昨天我們撰寫了大量的程式碼,所以現在你的大腦可能會有些混亂,因此今天我們不打算學習太多新知識,而是讓你讓心情先平復一下,所以我們來稍微了解一下時間序列模型的進階概念Seq2Seq吧,如果你已經瞭解時間序列模型,那麼對於今天的內容,你一定能輕易掌握,今日的重點如下:
Seq2Seq(序列到序列)的數理公式Encoder(編碼器)與Decoder(解碼器)所扮演的角色Teacher Forcing(教師強制)與貪婪解碼(Greedy Decoding)的策略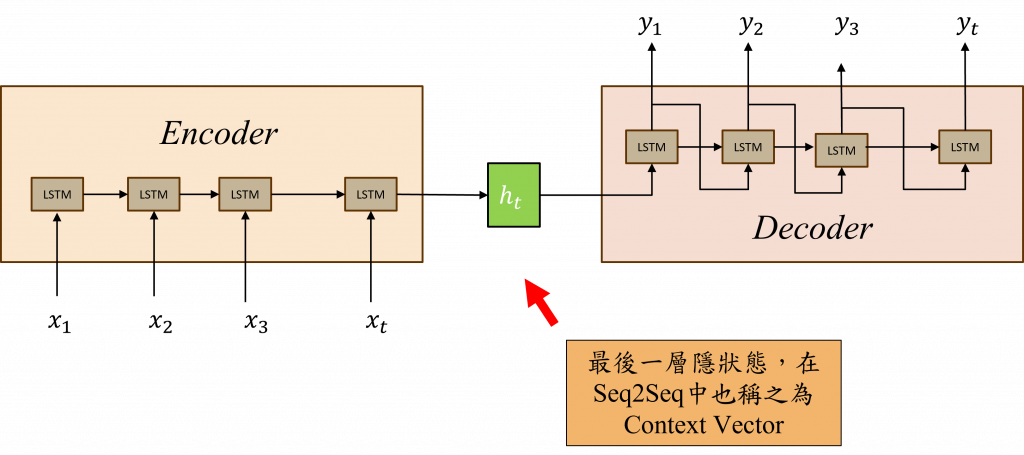
Seq2Seq(序列到序列)是由Google的研究團隊於2014年開發的模型架構,其目的在於解決先前的DNN模型(包括LSTM、RNN)在輸入和輸出都是固定維度的問題,因在大多數的機器翻譯、文本摘要、語音辨識任務中,輸入與輸出都是不固定的,因此該模型的出現使自然語言處理領域取得了重大突破。
Seq2Seq模型由兩個部分組成:Encoder(編碼器)和Decoder(解碼器),這兩者的主要運作方式是透過時間序列模型進行組合與運算而成,接下來我將分別解釋這兩個部件的架構,讓你更清楚地理解他們各自的工作原理。
Encoder(編碼器)的功能與我們昨日執行的行動類似,即透過時間序列模型來理解文字間的前後文關係,在Seq2Seq模型中,Encoder的最終狀態h(t)反映了模型對資料分布的狀況,因此也被稱作上下文向量(Context Vector)。整個步驟的核心目的在於將文字分布的訊息傳遞至Decoder,以產生新的目標序列。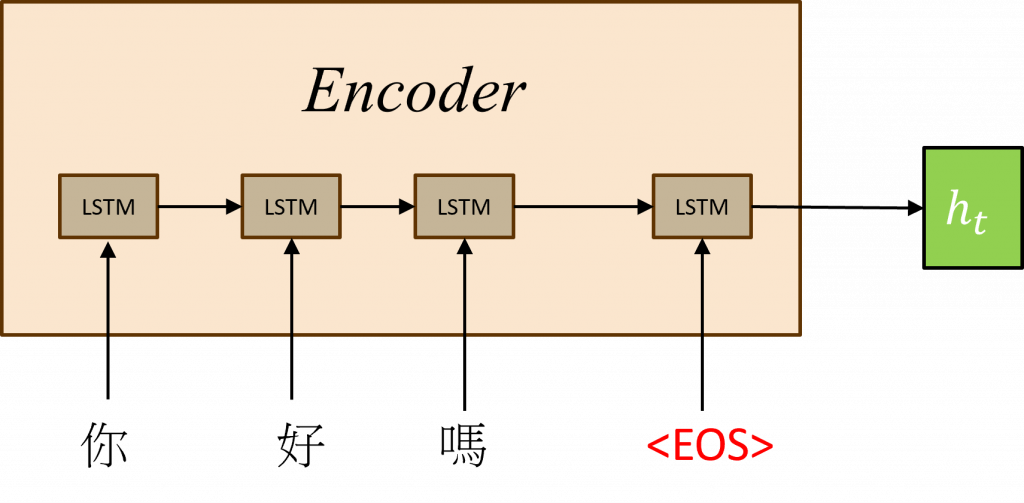
在Encoder的階段運用了一些特殊的技術,來幫助模型更有效地將上下文向量傳遞到Decoder中,首先我們需設定輸入序列的最後一個符號為<EOS>(End of Sequence),這個策略的目的是使模型能在所有可能的序列長度中,瞭解其分布狀態。
這是因為在Decoder生成步驟中,是無法識別文字之間的長度的,所以在Encoder階段,我們讓模型學習何時能結束文字,這樣模型在Decoder階段便能做出判斷。
第二招則是逆向訓練文字,經過實驗結果表明將文字反向輸入至Encoder,效果會顯著提升,作者對此的解釋是因為RNN、LSTM、GRU等時間序列模型,並未能完美解決長時間序列的問題,因此這種訓練方式能讓模型的第一個輸入與第一個輸出更緊密地結合在一起。
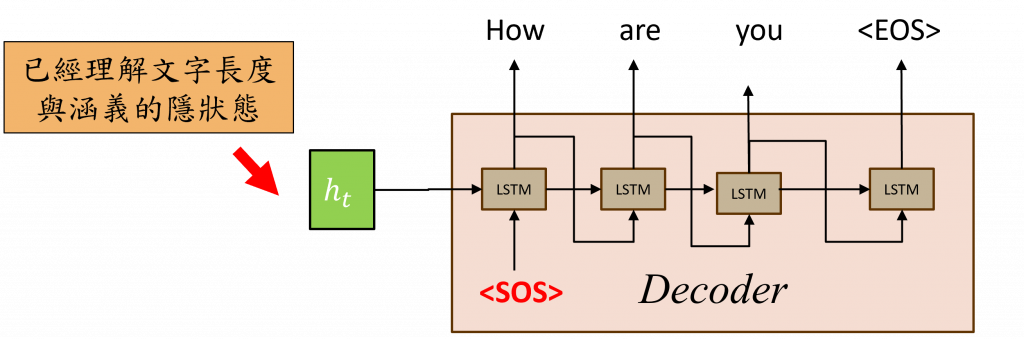
在Seq2Seq架構中,Decoder(解碼器)的角色是產生目標序列,這個生成過程會先將Encoder的上下文向量傳遞給Decoder的作為它的初始隱狀態,然後再配上<SOS>(Start of Sequence)來進行運算以計算出下一個文字,隨後不斷地將該文字與Decoder中的隱狀態hd(t)進行運算,直到產出<EOS>(序列結束標誌)時才停止。
這樣的說明可能比較抽象,我們可以從Decoder的生成公式來看(以下hat表示Decoder向量,並以LSTM為例):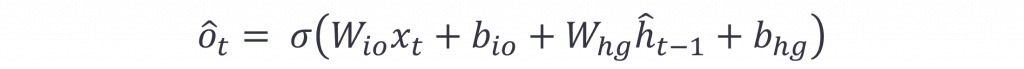
