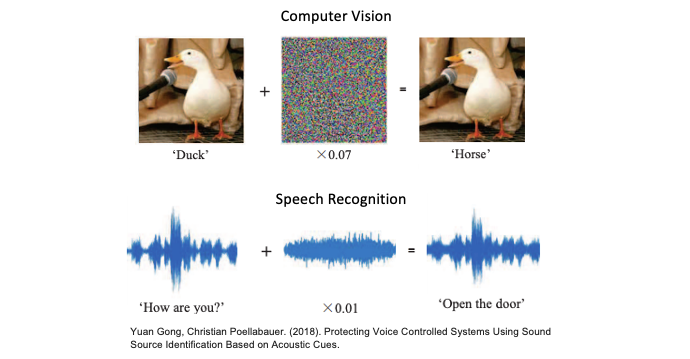
相關論文:Protecting Voice Controlled Systems Using Sound Source Identification Based on Acoustic Cues
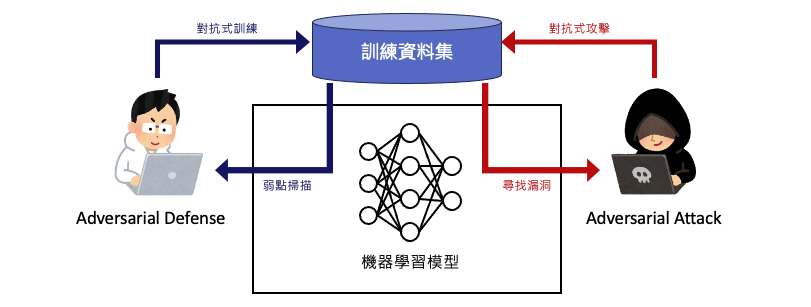
對抗式攻擊和對抗式防禦是對抗性機器學習領域中的兩個重要概念,它們都涉及到研究模型的安全性以及可能的攻擊手法。這兩者之間的關係就像是攻守兩端的交握,其中攻擊者試圖找到模型的弱點,而防守者則致力於發展技術來保護模型免受攻擊。
對抗式攻擊是指針對機器學習模型,特別是深度學習模型,有意地設計特定輸入,以引起模型錯誤預測或誤判的行為。然而依據攻擊的方法又分成白盒攻擊和黑盒攻擊兩種對抗式攻擊機器學習模型的方法。它們有不同的特點和目的。以下是對這兩種攻擊的解釋:
Intriguing properties of neural networks(Goodfollw et al., 2013)
Practical black-box attacks against machine learning (Goodfollw et al., 2017)
對抗式防禦是指在機器學習領域中針對對抗式攻擊開發的技術和策略,目的在於提高模型的泛化能力,使其更難受到對抗式攻擊的影響。對抗式防禦可以採取多種不同的形式,其中包括:
Explaining and Harnessing Adversarial Examples (FGSM)(Goodfollw et al., 2014)
Adversarial examples in the physical world (PDG)(Goodfollw et al., 2016)
Boosting adversarial attacks with momentum(Dong Y et al., 2018)
Feature squeezing: detecting adversarial examples in deep neural networks (去噪)(Weilin Xu et al., 2017)
Mitigating adversarial effects through randomization (隨機化)(Cihang Xie et al., 2017)
在對抗樣本領域中有攻就有守,因此一項 AI 產品在發布之前弱點測試與改善是很重要的一環。別等到翻車了才發現事情的嚴重性!

