今天的內容非常的重要,因為模型訓練與評估的方式,直接影響到了模型最終的效能,我們在【Day 6】深度神經網路該怎麼改變Embedding向量(下)-PyTorch訓練的策略和方法的作法只不過是最基礎的用法而已,而今天我將會告訴你最完整最有用的訓練方式,而這種方式也被廣泛運用於AI的比賽,今日的學習重點如下:
亂數種子(Random seed)的重要性過度擬合(Over fitting)與欠擬合(under fitting)對模型的影響首先讓我們回顧一下前幾天的文章,我相信有認真閱讀的讀者,對這部分已有所理解,但我們還是做個快速複習來回顧相關重點,你也可以趁這個時候看看還有那些知識是被遺漏的。在【Day 2】和【Day 3】的文章裡,我們探討了如何讓電腦理解人類的文字,並透過詞嵌入層進行解析。而【Day 5】和【Day 6】則展示了模型如何調整這些詞嵌入層。到了【Day 7】,我們學習了如何利用時間序列理解文字的前後文關係。
在這些文章中,我都用正面與負面這兩種情緒的例子來展示詞嵌入層的向量空間。這樣的設計就是為了銜接今日的主題:電腦如何從文字中理解情緒,透過先前這些學習你應該已經明白,相近的詞彙其向量空間也會相近,所以我們在先前訓練結果中也可以看到正負情緒被很好的區分出來,但這次我們的訓練目標是一段完整的句子,因此我們還需要考慮文字之間的前後關係,而今天我主要會將這部分拆成以下幾步,並告知你每一個步驟該知道的知識點。
這次我們會使用在自然語言處理領域中極為熱門的IMDB情緒分析資料集,這個資料集是從IMDB網站上抽取的電影評論並以正面(positive)或負面(negative)的方式進行標註而成。該資料集包含50,000條電影評論,其中25,000條用於訓練(Train),另外的25,000條則分配給測試(Test)使用。
今天我們將透過這個資料集模擬自然語言處理時,最可能使用的數據儲存方式 - CSV檔案,而取得該資料的方式我們可以前往Kaggle進行下載。
當我們進入Kaggle網站後,先點擊【Data Card】選項,然後將頁面往下滑,這時我們就可以看到該檔案的下載按鈕(如下圖),當我們檔案下載完畢只需要將該資料存入程式資料夾中即可。
在取得資料集後,我們需要安裝一個名為Pandas的函式庫,該函式庫能夠幫助我們快速讀取CSV檔案,並且該CSV檔案並未幫我們分割訓練集(Train Dataset)及驗證集(Valid Dataset),所以還需要另一個名為sklearn的函式庫,以協助我們快速切割資料集,而我個人會在訓練時觀看訓練的進度,因此還會額外安裝一個名為tqdm的函式庫,以上三個函式庫我們可以透過pip指令進行安裝。
小提示:
在深度學習的訓練中,我們通常將資料分為訓練、驗證、和測試三個部分,如果我們面對的是一個尚未被切割的資料集,通常會先將其劃分為訓練和驗證兩部分,用以評估模型的表現,接著再利用實際的測試資料進行二次評估。而在AI比賽中,測試集通常是不會有標籤資料的,所以我們只能通過訓練與驗證來尋找最佳的模型,然後對測試集進行模型推理,以繳交最終的答案。
pip install pandas
pip install scikit-learn
pip install tqdm
今天我們將使用九個函式庫進行深度學習的運算,其中包含兩個我們以前未曾提及的函式庫,即numpy及collections。numpy是Python中一個極其重要的array(矩陣)操作函式庫,其主要目的是讓Python能透過矩陣來進行高效的運算;而collections是Python內建的高階函式庫,在我們後續的內容中,它將幫助我們計算詞彙的出現次數。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
import matplotlib.pyplot as plt
import random
from torch.nn.utils.rnn import pad_sequence
from sklearn.model_selection import train_test_split
from collections import Counter
from torchtext.vocab import vocab
from torchtext.data.utils import get_tokenizer
在深度學習的模型中,由於初始權重是隨機產生,並且運算結果也會採用一些隨機的方式,這都能夠為模型增加隨機性以此提升訓練效果。然而這種方式的一個副作用是使我們在訓練過程中難以確切理解問題所在,例如:在比較模型的效能優劣時,不同的亂數種子導致每次訓練的結果都不一樣,這就使我們難以進行有效的比較,所以我們可以通過以下程式將Python中的亂數種子固定住,使我們能比較RNN、LSTM、GRU之間的效能差距。
def set_seeds(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
set_seeds(2526)
接下來我們通過Pandas函式庫中的read_csv()讀取IMDB資料集中的檔案內容,該函數會將csv檔案轉換成一個DataFrame類別,使其能夠進行計算資料關聯性、取得某一欄(column)、取得某一列(row)...等多樣性的功能。
df = pd.read_csv('IMDB Dataset.csv')
reviews = df['review'].values
sentiments = df['sentiment'].values
在上述程式中,我們先通過欄位名稱作為索引來獲取相對應的資料,如【reviews】代表著在IMDB影評資料集中的文字訊息,而【sentiment】則表示該資料集的情緒標籤,同時我們也通過values功能將其從DataFrame類別轉換成array型態,以便後續的運算操作。
