現在我們有了一個模型和數據,是時候通過優化模型的參數來訓練、驗證和測試我們的模型了。訓練模型是一個迭代的過程;在每一次迭代中,模型對輸出進行猜測,計算其猜測的錯誤(損失),收集錯誤相對於其參數的導數(正如我們在前一節中所看到的),然後使用梯度下降優化這些參數。
引入要用到的套件:
import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import os
建立資料集和Dataloader
train_path = './cat-vs-rabbit/train-cat-rabbit'
test_path = './cat-vs-rabbit/test-images'
val_path = './cat-vs-rabbit/val-cat-rabbit'
# 正規化是機器學習常用的資料前處理,將資料範圍變成[0,1]之間
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.RandomCrop(224), # 隨機裁減
transforms.RandomHorizontalFlip(), # 圖像水平翻轉
transforms.ToTensor(), # 轉成 tensor 格式
normalize
])
# 建立資料集
train_dataset = datasets.ImageFolder(train_path, transform = transform)
val_dataset = datasets.ImageFolder(val_path, transform = transform)
test_dataset = datasets.ImageFolder(test_path, transform = transform)
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=64, shuffle=True)
取得要運算的裝置(CPU、GPU等)
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
如果使用GPU會顯示CUDA:
class NeuralNetwork(nn.Module):
def __init__(self, img_size):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(img_size, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork(3*224*224).to(device)
print(model)

用來控制模型優化過程。不同的超參數值可以影響模型的訓練和收斂速度。以下定義較常使用到的參數:
Number of Epochs: 表示在數據集上迭代的次數。
Batch Size:輸入多少樣本數後更新網路參數。
學習率(Learning Rate)- 表示在每個批次中更新模型參數的程度。較小的值會導致較慢的學習速度,而較大的值可能在訓練過程中較不穩定。
這些超參數對於訓練模型的性能和訓練速度都具有重要影響,通常需要調整它們以達到最佳的訓練結果。(在做專案的過程中慢慢抓到怎麼設計)
learning_rate = 1e-3
batch_size = 64
epochs = 10
Loss Function:提供訓練數據給未經訓練的神經網絡時,他很難給出正確的答案。損失函數(Loss Function)用來衡量輸出的結果和目標值之間的差異程度,因此訓練過程中,希望最小化這個損失函數。
Optimizer:優化是在每個訓練步驟中調整模型參數以減少模型誤差的過程。優化演算法定義了如何執行這個過程(在這個示例中,我們使用了隨機梯度下降)。PyTorch中還有許多不同的優化器,如ADAM和RMSProp,適用於不同類型的模型和數據。
# 初始化loss function
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
透過迴圈來訓練和優化我們的模型,每個迭代被稱為一個 Epoch (所有樣本跑過一次)。
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
# 將資料讀取到GPU中
X, y = X.to(device), y.to(device)
# 運算出結果並計算loss
pred = model(X)
loss = loss_fn(pred, y)
# 反向傳播
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
Validation/Test Loop: 遍歷測試數據集,檢查模型性能是否在改善,驗證資料時不會更新權重,因此要記得加入with torch.no_grad():
要特別注意驗證資料跟訓練資料不能混到!!!
def test_loop(dataloader, model, loss_fn):
model.eval()
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
# 驗證或測試時記得加入 torch.no_grad() 讓神經網路不要更新
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(val_dataloader, model, loss_fn)
print("Done!")
從訓練過程中可以看出準確率有提高,但是 70% 是不是不太夠呢?
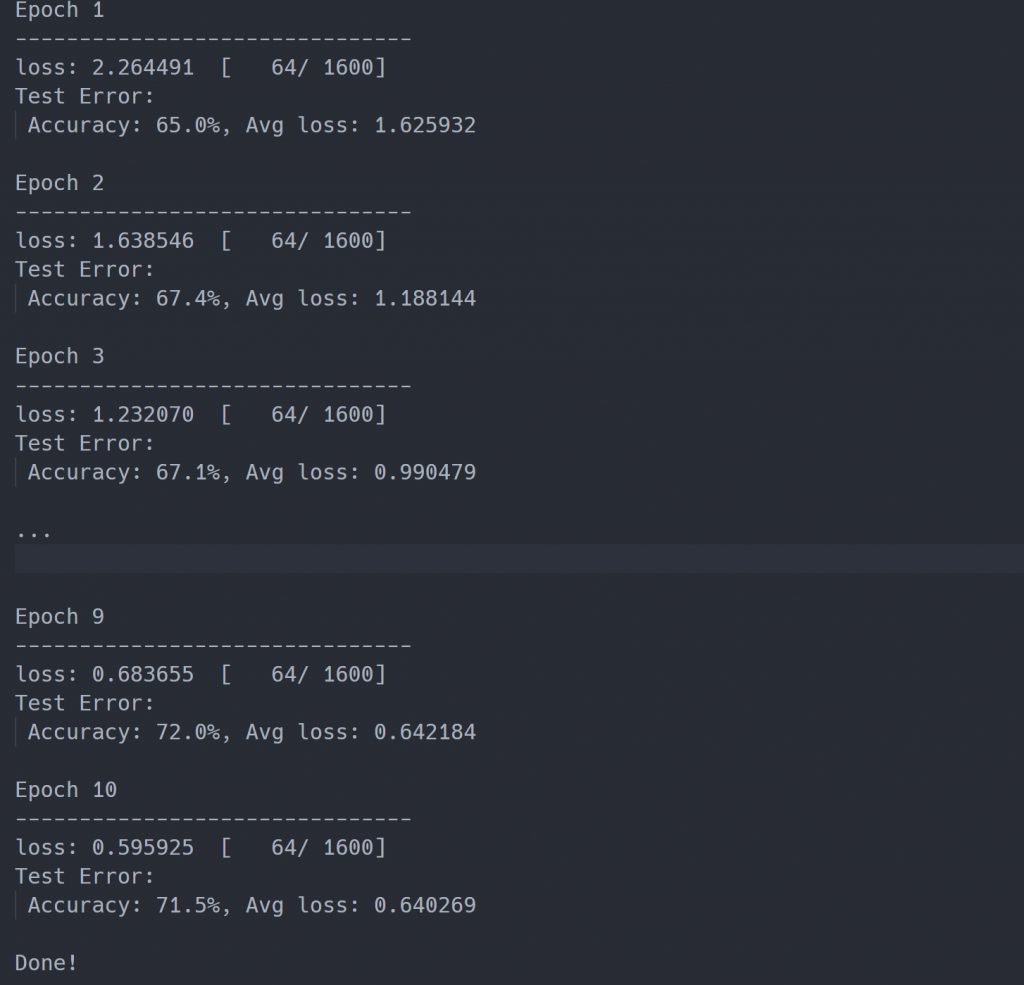
今天整合了所有介紹過的流程,訓練簡單的三層神經網路,準確率有達到 70% 左右,我們應該想辦法讓準確率提高,明天會講解怎麼透過修改模型來增加模型的效能。

