"活躍資料序列" 是指那些仍然在接收新數據點或樣本的時間序列。當您停止向某個時間序列寫入新的資料點後,不久它就不再被認為是 "活躍的"。
Tempo 的 metrics generator 所產生的指標可以提供 RED(速率 / 錯誤 / 持續時間)指標,以及跟踪中各服務間的互相依賴關系圖表(即 Grafana 中的服務圖功能)。這些功能依賴於一組生成的跨度指標和服務指標。
任何被 Tempo 接收的跨度都可以創建許多指標序列。但這並不意味著每次接收到跨度時都會創建新的活躍資料序列。
生成的活躍資料序列的數量取決於從跨度數據生成並與指標關聯的標籤對,這與其他 Prometheus 格式的數據相似。
欲知更多詳情,請參考活躍數據序列和 DPM 的文檔。
當引入一個標籤鍵的新值時,某個指標的活躍資料序列會增加。例如,span_kind 標籤共有五個可能的值,status_code 標籤共有三個可能的值。
初看之下,您可能會假設這意味著每個跨度至少會生成 15(5*3)個活躍數據序列。但事實並非如此。
考慮從某個服務的一段程式碼中發出的跨度:
這是一個具有單一跨度的服務。如果跨度內的程式碼永遠不離開該服務,那麼由 metrics generator 生成的 span_kind 標籤將是 SPAN_KIND_INTERNAL,並且永遠不會偏離。它永遠不會是其他四個可能的值之一。
同樣,如果跨度內的程式碼從未出錯,它只會對 span_status 標籤有 STATUS_CODE_OK 狀態。這意味著 metrics generator 只會生成一個活躍數據序列,其中服務名稱將是 Service 1,跨度名稱將是 span1。如果我們查看 traces_spanmetrics_call_total 指標的 Prometheus 數據,我們會看到一個活躍數據序列:
| 服務 | 跨度名稱 | 跨度類型 | 狀態碼 | 指標值 |
|---|---|---|---|---|
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_OK | 1 |
無論該跨度在跟踪中出現多少次都沒關係,例如跨度可能在循環中生成。在執行一次的程式碼中,10 次、100 次、1000 次,只會產生一個活躍資料序列,其中計數器可能增加 1、10、100 或 1000 次: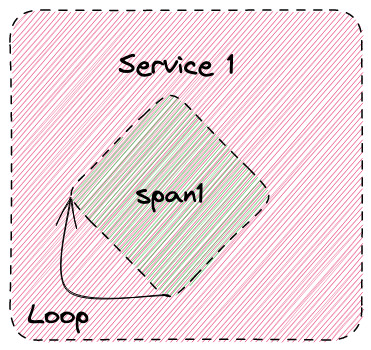
如果您查看 Prometheus 數據,您會看到 traces_spanmetrics_call_total 的即時值與表格類似。同樣,該指標有一個活躍資料序列:
| 服務 | 跨度名稱 | 跨度類型 | 狀態碼 | 指標值 |
|---|---|---|---|---|
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_OK | 120 |
但是,假設它確實循環,並且偶爾會出錯。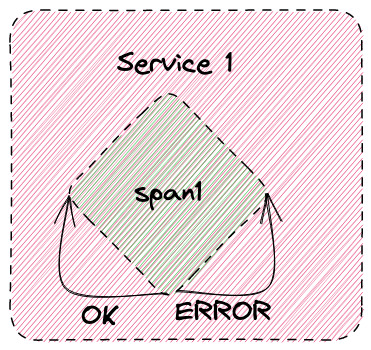
當程式碼循環時,跨度現在有兩種可能的結果:一種是一切都成功完成,另一種是出現錯誤。這意味著當跨度完成時,status_code 現在要麼是 STATUS_CODE_OK,要麼是 STATUS_CODE_ERROR。因此,基於 status_code,標籤值可以在度量上有兩個值,我們現在生成了兩個活躍的序列,一個是 OK 狀態,另一個是錯誤。
再次說明,我們可以循環一次、10 次、100 次或更多次,但只會有兩個活躍的序列。
如果我們現在查看 traces_spanmetrics_call_total 的 Prometheus 即時值,我們現在會看到以下表格:
| 服務 | 跨度名稱 | 跨度類型 | 狀態碼 | 指標值 |
|---|---|---|---|---|
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_OK | 96 |
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_ERROR | 24 |
但如果你呼叫另一個服務怎麼辦?讓我們添加一個選項,在此基礎上,根據一些任意數據,我們有時會對另一個服務進行下行呼叫,但否則繼續在我們自己的服務中運行循環: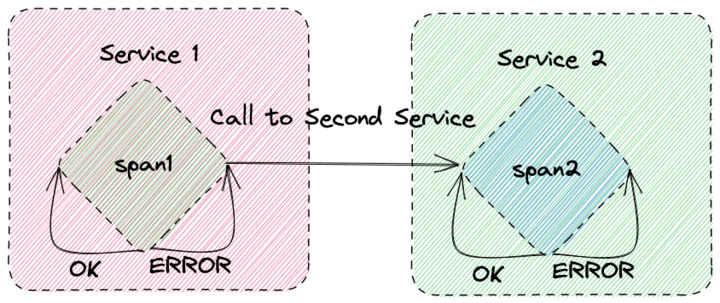
在這種情況下,span1 的 span_kind 標籤現在會是 SPAN_KIND_INTERNAL 或 SPAN_KIND_CLIENT(因為它已作為客戶端呼叫下行服務)。如果呼叫下行服務也可能失敗,那麼對於 SPAN_KIND_CLIENT,status_code 可以是STATUS_CODE_ERROR或 STATUS_CODE_OK。
