這幾天我整理了YOLOv1到YOLOv8的過程,期間我注意到使用的兩個資料集都按照YOLO的標註方式和資料集放置方式。因此只需將資料集複製到YOLO程式碼的資料夾中就可以進行訓練。然而,當蒐集到的標註格式不符合這種標準時,應該如何處理呢?今天我將分享一些有關標註檔案的前處理方法。
利用labelimg進行轉換格式:
開啟labelimg,點選Open Dir按鈕選擇資料集影像的位置,再點擊Change Save Dir,選擇Voc資料夾中的xml格式標註檔案資料夾位置。

點擊畫面左側Change Save Format按鈕,點擊直到出現YOLO圖示為止,並按Save按鈕,則會生成YOLO的txt格式標註檔案。

Python程式批次轉換:

#本程式碼將label從xml格式轉成txt格式
import copy
from lxml.etree import Element,SubElement,tostring,ElementTree
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir,getcwd
from os.path import join
#辨識的類別
classes=['scratch','paint_peel','rust','rivet_damage']
def convert(size,box):
dw=1./size[0]
dh=1./size[1]
x=(box[0]+box[1])/2.0
y=(box[2]+box[3])/2.0
w=box[1]-box[0]
h=box[3]-box[2]
x=x*dw
w=w*dw
y=y*dh
h=h*dh
return (x,y,w,h)
def convert_annotation(image_id):
#轉換前的標註檔案位置
in_file=open('./Annotations/%s.xml'%(image_id),encoding='UTF-8')
#轉換後的標註檔案位置
out_file=open('./TxtAnnotations/%s.txt'%(image_id),'w')
tree=ET.parse(in_file)
root=tree.getroot()
size=root.find('size')
w=int(size.find('width').text)
h=int(size.find('height').text)
for obj in root.iter('object'):
cls=obj.find('name').text
if cls not in classes:
continue
cls_id=classes.index(cls)
xmlbox=obj.find('bndbox')
b=(float(xmlbox.find('xmin').text),float(xmlbox.find('xmax').text),float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))
bb=convert((w,h),b)
out_file.write(str(cls_id)+" "+" ".join([str(a) for a in bb])+'\n')
#轉換前的標註檔案位置,這邊是要將要轉換的檔案名稱列出來
xml_path=os.path.join('./Annotations/')
img_xmls=os.listdir(xml_path)
for img_xml in img_xmls:
label_name=img_xml.split('.')[0]
#print(label_name)
convert_annotation(label_name)
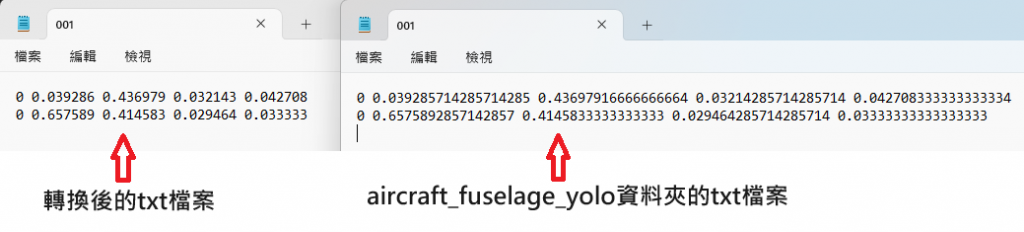
請問上述的語法能夠用在YOLO格式嗎
可以喔,yolo所需的標註檔為txt格式,有時網路上公開資料集會取得xml的標註格式,便可以利用此code將xml格式轉成txt格式,進而輸入至yolo model進行訓練。

