今天先介紹怎麼把模型存下來,神經網路在訓練的時候所有權重都是存在記憶體中的,只要程式或電腦關掉這些資料就會消失,因此我們必須將這些訓練好的資訊存到硬碟中。
PyTorch 模型將學習到的參數儲存在內部狀態字典中,稱為state_dict。這些可以透過以下方法保存torch.save :
torch.save(model.state_dict(), 'cat_vs_rabbit_cls_v1.pth')
要載入模型權重,您需要先建立相同架構的物件,然後使用load_state_dict()方法載入參數。利用to.(device)將模型放到同個運算機器上(如果dataloader和model不同機器會報錯哦)
reload_model = NeuralNetwork(3*224*224)
reload_model.load_state_dict(torch.load('cat_vs_rabbit_cls_v1.pth'))
reload_model.to(device)
reload_model.eval()
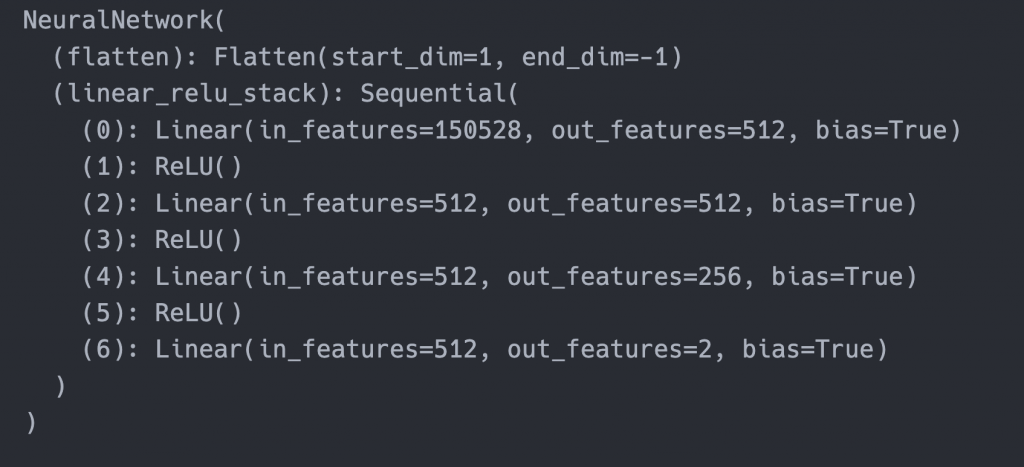
跑測試看看模型有沒有載入成功,我們可以利用測試的函數,不過只需要跑一次就好:
def test_loop(dataloader, model):
model.eval()
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
epochs = 1
for t in range(epochs):
test_loop(val_dataloader, reload_model)
可以看到準確率有 72% 左右 (因為我有重新訓練模型,所以和昨天準確率不同是正常的)
今天先介紹怎麼存取模型,明天會開始試著優化我們的架構。