接下來,我們利用TorchText中的get_tokenizer()作為文本標記器,這個標記器的索引值與詞彙資料都是由TorchText預先定義的。
tokenizer = get_tokenizer('basic_english')
當我們有了標記器後,就可以開始計算這些文字的出現次數,這麼做的原因是因為若某個文字的出現次數過少,調整該詞彙向量時的難度就會提高,並起與其他較常見詞彙相比,其前後文的訊息相對匱乏讓向量調整錯誤,並且這種操作也會增加模型計算的複雜度,所以在這裡我們應該直接將這些低頻詞彙替換成<unk>,以確保保留一定訊息量的同時進行訓練。
counter = Counter()
for review in reviews:
token = tokenizer(review)
counter.update(token)
token_vocab = vocab(counter, min_freq=10, specials=('<pad>', '<unk>'))
token_vocab.set_default_index(token_vocab.get_stoi()['<unk>'])
在以上程式中,我們先通過了剛創立的標記器來切割文字(尚未轉換成數字),接下來透過update()的方式來更新Counter()容器內該詞彙的出現次數,最後使用TorchText中的vocab()來將低於10次出現的詞彙給過濾掉,同時加入<pad>、<unk>這兩個特殊標籤,然而我們需要注意我們要將<unk>的索引設定為預設值,不然程式將會出現錯誤,並且不會有有任何的提示。
小提示:
在這個步驟中,你可以把它想像為我們之前使用的tokenizer.py的功能,之前我們是使用split()來進行分割,然後用tokenizer()進行初始化;但在這裡,我們則是直接使用tokenizer()進行分割,然後再透過vocab來初始化類別,為後續的轉換動作做好準備。
接下來我們就能夠進行轉換成數字與轉換張量的動作了,而在這裡我們需要注意,因今天會使用一個名為二元交叉熵損失(Binary Cross Entropy Loss)的損失函數來進行運算,而該公式需要讓輸出在0~1之間,因此我們需要將標籤轉換成float型態。
# 轉換詞彙
reviews_ids = [torch.tensor(token_vocab.lookup_indices(tokenizer(i))) for i in reviews]
# 轉換標籤
labels = (sentiments=='positive').astype('float32')
# 切割資料集
x_train, x_valid, y_train, y_valid = train_test_split(reviews_ids, labels, train_size=0.8, random_state=46, shuffle=False)
當資料都轉換完畢後,就能使用到sklearn中的train_test_split()進行切割了,在這裡我們採用了8:2比例進行切割,並且固定亂數結果,以確保每次程式的切割方式都相同。
在Pytorch訓練中,我們通常會遵循一個模式,該方式就是先將原始資料用Dataset類別進行包裝,然後賦予給DataLoader(),這樣做的好處是DataLoader()能將Dataset所包裝的數據分割成固定批量的大小,並且提供打亂和多進程的功能。
class IMDB(Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return len(self.x)
trainset = IMDB(x_train, y_train)
validset = IMDB(x_valid, y_valid)
在以上的程式碼中的主要操作是透過__len__函數獲取所有檔案的大小,並利用__getitem__函數將定量的資料進行迭代。
而我們需要做的事情就是將訓練數據和對應的標籤提供給這個類別,然後再將整個Dataset類別送入DataLoader()裡,接下來我們先看一下以下的部分程式碼:
train_loader = DataLoader(trainset, batch_size = 64, shuffle = True, num_workers = 0, pin_memory = True, collate_fn=collate_fn)
valid_loader = DataLoader(validset, batch_size = 64, shuffle = True, num_workers = 0, pin_memory = True, collate_fn=collate_fn)
在程式碼中,我們首先對已經初始化完畢的Dataset類別trainset與validset進行包裝,並設定批量大小為64,接下來確保數據被打亂,且這些批量大小的記憶體位址被固定,以便提升運算速度。
但是我們需要特別注意的一點是,在先前的幾次訓練中,我們提到訓練時每批數據的大小必須相等,然而我們先前的處理中並未對此作出調整,雖然我們可以從一開始就針對該文本資料的最大長度來進行填充,但這會使模型的計算量大增,這是因為計算最大長度以外,程式還需要排除<PAD>這一個索引。
因此我們需要修改DataLoader中的collate_fn函數,實際上collate_fn所做的事情非常簡單,它只是負責回傳Dataloader()中的批量資料,我們可以看到以下程式:
def collate_fn(batch):
return batch
所以我們可以將這些批量資料取出,並透過pad_sequence()的方式進行動態填充,從而提升計算速度。