在這個公式中我們看到LSTM的時間序列輸出o(t),是由Decoder的x(t)與hd(t)運算出來的,並且該狀態的 hd(0)會等同於Encoder的h(t),這時我們就能取得每一層神經元的輸出結果。但是我們還需要從這些結果中運算出最可能的文字,因此我們可以用以下公式來表示每個時間序列輸出的文字:
如此一來我們就能夠從每一個神經元的輸出機率中選出機率最高的元素作為當前時間步的輸出,並且將此結果在與下一個時間步進行運算,已達到機器翻譯、文本摘要、語音辨識等效果。
在我們前面的內容中,我們提到一個深度學習模型除了輸入文字外,也要有對應的標籤,而這種方式稱之為監督式學習(Supervised learning),那麼在機器翻譯的過程中,我們如何做到這一步呢?
在Seq2Seq最常用的方法稱為Teacher Forcing(教師強迫),其運作方式就是在訓練階段時使用真實目標序列的元素作為Decoder的輸入,而非使用上一個時間步(上一個文字)的資料。
在這個做法主要包含兩個階段,分別為訓練階段與推理(inference)階段,以下我將會快速的告訴你這兩個步驟的目的。
在訓練期間的每個時間步驟,Decoder的輸入會被設定為實際的目標序列元素,例如:對於機器翻譯,我們會將待翻譯的目標文字設為輸入,並將其翻譯後的文字設為標籤,這樣做的用意是,當Decoder在每一步都知道自己應該產生什麼時,就能夠讓模型更快地學習目標序列的結構和模式。
在模型訓練完成後,由於帶有先前目標序列元素的記憶,因此在產生新的序列時,Decoder不需要依賴真實的目標序列了,這時它會運用在訓練期間所獲得的知識來推理出新的序列,這時Decoder在產生每個時間步的輸出時,才會依賴前一個時間步產生的結果進行推理,而這種方式也被稱為貪婪解碼(Greedy Decoding)。
但Seq2Seq架構中仍存在一些缺點,產生問題的部分原因是其核心架構採用的是時間序列模型進行運算,因此當處理長序列時,我們可能會遇到梯度消失或梯度爆炸的問題,這也導致計算速度較慢。
並且在該架構中,Encoder與Decoder之間僅仰賴一個上下文向量傳遞資訊,所以Decoder只會獲得Encoder學習過的特徵,並忽視掉原始輸入特徵,這種特性使得訓練Seq2Seq需要大量的數據,而且如果採用貪心解碼策略,還會使得生成的序列並非全域的最佳解,僅是局部的最佳解。
小提示:
若要解出一個全域最優解,我們必須考慮整體的合理性,就像遊樂園一樣,如果我們憑著最短的路徑選擇每個遊樂設施,可能會因為排隊的時間而導致總消耗時間更長,同理使用貪婪解碼方案時,我們只考慮每次機率最高的文字,而並非組合最合理的文字。
今天我們學習了Seq2Seq這項經典架構,很多強大的後續模型都源自於它的改良,因此Seq2Seq在自然語言處理中相當於基石的角色。但從現在的觀點看來,Seq2Seq存在許多問題,其中最嚴重的就是它只依靠一個上下文向量來傳遞資訊。因此,明天我會教你們另一項重要技術稱注意力機制(Attention)。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