此時,traces_spanmetrics_call_total 將有四種不同的標籤變化:
| 服務 | 跨度名稱 | 跨度類型 | 狀態碼 | 指標值 |
|---|---|---|---|---|
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_OK | 34 |
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_ERROR | 6 |
| Service 1 | span1 | SPAN_KIND_CLIENT | STATUS_CODE_OK | 23 |
| Service 1 | span1 | SPAN_KIND_CLIENT | STATUS_CODE_ERROR | 3 |
由於值的變化,我們的指標現在有四個活躍的序列,而不是一個。但就 Service 1 而言,仍然只有四個活躍的序列,因為標籤的值沒有其他變化。您可以運行 1 個跟踪、10 個跟踪、100 個跟踪(每個跟踪都有多少循環的跨度)和只有四個活躍的序列會被產生。
事實上,我們在上一個圖表中只講了一半的故事。Service 1 呼叫了第二個服務,Service 2,該服務通過添加一個新的跨度 span2 來繼續跟踪。如果 Service 2 內部有一個循環,該循環有一個由 Service 1 的上行呼叫生成的單一跨度,然後驅動內部的一些跨度,這些跨度也可能出錯,我們將在 traces_spanmetrics_call_total 的指標中得到可能的值:
| 服務 | 跨度名稱 | 跨度類型 | 狀態碼 | 指標值 |
|---|---|---|---|---|
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_OK | 89 |
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_ERROR | 13 |
| Service 1 | span1 | SPAN_KIND_CLIENT | STATUS_CODE_OK | 44 |
| Service 1 | span1 | SPAN_KIND_CLIENT | STATUS_CODE_ERROR | 9 |
| Service 1 | span1 | SPAN_KIND_SERVER | STATUS_CODE_OK | 30 |
| Service 1 | span1 | SPAN_KIND_SERVER | STATUS_CODE_ERROR | 14 |
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_OK | 99 |
| Service 1 | span1 | SPAN_KIND_INTERNAL | STATUS_CODE_ERROR | 23 |
此時,我們的所有跟踪都將由兩個潛在的跨度名稱組成,每個名稱都會產生兩種不同類型的 span_kind 和兩種不同類型的 status_code。所以對於一個指標,我們有八個活躍的序列。
每個潛在的跨度條件的值的可變性決定了在攝取跨度進行跟踪時,Tempo 所產生的活躍序列的數量,而不是看到的跨度的跟踪數量。
對於活躍的序列還有另一個考慮因素:可以從跨度的屬性上添加到指標的額外標籤鍵 / 值對。Tempo 的指標生成器允許用戶使用任意的跨度屬性來創建指標的標籤對。在考慮生成的活躍序列的數量時,您還需要確定轉換為標籤的跨度屬性有多少可能的值。
例如,如果您在指標標籤對中添加了一個 http.method 的跨度屬性,那麼有五個可能的值(因為有五種可能的 REST 方法):
HEAD
GET
POST
PUT
DELETE
如果這個標籤對被添加到每一個跨度指標上,那麼每個指標可能會生成另外 5 個活躍的序列(這極有可能是一個最糟糕的情境,很少有跨度會調用所有五個 REST 方法)。在上面的最後一個表格中,不是 8 個活躍的序列,而是 40 個(8 * 5)。
「Active series」描述的是時間序列中接收新數據點或樣本的序列。不同的標籤組合會產生不同的活躍序列。例如,當一個指標的標籤具有不同的值時,會生成多個活躍序列。Tempo 的指標生成器不僅可以基於基本的跨度資訊(如 span_kind 或 status_code)生成指標,還可以根據自定義的跨度屬性生成指標,這可能會顯著增加活躍序列的數量。
簡而言之,活躍序列為監控和分析系統提供了重要的視角,並且對於控制資源使用和成本也至關重要。