def collate_fn(batch):
(x, y) = zip(*batch)
return pad_sequence(x, padding_value=PAD_IDX, batch_first=True), torch.tensor(y)
在模型初始化的部分,我們實際上是在之前做的詞嵌入層和深度神經網路之間插入了一層時間序列模型,在這裡為了便於通過修改參數來更換模型,我一次性地宣告了三個時間序列模型,並透過if...else語句來進行選擇。
class TimeSeriesModel(nn.Module):
def __init__(self, embedding_dim, hidden_size, num_layers=1, bidirectional=True, model_type = 'LSTM'):
super().__init__()
self.embedding = nn.Embedding(INPUT_DIM, embedding_dim, padding_idx = PAD_IDX)
if model_type == 'LSTM':
self.series_model =nn.LSTM(embedding_dim,
hidden_size = hidden_size,
num_layers = num_layers,
bidirectional = bidirectional,
batch_first=True
)
elif model_type =='GRU':
self.series_model =nn.GRU(embedding_dim,
hidden_size = hidden_size,
num_layers = num_layers,
bidirectional = bidirectional,
batch_first=True
)
else:
self.series_model =nn.RNN(embedding_dim,
hidden_size = hidden_size,
num_layers = num_layers,
bidirectional = bidirectional,
batch_first=True
)
hidden = hidden_size * 2 if bidirectional else hidden_size
self.fc = nn.Linear(hidden, 1)
self.sigmoid = nn.Sigmoid()
在以上的程式中可以發現,所有的時間序列模型中都有以下幾個參數:
| 參數名稱 | 說明 |
|---|---|
| hidden_size | 隱藏層數量 |
| num_layers | 指定要有幾個時間序列模型 |
| bidirectional | 是否要雙向計算 |
| batch_first | 批次量是否在第一維度 |
在該表格中,hidden_size代表每一層時間序列模型的隱藏層數量,num_layers則代表需要的時間序列模型層數。擁有這個參數後,我們就無需一直宣告模型的層數。
bidirectional和batch_first為我們的重點參數,當bidirectional=True時,意味著時間序列模型會先從左到右運算一次,再從右到左運算一次,使得hidden_size的數量變成兩倍,原因在於它考慮了兩個方向。
至於batch_first,在時間序列模型中,預設的輸入為(序列長度, 批量大小, 詞嵌入維度),若選擇batch_first=True,則變為(批量大小, 序列長度, 詞嵌入維度)。
根據上述的資料,我們可以定義前向傳播的流程。首先我們需要將時間序列模型計算完畢後的結果中的最後一個時間步提取出來,然後傳入到深度神經網路中,在模型的最後我們使用了self.sigmoid()函數,將結果縮放到0~1範圍內,以符合二元交叉熵損失的計算要求。
def forward(self, x):
emb_out = self.embedding(x)
out, (h, c) = self.series_model(emb_out)
x = out[:, -1, :]
x = self.fc(x)
return self.sigmoid(x)
最後我們將這些模型類別進行初始化並宣告優化器與損失函數,但在此過程中我們使用了特殊的方式來動態判別Pytorch是否有GPU環境,如果環境設定無誤,那麼Pytorch將會透過to()的方式將資料放入GPU中。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TimeSeriesModel(embedding_dim = 300, hidden_size= 128, model_type = 'RNN').to(device)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
在模型訓練的過程中,我們會使用到tqdm這個函式庫來顯示訓練進度,使用方式非常簡單,只需用tqdm()來包裝DataLoader()。
而模型的訓練方式則與先前相同,只不過增加了些準確率計算的部分,由於輸出值是介於0~1之間,所以我們用0.5作為分界,將0.5以上的輸出值視為標籤1,反之則為0。
def train(epoch):
train_loss, train_acc = 0, 0
train_pbar = tqdm(train_loader, position=0, leave=True) # 宣告進度條
model.train() # 將模型切換成訓練模式
for input_datas in train_pbar:
features, labels = [i.to(device) for i in input_datas] # 將資料放入到GPU中
