2023 iThome 鐵人賽
分享至
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun
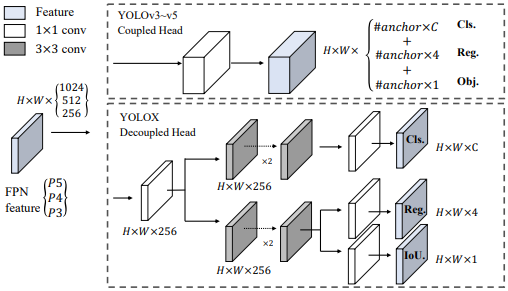
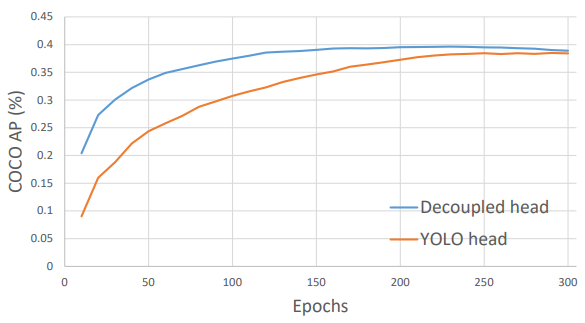
Decouple Head:
作者說明在物件偵測任務上,分類任務和回歸任務會產生衝突,會對收斂速度產生影響,因此作者將分類以及回歸任務分開做。
Anchor-Free:
Multi Positive:
SimOTA(Simple Optimal Transportation Assignment):
使用較強的影像擴增技術:
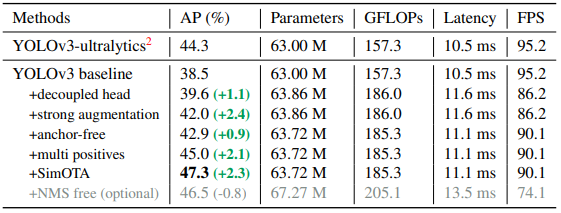
消融實驗:
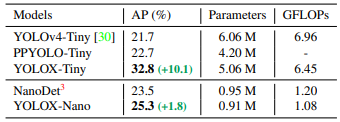
與其他方法比較:
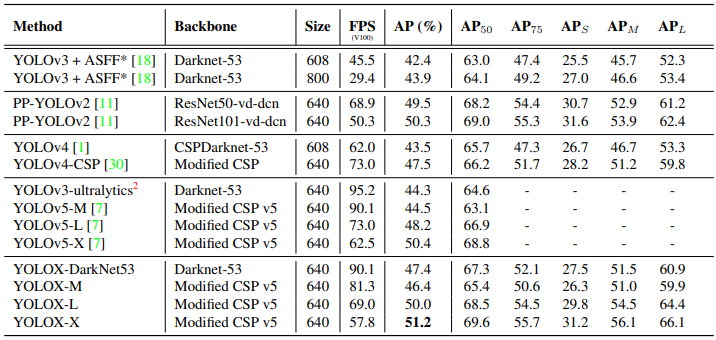
其他YOLO系列方法比較:
IT邦幫忙
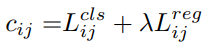 。
。