昨天跟各位分享了Convolutional Autoencoder的相關理論,而今天將會分享如何用CAE實現MNIST數據集圖像重建,那我們廢話不多說,正文開始!
其實code跟Autoencoder沒差多少,所以我直接作修改
MNIST是Tensorflow內建的手寫數字數據集,因此不需要從網路上下載!
先載入所需的套件
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
然後我們需要載入MNIST數據集,然後再進行前處理
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.expand_dims(x_train, axis=-1)
x_test = np.expand_dims(x_test, axis=-1)
MNIST數據集的圖片為黑白圖,因此顏色深度為0到255,
我們將測試集和訓練集的數據轉為浮點數,並且將像素值縮到0到1的範圍內,然後我們需要將數據集的形狀從[28,28]修改為[28,28,1]
接下來我們要設定模型的基本參數
input_img = tf.keras.Input(shape=(28, 28, 1))
這裡我們創建一個輸入層,輸入形狀為[28,28,1]—也就是我們數據集的形狀
接下來就是構件模型了~
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
x = tf.keras.layers.MaxPooling2D((2, 2), padding='same')(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same')(x)
encoded = tf.keras.layers.MaxPooling2D((2, 2), padding='same')(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same')(encoded)
x = tf.keras.layers.UpSampling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = tf.keras.layers.UpSampling2D((2, 2))(x)
decoded = tf.keras.layers.Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = tf.keras.Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
我們先建立了兩層捲積層(Conv2D layer),然後在每個捲積層下增加一個池化層(MaxPooling2D),並且使用了ReLU激活函數。然後再建立了另一個捲積層,激活函數為sigmoid。接下來我們創建一個單獨是編碼器以及解碼器的模型就可以了!
最後的部分是編譯的動作,我們使用Adam 優化器且損失為二元交叉熵
接下是訓練模型以及預測
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, shuffle=True, validation_data=(x_test, x_test))
decoded_imgs = autoencoder.predict(x_test)
這樣就訓練的部分就完結了!接下來我們來將重建的圖片以及原圖做比對
n = 2
plt.figure(figsize=(4, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
在這邊我重建兩張圖片,並且讓他們形狀從784轉變為原本的28*28,這樣就可以看到重建的結果了~
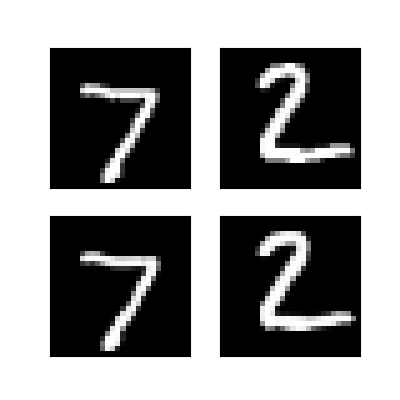
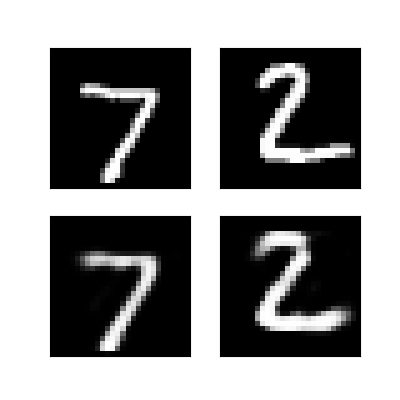
上面是Convolutional Autoencoder的結果,下面是Autoencoder的結果
這邊我們拿使用全連接層的結果與使用捲積層作比對,可以發現捲積層所重建出來的結果比使用全連接層佳
參考網站:The Keras Blog
以上就是小弟我今天分享有關於用Convolutional Autoencoder實現MNIST數據集圖像重建,明天將會分享另一個變體—Denoising Autoencoder,那我們明天見!


 iThome鐵人賽
iThome鐵人賽