optimizer.zero_grad() # 梯度清零
outputs = model(features).view(-1) # 模型計算答案(前向傳播)
loss = criterion(outputs, labels) # 計算Loss值
loss.backward() # 返向傳播
optimizer.step() # 更新模型權重
train_pbar.set_description(f'Train Epoch {epoch}') # 顯示訓練次數
train_pbar.set_postfix({'loss':f'{loss:.3f}'}) # 顯示當下模型損失
pred = outputs > 0.5
train_acc += sum(pred == labels) # 計算預測成功的數量
train_loss += loss.item() # 模型總損失
return train_loss/len(train_loader), train_acc/len(trainset) # 計算一次訓練的Loss與準確率
在模型驗證的部分,我們只需要將調整權重相關的程式區塊移除便可。而為了提升計算速度,我還使用了torch.no_grad()這個函數,該函數的功能是忽略梯度的追蹤,因此可以使計算速度更快。
def valid(epoch):
valid_loss, valid_acc = 0, 0
valid_pbar = tqdm(valid_loader, position=0, leave=True)
model.eval()
with torch.no_grad():
for input_datas in valid_pbar:
features, labels = [i.to(device) for i in input_datas]
outputs = model(features).view(-1)
loss = criterion(outputs, labels)
valid_pbar.set_description(f'Valid Epoch {epoch}')
valid_pbar.set_postfix({'loss':f'{loss:.3f}'})
pred = outputs > 0.5
valid_acc += sum(pred == labels)
valid_loss += loss.item()
return valid_loss/len(valid_loader), valid_acc/len(validset)
最後我們還要使用plot()繪製折線圖以觀看最後的結果,這樣子基本的函數都定義完畢了
def show_training_loss(loss_record):
train_loss, valid_loss = [i for i in loss_record.values()]
plt.plot(train_loss)
plt.plot(valid_loss)
#標題
plt.title('Result')
#y軸標籤
plt.ylabel('Loss')
#x軸標籤
plt.xlabel('Epoch')
#顯示折線的名稱
plt.legend(['train', 'valid'], loc='upper left')
#顯示折線圖
plt.show()
在我們完成訓練函數的定義後,我們就可以開始制定訓練策略,我最常用的策略是在每一步的模型訓練過程中儲存歷史最低的Loss值或準確率,並進行提前停止(Early Stopping)的操作。這種操作的主要目的在於,一旦模型進入過度擬合(Over fitting)的狀態,Loss曲線將開始上升,而模型很可能不會再有進一步的下降,原因是模型已經過度熟悉訓練資料,導致在處理未見過的資料時,其泛化能力降低。
epochs = 15 # 訓練次數
early_stopping = 7 # 模型訓練幾次沒進步就停止
stop_cnt = 0 # 計數模型是否有進步的計數器
model_path = 'model.ckpt' # 模型存放路徑
show_loss = True # 是否顯示訓練折線圖
best_acc = 0 # 最佳的準確率
loss_record = {'train':[], 'valid':[]} # 訓練紀錄
for epoch in range(epochs):
train_loss, train_acc = train(epoch)
valid_loss, valid_acc = valid(epoch)
loss_record['train'].append(train_loss)
loss_record['valid'].append(valid_loss)
# 儲存最佳的模型權重
if valid_acc > best_acc:
best_acc = valid_acc
torch.save(model.state_dict(), model_path)
print(f'Saving Model With Acc {best_acc:.5f}')
stop_cnt = 0
else:
stop_cnt+=1
# Early stopping
if stop_cnt == early_stopping:
output = "Model can't improve, stop training"
print('-' * (len(output)+2))
print(f'|{output}|')
print('-' * (len(output)+2))
break
print(f'Train Loss: {train_loss:.5f} Train Acc: {train_acc:.5f}', end='| ')
