昨天跟各位分享了Autoencoder的應用,今天我們來分享Autoencoder的變體—Convolutional Autoencoder,那我們廢話不多說,正文開始!
CAE全名叫做Convolutional Autoencoder(捲積自編碼器),其實他跟Autoencoder一樣,用來處理沒有標記特徵的資料或將資料進行降維與資料特徵的擷取,而構造也是編碼器加上解碼器,而為什麼在前面多了捲積呢??因為在模型中是使用捲積層(CNN)來取代全連階層(Dense),使其更適合處理圖像等具有空間結構的數據,接下來我們先稍微解釋一下甚麼是捲積吧!
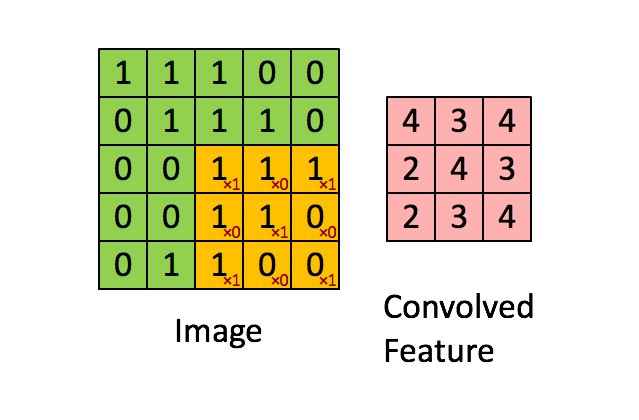
卷積神經網路是人工神經網路的一種特殊類型,在其至少一層中使用稱為卷積的數學運算代替通用矩陣乘法。它們專門設計用於處理像素資料,並用於圖像辨識和處理,以下是CNN的運算方式:
卷積層可以產生一組平行的特徵圖(feature map),它通過在輸入圖像上滑動不同的卷積核並執行一定的運算而組成,滑動的步長稱為Stride。此外,在每一個滑動的位置上,卷積核與輸入圖像之間會執行一個元素對應乘積並求和的運算以將範圍內的資訊投影到特徵圖中的一個元素。卷積核的尺寸要比輸入圖像小得多,且重疊或平行地作用於輸入圖像中,一張特徵圖中的所有元素都是通過一個卷積核計算得出的,也即一張特徵圖共享了相同的權重和偏置項。
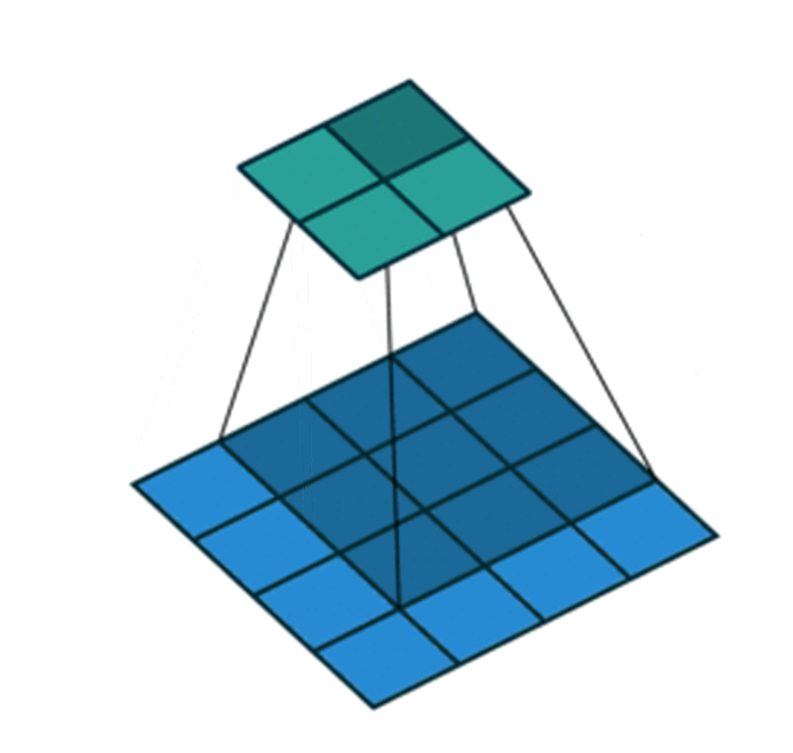
動圖詳情可看圖源(我怕丟到imgur被吃版權)
圖源:CDSN
有時圖像跟捲積核進行捲積的時候結果會損失部分值,這不是我們要的結果,因為我們的結果跟輸入大小應該一致,因此我們必須對原輸入進行填充(padding)以保證結果的大小一致
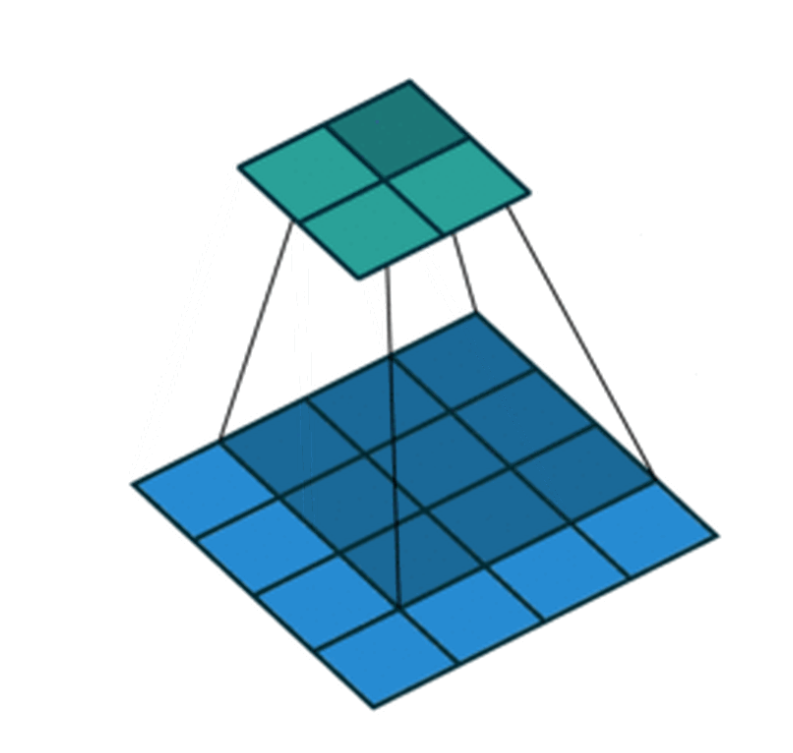
動圖詳情可看圖源(我怕丟到imgur被吃版權)
圖源:CDSN
說完捲積層之後,我們就來說說一下池化層吧
池化層通常會在捲積層後面,主要的目的是減少特徵圖的空間維度,同時保留最重要的資訊
常見的有最大池化(Max Pooling)和平均池化(Mean Pooling),最大池化在每个池化窗口中選擇最大值來保留最明顯的特徵,而平均池化則是顧名思義,計算其平均值幫助降低維度
以下是池化層的操作過程
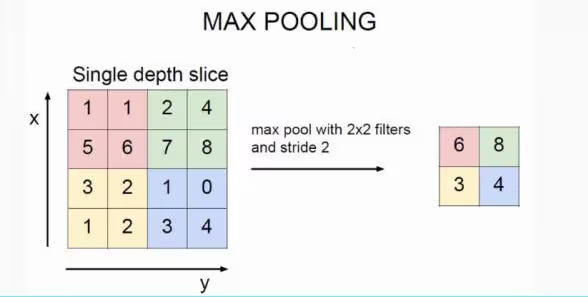
圖源:知乎
以上就是小弟我今天分享有關於Convolutional Autoencoder(CAE)的小知識,明天將會進一步使用捲積自編碼器進行實作,那我們明天見!


 iThome鐵人賽
iThome鐵人賽