print(f'Valid Loss: {valid_loss:.5f} Valid Acc: {valid_acc:.5f}', end='| ')
print(f'Best Acc: {best_acc:.5f}', end='\n\n')
if show_loss:
show_training_loss(loss_record)
當以上程式執行完畢代表訓練結束,因此我們來比對一下三個模型的效能差異,並觀察三個訓練的曲線圖。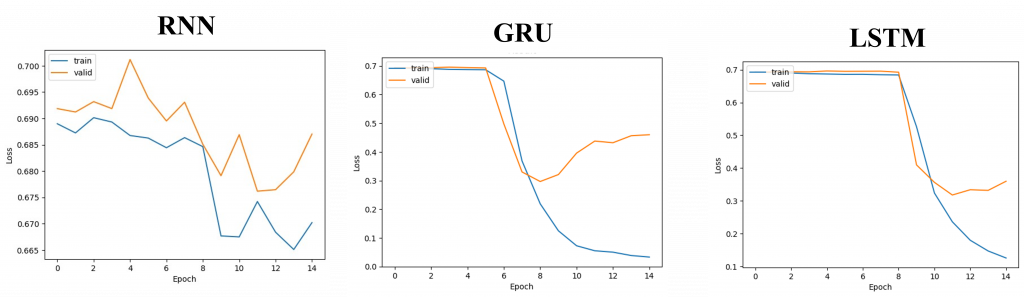
| 模型名稱 | 準確率 |
|---|---|
| RNN | 69.54% |
| LSTM | 88.04% |
| GRU | 88.71% |
| 在以上的結果中,我們可以發現GRU與LSTM在初期並未有太大的波動,這是因為如同我們昨天所學,這兩個演算法會進行較複雜的資料計算處理。因此在初期調整詞嵌入空間時的行為接近隨機向量,但經過一段時間的訓練後,這個神經網路學習到了資料句子的上下文關係,因而詞嵌入空間逐漸被訓練得更為準確使準確率開始提升。至於RNN就因其對長時間序列的適應性較差,我們可以發現其Loss值變動起伏並不大,也造成最終的精確率並不理想。 |
而這些模型到後面也都產生了過擬合的狀況,也就是驗證數集損失上升而訓練損失下降(反之則是欠擬合),這時我們可以考慮降低early_stopping參數的數值,使之能在損失上升後立即中斷訓練,以減少訓練次數。
在模型訓練時,我僅儲存了模型的權重,所以我們需要在將這些權重導入回來前,先重新建構該模型的初始值。因此我們需要先執行以下的程式碼:
model = LSTM(embedding_dim = 300, hidden_size= 128).to(device)
model.load_state_dict(torch.load(model_path))
model.eval()
在模型的應用上,由於我們在訓練時第一個維度是批量大小,因此我們需在第一軸增加維度,以還原模型的輸入。
label_decoding = {0:'negative', 1:'positive'}
text = x_valid[0].unsqueeze(0).to(device)
output = model(text)
pred = (output.view(-1) > 0.5)
label = y_valid.tolist()[0] # 取得Label
print('Pred Label:',label_decoding[int(pred)]) # 顯示文字
print('Real Label:',label_decoding[label]) # 顯示文字
print('Reivew:\n', " ".join(token_vocab.lookup_tokens(x_valid[0].tolist())))
這時我們就能夠看到模型的預測結果如下:
Pred Label: negative
Real Label: negative
Reivew:
first off i want to say that i lean liberal on the political scale and i found the movie offensive . i managed to watch the whole <unk> disgrace of a film . this movie brings a low to original ideas . yes it was original thus my 2 stars instead of 1 . are our film writers that uncreative that they can only come up with this ? ? acting was horrible , and the characters were unlikeable for the most part . the lead lady in the story had no good qualities at all . they made her <unk> into some sort of a bad guy and i did not see that at all . maybe i missed something , i do not know . he was the most down to earth , relevant character in the movie . i did not shell out any money for this garbage . i almost wish peta would come to the rescue of this awful , offensive movie and form a protest . disgusting thats all i have to say anymore !
可以看到在該句子中出現了如garbage、awful、disgrace等負面詞彙,因此在情緒分析上,這些詞的向量空間將更接近於負面的區域,所以系統將會將這結果判斷為負面情緒。
這次的程式碼內容較為龐大,可能會在學習過程中感到困難,然而這種訓練方式可以適用於大部分的模型,在AI比賽中,我們通常會變更亂數種子並進行多次訓練,以計算各模型的平均數值,從而使模型達到最大的效用。今天只是介紹了在自然語言處理中最基礎且有效的訓練方式,而明天我將開始教你如何擴展這些基本模型的結構。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